版本v6.5.1
集群dashboard显示的 抓取的内存和IO 有部分机器有异常,怎么能看到prometheus 抓取的日志?
看了tidb-deploy/prometheus-9091/log下的日志prometheus.log 只有早上7点的记录,从今天早上7点到现在这段时间一直没有日志记录,配置文件中log-level: info
那不坏了吗
集群pd\tidb\tikv等监控数据一直都有GET回来
获取的日志在tidb-deploy/prometheus-9091/log
1.检查你的prometheus上,无日志接节点状态(UP)是否正常
2.如果不正常,检查agent状态(网络状态)
3.重启prometheus服务,观察是否正常
1 个赞
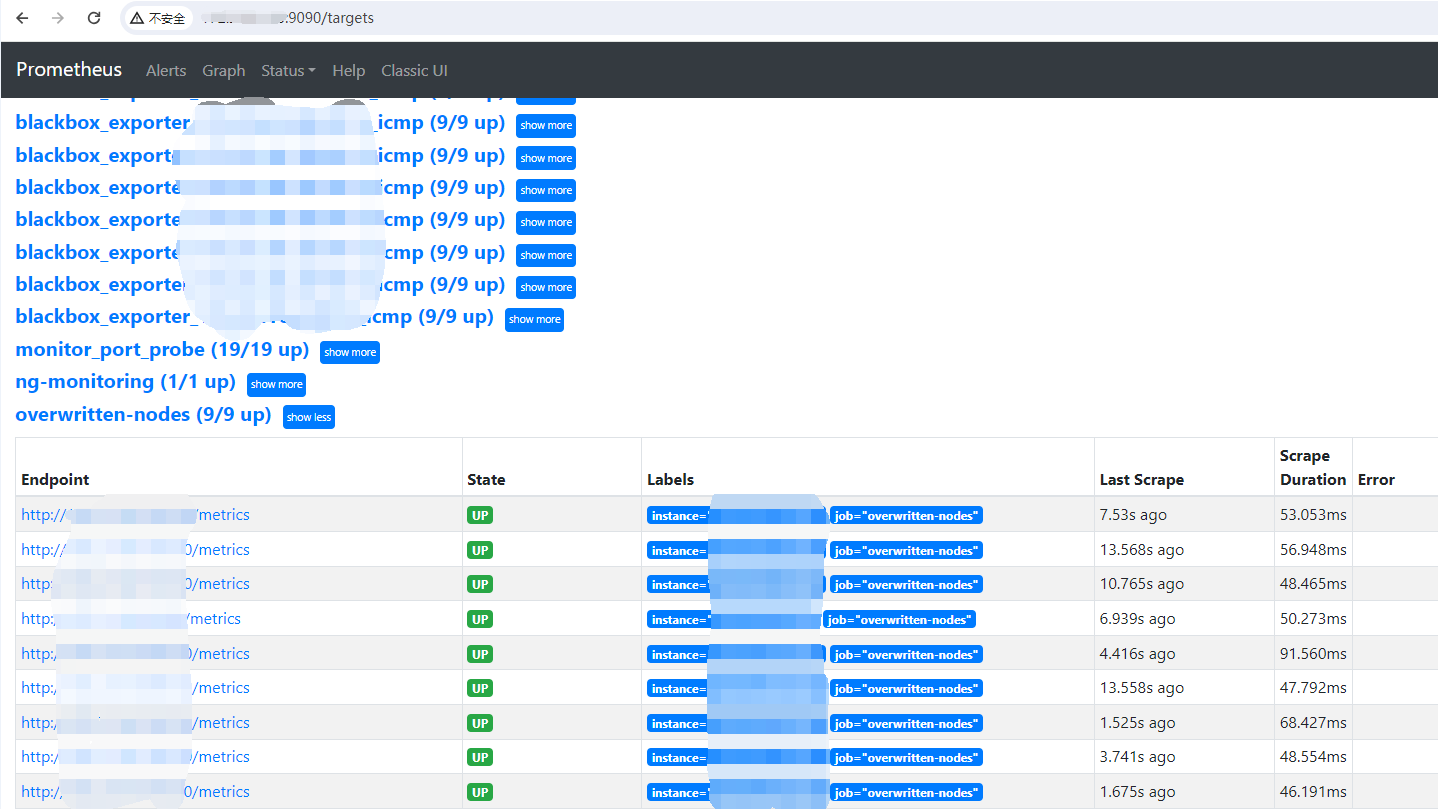
访问这个地址
http://{prometheus_ip}:9091/targets
可以看到每个targets上次抓取的间隔,和抓取的耗时。
估计某几个targets已经不能正常工作了。
前面的url可以尝试访问一下,看是否能正常返回监控值。
1 个赞
检查服务器跟其它服务器的通信情况,是不是抓取日志的问题
1、prometheus没抓取到数据的节点正常,无服务重启现象,内存最多使用到80%,CPU也有冗余,IO无异常
3、待改个参数试试重启
prometheus抓取其它机器监控数据正常
此机器与其它集群通信正常,无异常无告警,IO,CPU和内存 资源使用也未到极致
不过当前机器跑的SQL 时间超长,异常

promethues 本身有一个时序数据库,数据会存数据库里
数据存储在tsdb中
/data/tidb-data/prometheus-8249

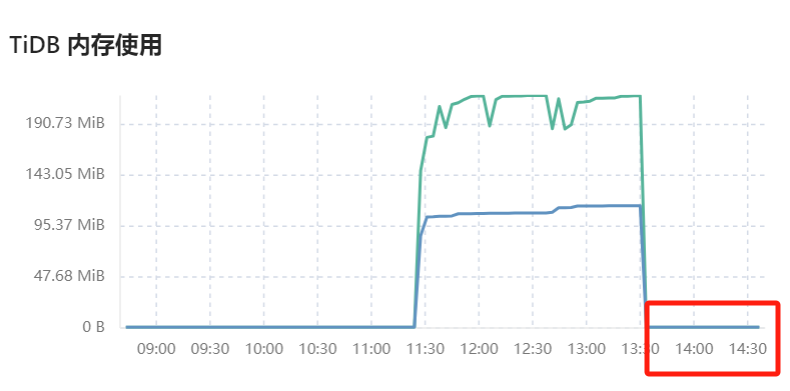
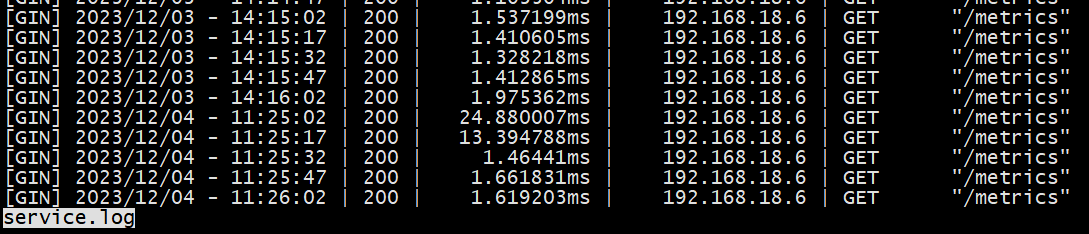
历史的问题,确实不知道怎么看。
这种没有的,应该就是没有采集到数据。
那个时刻target调用应该是失败的。
这么详细的记录是没有的,开销太大
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。