【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.1.1
【复现路径】系统内存使用率高被系统杀掉后无法启动
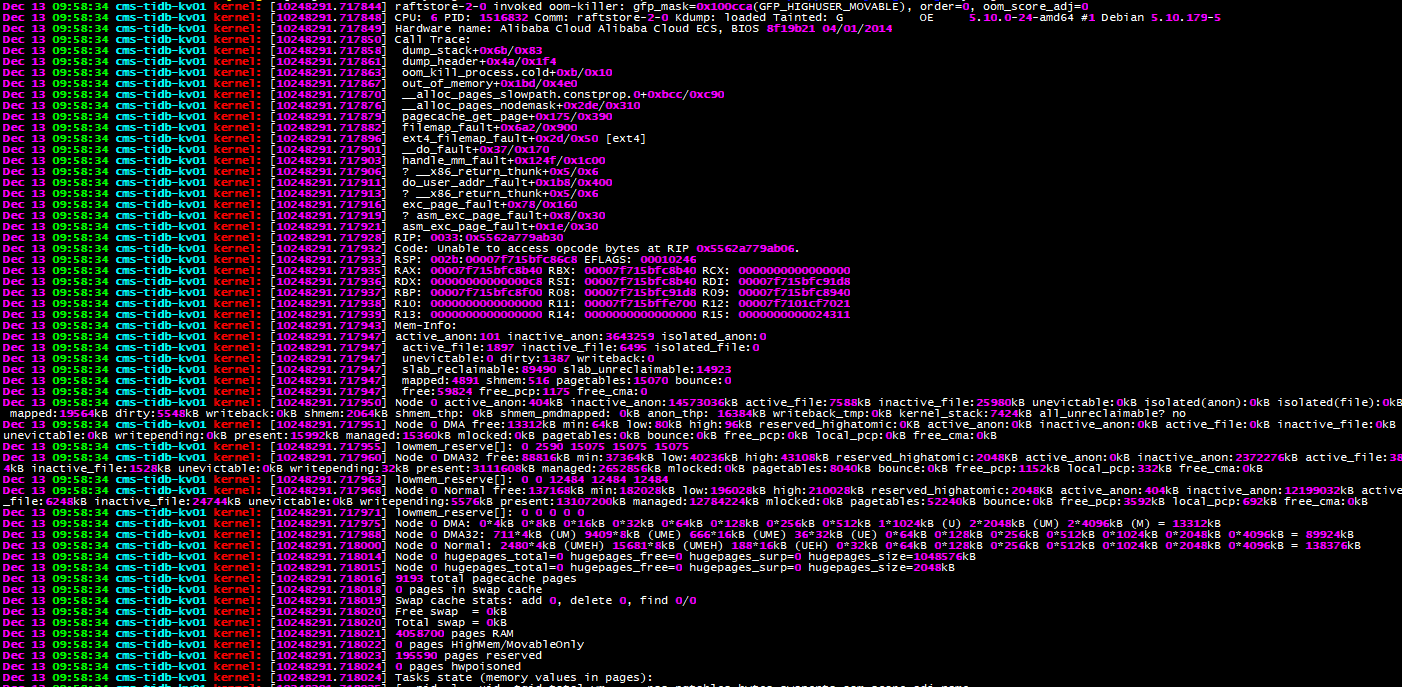
【遇到的问题:问题现象及影响】启动报 [FATAL] [setup.rs:309] [“invalid configuration: Cannot find raft data set.”]
3个kv节点,2个无法启动了
【资源配置】3个pd节点,4c8g;两个server节点 4c8g;3个kv节点,8c16g,500G ssd
【附件:截图/日志/监控】


3tikv个挂了俩,看下三板斧吧。。。专栏 - TiKV缩容下线异常处理的三板斧 | TiDB 社区
多谢!
大神好!kv节点启动出现 [2023/12/13 15:28:42.268 +08:00] [FATAL] [setup.rs:309] [“invalid configuration: Cannot find raft data set.”] 还能启动吗?
你现在怎么弄的?这个看着是配置出问题了,找不到raft文件了都。
咋搞成这样的 ![]()
1 个赞
就kv的进程退出了,重启进程就报这个错
现在3个kv都启动不了了。有数据文件能重新建一个集群进行恢复吗?
容器环境?
