【 TiDB 使用环境】生产环境
【 TiDB 版本】V7.1.2
【复现路径】 在TIDB上执行analyze table XX
【遇到的问题:问题现象及影响】 单表容量2000万行左右,在TIDB上执行analyze table发现Unified Read Pool Cpu利用率能超过300%,感觉超级不符合预期,这种操作为何会消耗这么多的资源呢?
【资源配置】
TIKV单台服务器规格: 96C512G 4*8T,总计部署4个TIKV实例
TIKV定制化配置:
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 30
readpool.unified.min-thread-count: 5
【附件:截图/日志/监控】
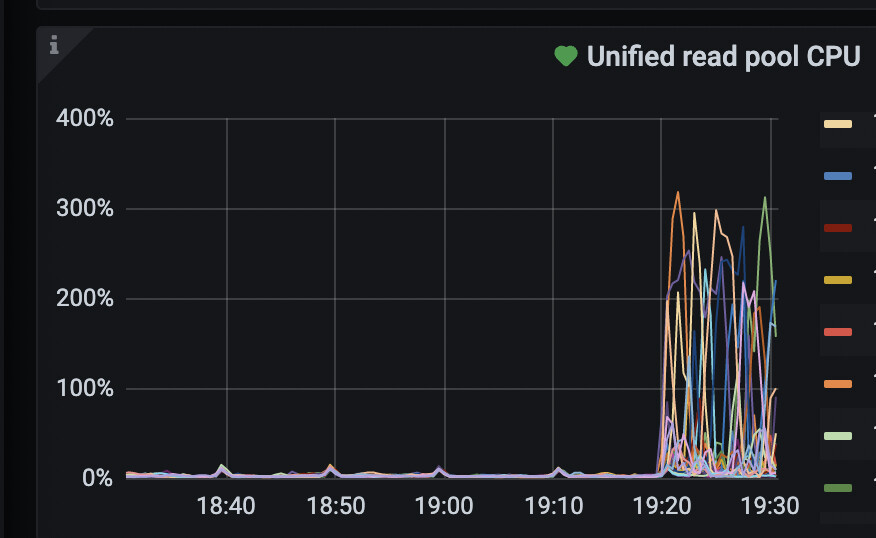
执行analyze 操作时会读取表数据进行统计信息分析和计算,这个过程如果表比较大,由于要从存储层读取大量数据,是会出现类似的情况的。
所以analyze时要避免业务高峰期,尽量在夜深人静的时候或者业务低谷时段才执行。
我其实想知道针对unified read pool 有没有相关的优化手段,线下调整了很多次多个参数了,感觉效果还是比较差
按理说不应该。优化的话,可以看看官方网站关于线程池的优化的章节,那里有介绍。通常不会有什么问题。
执行这个的时候,集群的延迟和访问QPS影响大吗
Unified Read Pool解决的是长短查询混合场景下,qps下降的问题。
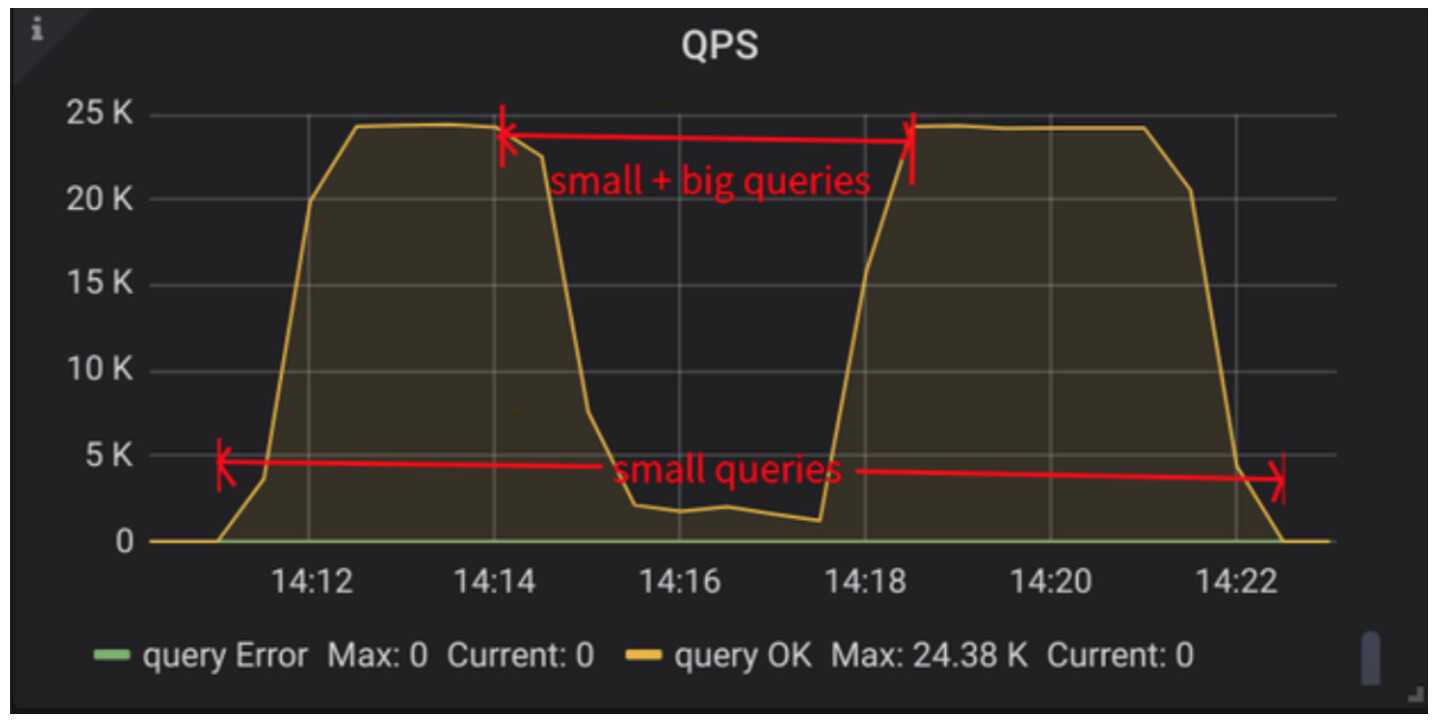
在analyze的时候,可以视为一个长查询,如果使用Unified Read Pool的情况下,如果造成了qps的猛降,像上面这个文章的里面的图一样是不符合预期的。
然后就是300%也只用了3个核吧。analyze的并发度有其他的参数控制。
https://docs.pingcap.com/zh/tidb/stable/statistics#控制-analyze-并发度
基本都在4到1之间,如果没有特别调整过其中的某几个,我感觉300%是个比较正常的值。
适当降低readpool.unified.max-thread-count的数值试试
正常吧,看下analyze并发相关参数,analyze本身就是带并发的
我先看一下这个文章,其实除了ANALYZE外,对于行检索比较多的SQL场景,Unified Read Pool负载也是非常高,感觉这块的设计确实有些让人难理解 ![]()