【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
【复现路径】
【遇到的问题:问题现象及影响】
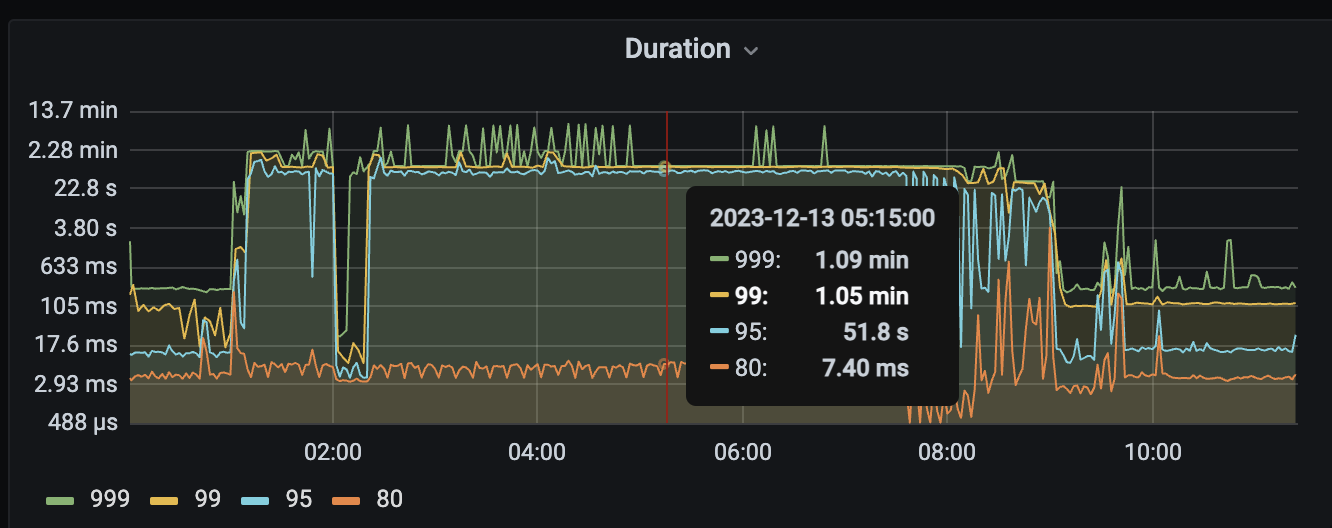
从 v5.1.4 升级至 v6.5.3 之后,凌晨的查询任务时延高,慢查询日志以及监控均发现 tikv 的 unified read pool CPU 吃满。但是并不是所有 tikv 都一起高,而是时不时某一台机器升高。
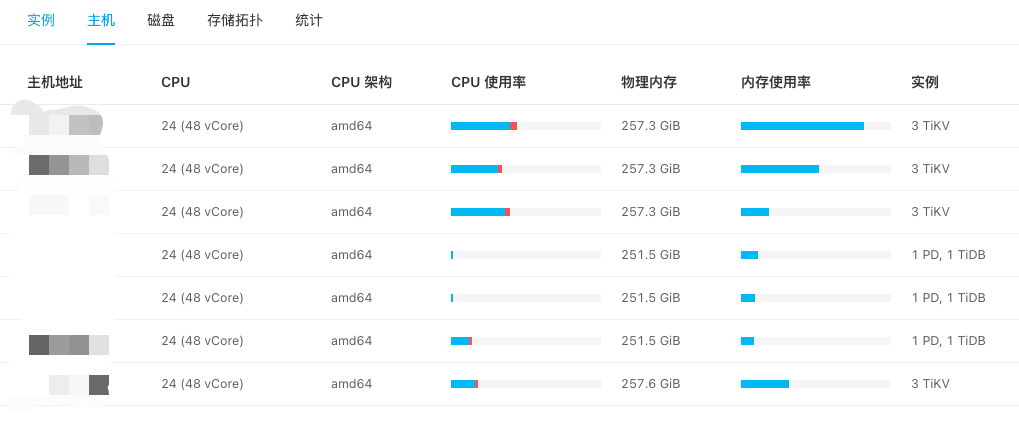
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
在重启 tikv ,先忽略资源使用情况
【附件:截图/日志/监控】
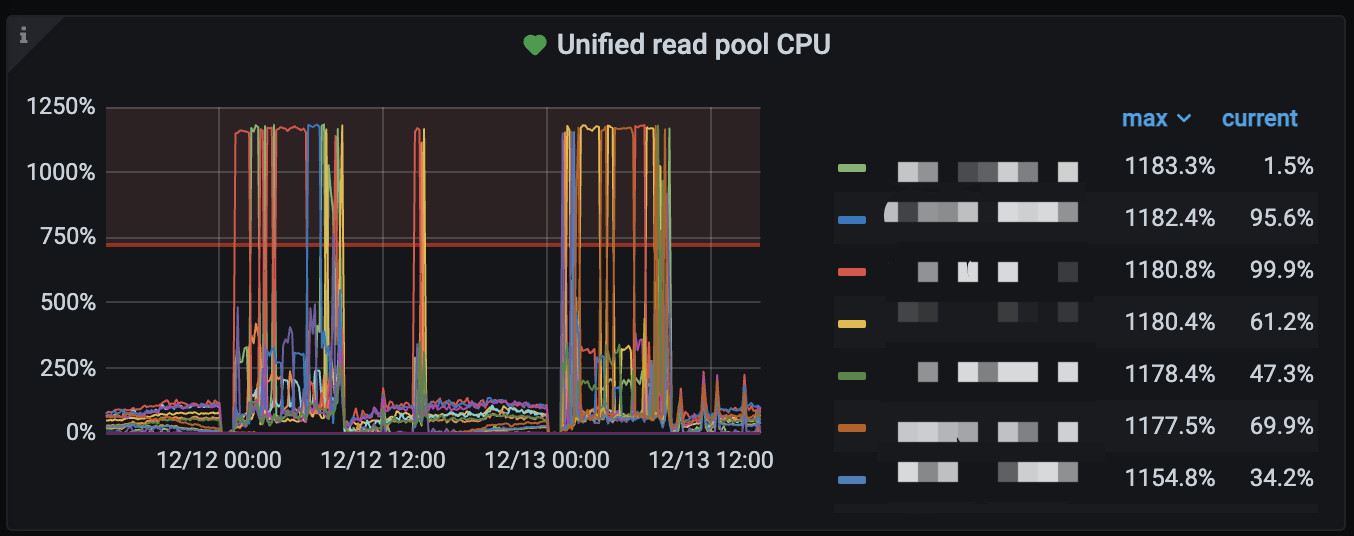
kv 节点轮流 CPU 高
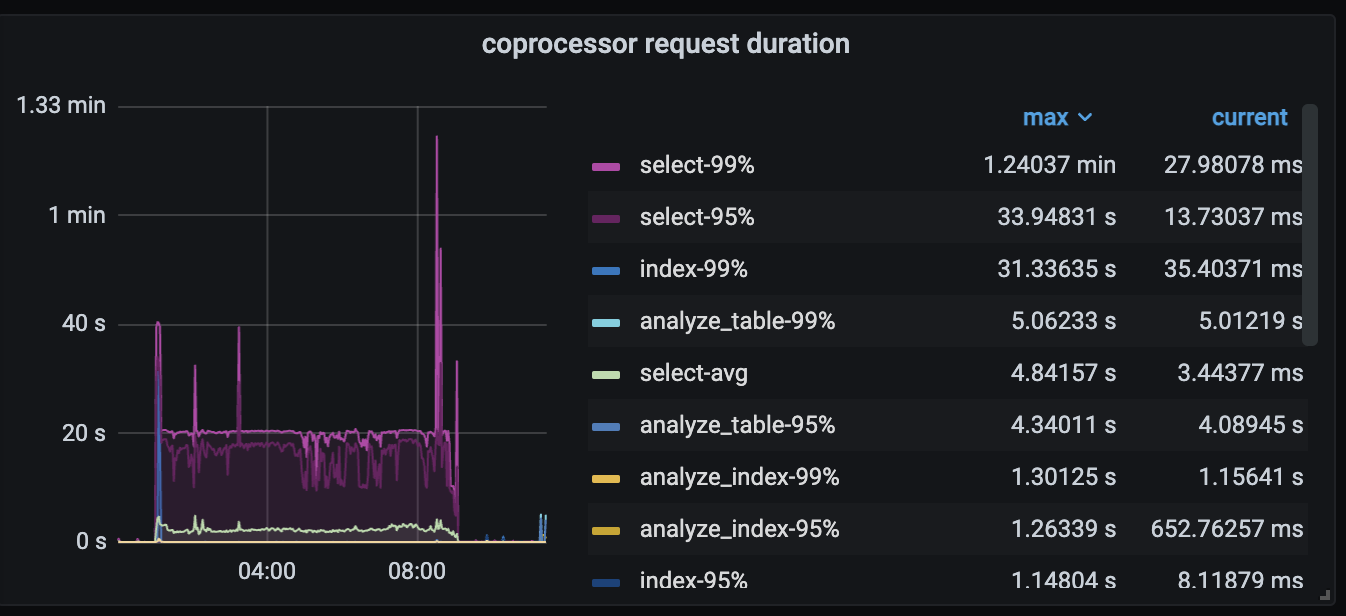
coprocessor
unified read pool 配置的 12 线程,也是全部吃满