不是,云上
现在3个kv,都起不来,节点1报:
[2023/12/13 22:08:33.016 +08:00] [ERROR] [util.rs:682] [“connect failed”] [error=“Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: "Deadline Exceeded", details: [] }))”] [endpoints=http://172.16.27.211:2379]
[2023/12/13 22:08:33.021 +08:00] [FATAL] [setup.rs:309] [“invalid configuration: Cannot find raft data set.”]
节点2报:
[2023/12/13 22:06:43.282 +08:00] [ERROR] [util.rs:682] [“connect failed”] [error=“Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: "Deadline Exceeded", details: [] }))”] [endpoints=http://172.16.27.211:2379]
[2023/12/13 22:06:49.727 +08:00] [FATAL] [server.rs:921] [“failed to start node: Engine(Other("[components/raftstore/src/store/fsm/store.rs:1230]: \"[components/raftstore/src/store/entry_storage.rs:657]: [region 16] 17 validate state fail: Other(\\\"[components/raftstore/src/store/entry_storage.rs:472]: log at recorded commit index [12] 19 doesn’t exist, may lose data, region 16, raft state hard_state { term: 5 commit: 5 } last_index: 5, apply state applied_index: 19 commit_index: 19 commit_term: 12 truncated_state { index: 17 term: 11 }\\\")\""))”]
节点3报:
[2023/12/13 22:07:33.620 +08:00] [ERROR] [util.rs:682] [“connect failed”] [error=“Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: "Deadline Exceeded", details: [] }))”] [endpoints=http://172.16.27.211:2379]
[2023/12/13 22:07:42.971 +08:00] [FATAL] [server.rs:921] [“failed to start node: StoreTombstone("store is tombstone")”]
怎么感觉这都是pd连不上。所以起不来。
昨天按原配置搭了一套新的集群,启动正常,然后把旧集群pd、kv的数据文件复制到新集群下进行启动,发现这个方法行不通,同时旧集群也被新集群污染了,启动的时候发现新集群有到旧集群的连接,怀疑pd的数据文件里面记录了集群信息,此时关掉了新集群,发现旧集群有一个pd Down了,启动报错:
[2023/12/13 20:44:55.410 +08:00] [ERROR] [kv.go:295] [“fail to load safepoint from pd”] [error=“context deadline exceeded”]
[2023/12/13 20:44:55.528 +08:00] [ERROR] [pd_service_discovery.go:221] [“[pd] failed to update member”] [urls=“[http://172.16.26.212:2379,http://172.16.26.213:2379,http://172.16.27.211:2379]”] [error=“[PD:client:ErrClientGetMember]get member failed”]
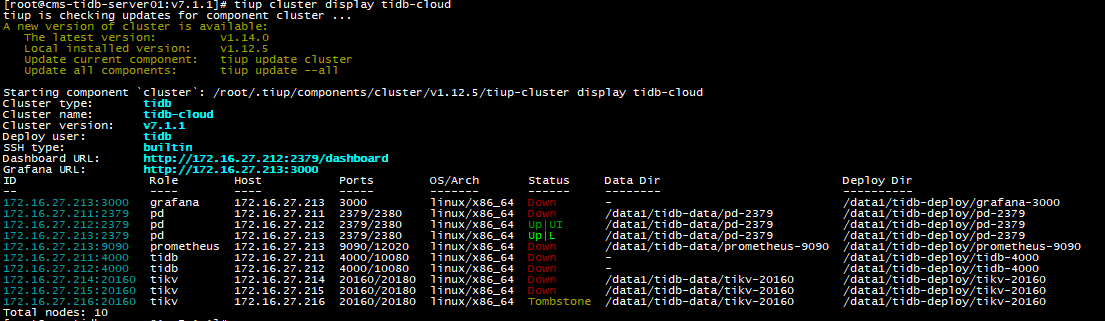
还能抢救吗?
原集群是 172.16.27.211-216,新集群是 172.16.26.211-216
你这个云环境看起来很不靠谱啊, 节点1,2的报错都是数据有丢失或损坏导致起不来,节点3tombstone是不是做缩容? 新集群拉起旧数据文件,好像还没人试过,何况你原来的数据文件已经不行了 ,即便搭新集群新集群的pd也要用pd-recover恢复cluster-id alloc-id才行
能详细讲讲这个吗?或者有资料也行,谢谢!
这套环境已经运行了很久了,之前从没出过什么问题。昨天早上突然down了一个kv,看系统日志是oom了,然后节点就起不来了,到中午又down了一个kv,也是oom,也同样起不来。
多谢大侠! ![]()
云环境竟然会IO损坏,太不靠谱了