magdb
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】7.1.1
【复现路径】
1、将 一个 tikv 节点正常关闭 (tiup cluster stop cluster -N 192.168.1.XXX:20160)
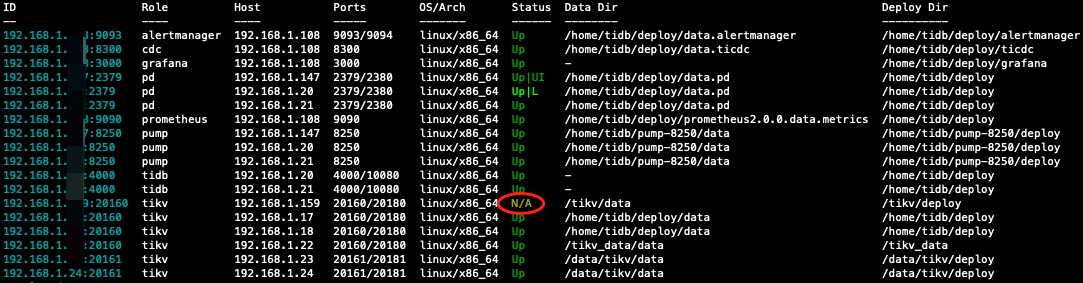
2、缩容该节点,缩容执行完成,但是节点状态显示为N/A
3、使用–force选项强制下线该节点,集群中该节点消失
4、检查其他tikv 节点日志,发现仍有尝试连接这个节点的报错Connection refused
【遇到的问题:问题现象及影响】
想请问一下怎么把这个报错从tikv 的日志中清理掉
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
缩容的标准操作是tiup scale-in,确认一下,你是使用的stop?
小龙虾爱大龙虾
(Minghao Ren)
3
为啥要强制缩容了呢,缩容前为啥要stop呢,你强制缩了就等着吧,等region补副本完事后就可以了
没有按照正常流程做缩容不需要stop,直接tiup scale-in就行了,不要乱用强制缩容–force会出问题,现在这个kv节点还能启动吗?
xfworld
(魔幻之翼)
5
试试这个
下线特殊处理
由于 TiKV,TiFlash 和 TiDB Binlog 组件的下线是异步的(需要先通过 API 执行移除操作)并且下线过程耗时较长(需要持续观察节点是否已经下线成功),所以对 TiKV,TiFlash 和 TiDB Binlog 组件做了特殊处理:
- 对 TiKV,TiFlash 及 TiDB Binlog 组件的操作:
- tiup-cluster 通过 API 将其下线后直接退出而不等待下线完成
- 执行
tiup cluster display 查看下线节点的状态,等待其状态变为 Tombstone
- 执行
tiup cluster prune 命令清理 Tombstone 节点,该命令会执行以下操作:
- 停止已经下线掉的节点的服务
- 清理已经下线掉的节点的相关数据文件
- 更新集群的拓扑,移除已经下线掉的节点
stop之后不是直接下线把,而是scale in后再清理
magdb
7
开始先把这个节点 stop,region 全部迁到其他节点之后再执行的scale-in
magdb
8
因为这个节点有点问题,开始决定先 stop 观察一下,region 已经全部迁移到其他节点了,过了一段时间之后才决定缩容,就没有启动,直接执行了 scale-in,执行完发现这个节点 status 变成了 N/A,后面用的-force,现在的情况是集群里这个节点已经没有了,pd 中也看不到 store,但是在其他节点的日志还能看到连接这个节点 
h5n1
(H5n1)
10
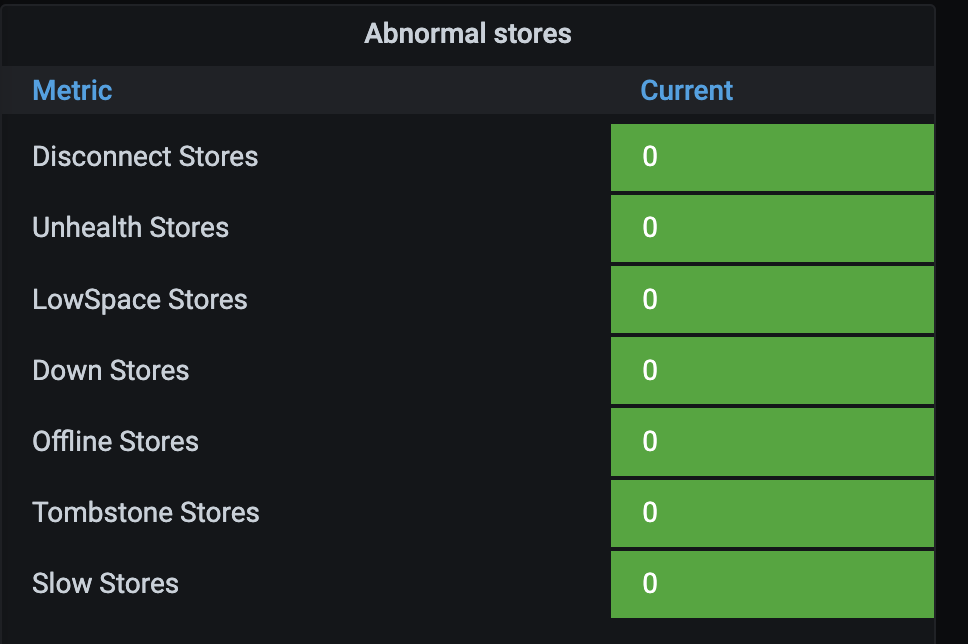
看下overview → PD → abnormal stores监控
使用 --force ,意味着不理会这个节点的内部下线状态变化、节点之间的注册联系等,粗暴地、强制直接把这个节点的目录和数据都抹掉,这个操作一般不轻易使用,一旦使用必须是在极端场景,否则容易出现各种未定义异常。以后要慎用它。
好的是你在强制抹掉它的数据之前,确认数据已经迁移走了,不会造成数据丢失。
其他节点还有他的信息,可以先确认有没有影响,没有影响的话一般问题不大,找个合适的时间窗口重启TiKV集群应该就可以清理掉这些信息了。稳妥一点在测试环境先模拟和验证是否可行。
h5n1
(H5n1)
14
pd-ctl region 然grep 看看有你下线的store没
magdb
15
没有记录下线节点的 store,请问还能通过什么方式查到吗,pd 里已经没有了 
system
(system)
关闭
17
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。