SQL语句已经确认过执行计划是有走索引的。工作时间执行就很快返回,但是在凌晨跑任务的时候就会卡很久。analyze table 已经在 1213 执行过,也在 1213 的时候 reload 了 tikv ,看看 1214 凌晨有无效果。
WalterWj
(王军 - PingCAP)
2
dashboard 打开 top SQL,然后去那段时间看下这个节点的 top SQL 是啥。看起来是读热点。
2 个赞
dba远航
(Ti D Ber M Lo7 Bqhk)
5
查看一下TIKV的LEADER,应该是不均衡,或者存在查询的热点导致
饭光小团
6
ps : 我和题主是一个部门的。昨晚我们开启了readpool.unified.auto-adjust-pool-size 这个开关,性能好很多。 分析上 猜测是因为 SQL 基本都是并发 相同的SQL : SELECT t1.id, t1.ber, t1.type FROM ber AS t1 WHERE (t1.id > 6379887) ORDER BY t1.id LIMIT 1000; 所以应该都会跑到相同的kv上去执行。所以有热点的问题。今天在设置 Follower Read 看下能否缓解
有猫万事足
7
tidb7.5。
我在一个1.8亿的分区表上试了一下
WHERE (t1 .id > 6379887) ORDER BY t1 .id LIMIT 1000
执行计划如上,速度挺快的。不应该会造成tikv大范围的扫描,进而导致unified read pool CPU 吃满。
我感觉你这个sql执行如果慢或者扫描数据多的话,搞不好还是执行计划有点问题。
饭光小团
8
单看执行计划一点问题没有。在出问题的时间段,我们看也是这个执行计划。
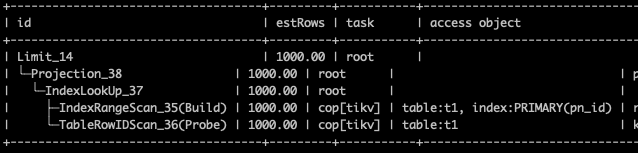
1 个赞
小龙虾爱大龙虾
(Minghao Ren)
9
不能随便猜测啊,去慢查询里,按问题时间点,找扫key多的sql
dgtgsou
(Neo)
11
大佬,打开这个参数readpool.unified.auto-adjust-pool-size和Follower Read,后面解决了吗?
感觉像缓存设置不足,看图形像持续去读取数据,不在缓存才回去频繁读
CC噶勒鸡
(Ti D Ber 0 I Fh E Gc Y)
13
如果是那种小region,然后热点读小region的时候也会造成这种问题吧
CC噶勒鸡
(Ti D Ber 0 I Fh E Gc Y)
14