【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.3
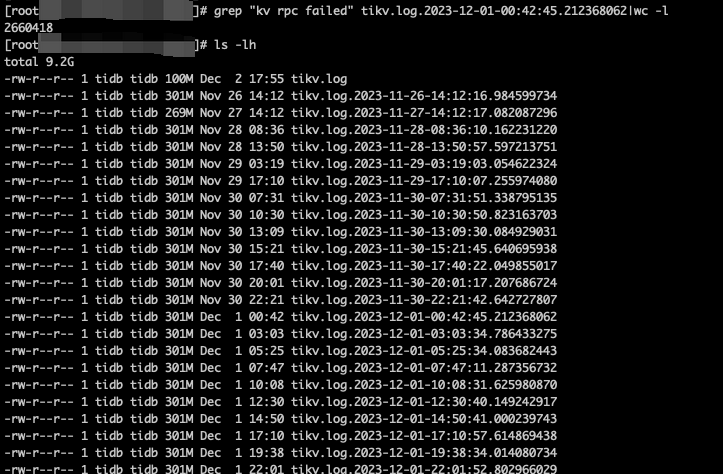
tikv的日志大量tikv的日志大量[“kv rpc failed”] [err=RemoteStopped]
[2023/12/01 15:59:48.895 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:48.895 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:48.895 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:48.954 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:48.954 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:48.954 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:48.954 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:49.023 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
[2023/12/01 15:59:49.023 +08:00] [INFO] [kv.rs:1023] [“kv rpc failed”] [err=RemoteStopped] [request=batch_commands]
请问这是什么原因?
但是一直报这个,每秒很多次,为什么一直报这个?能不能不让它报
1、Version:v5.3.0
2、所有tikv都是这样,单日多达10个文件,单个文件有2660418条这个日志
3、集群配置如下图
内存256 + 2块nvme盘
4、不知道有没有影响,就是想知道日志量为什么这么大?有没有隐藏风险?
5、当前主要用于juiceFS保存元数据,业务相对简单,region数:213955,tikv的总qps在100万左右
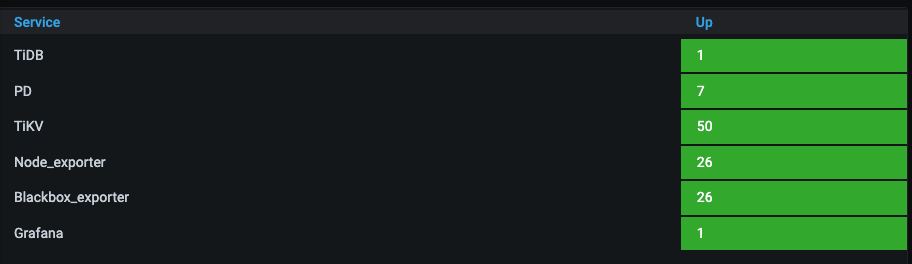
6、pd的从节点和tikv混部,pd主节点单独部署,128核Cpu,当前pd主节点的cpu使用率50%左右,7个pd是不是有点多?
1、从pd-master的主节点上看网络流量,和其它pd节点之间的网络流量就比较高了,我理解pd节点越多那么资源消耗越高,是不是对主节点的cpu资源也会有很大的消耗?现在cpu 50%,如果降低两个节点的话,是不是可以降低一些?业内大多数公司一般是配置多少个pd节点?还有一个问题就是,我们目前213955个region在128核心的pd-master就用了50%的cpu,随着region数据量越来越多,是不是这个主机的配置风险就会越来越高?我们应该怎么来优化处理?
2、这个“kv rpc failed”应该持续很长时间了,网卡Speed: 25000Mb/s,我看各节点间的网络是通的,这个期间我们也就是做了一个扩缩容的操作
3、region数量相对不是很平均,为了减少back off,我们的pd调度是在qps不是很高的情况下才开启
4、请问怎么查看region 的副本数是否达到了 设定的量?
xfworld
(魔幻之翼)
9
- region 的数量越多,会占用更多的资源
- cpu 资源
- 内存资源
- 网络资源
需要维持region 的心跳处理
- region 海量的处理是有参考文档的 (https://docs.pingcap.com/zh/tidb/stable/massive-regions-best-practices)
- 优先考虑查阅 region 的目前状态,来判断现在的副本信息,通过grafana 就可以了,查阅以下的参数
- region不平均会带来读写倾斜,有的kv 节点就特别忙,有的就十分空闲…
- 甚至会出现 大量的热点问题,这个通过pd 的dashboard 的界面可以查阅到了
优先检查 region,尽量做一些合并,减少 empty region 和 region 的数量… 这样可利用的资源会变多,效率也会变高
请参考!
1、请问213955个region算海量regoin吗?总数据量才不到14T,pd-master就用满了64C的cpu,这个合理吗?
2、所有region状态是ok的,也没有明显的热点读写
3、所有tikv的日志大量输出“kv rpc failed”的原因还是没有找到
xfworld
(魔幻之翼)
14
- region 的数量 和 PD 没有直接的关系,但是 region 的心跳信息会传递到 PD,需要 PD 做全局的控制和维护
- PD 64C 用满了,是持续用满,还是峰值用满?请按照 Client 接入使用的情况进行判断(最好将监控图一并放出)
- kv rpc failed, 请结合 PD 的日志进行查询,是否有其他的异常
根据提供的信息,也只能尝试帮你做一些判断和处理,请理解… 
1、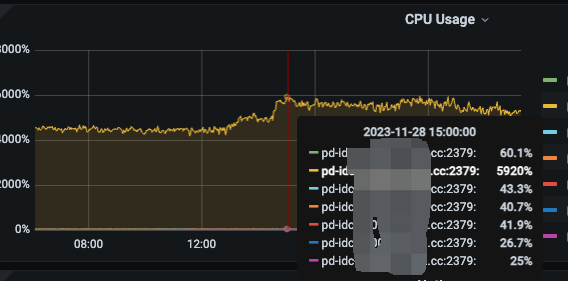
我们的读写访问量比较大,这个cpu的使用量,我也不知道是否正常?
2、这个参数目前来说可以不用调整,主机的配置还够
3、只用了一个tidb主要用于GC,实际读写都是raw kv
4、升级到5.3.4有坑吗?
1、cpu使用率在峰值有达到64c,一般保持在50c左右
3、pd存在大量read: connection reset by peer
节点之间互相网络访问正常不,有没有检查过不同角色的节点版本是否一致,业务访问上有没有出现异常状况
节点间访问是正常的,用tiup安装的版本应该都是一致的吧?业务没有明显的异常
WalterWj
(王军 - PingCAP)
20
我感觉是误报,日志级别是 info 的。
反馈区让研发看看吧,有影响 info 级别也不应该的。没影响打很多感觉也是有问题的。
1 个赞