【 TiDB 使用环境】测试
【 TiDB 版本】V7.1.2
【复现路径】
T表 TS_DOCKPF_RECORD 数据量 :5581条 T1表 TS_DOCKPF 数据量 :22条
T表中 字段 RECORD_REQ和RECORD_RES 是longtext类型。每一条数据中这两个字段的存储的内容大概180kb左右。
执行如下sql :
EXPLAIN ANALYZE SELECT
T.DOCKPF_ID AS “fkByDockpfId.rid”,
T.BUS_TYPE AS busType,
T.RECORD_UID AS recordUid,
T.RECORD_REQ AS recordReq,
** T.RECORD_RES AS recordRes,**
T.DOCK_CONTENT AS dockContent,
T.RECORD_STATE AS recordState,
T.RECORD_TIME AS recordTime,
T.RID AS rid,
T.IF_DELETE AS ifDelete
FROM
TS_DOCKPF_RECORD T
LEFT JOIN TS_DOCKPF T1 ON T1.RID = T.DOCKPF_ID
WHERE
T1.UID = ‘78AA82AA0C01474C88238161234567890’
AND T.BUS_TYPE = 31
AND T.RECORD_STATE = 0
AND T.IF_DELETE = 0
ORDER BY
T.MODIFY_TIME ASC,
T.RID ASC
LIMIT
10;
执行耗时30s+
如果将查询结果字段中去掉两个大字段的查询
sql如下:
EXPLAIN ANALYZE SELECT
T.DOCKPF_ID AS “fkByDockpfId.rid”,
T.BUS_TYPE AS busType,
T.RECORD_UID AS recordUid,
T.DOCK_CONTENT AS dockContent,
T.RECORD_STATE AS recordState,
T.RECORD_TIME AS recordTime,
T.RID AS rid,
T.IF_DELETE AS ifDelete
FROM
TS_DOCKPF_RECORD T
LEFT JOIN TS_DOCKPF T1 ON T1.RID = T.DOCKPF_ID
WHERE
T1.UID = ‘78AA82AA0C01474C88238161234567890’
AND T.BUS_TYPE = 31
AND T.RECORD_STATE = 0
AND T.IF_DELETE = 0
ORDER BY
T.MODIFY_TIME ASC,
T.RID ASC
LIMIT
10;
执行耗时 30ms
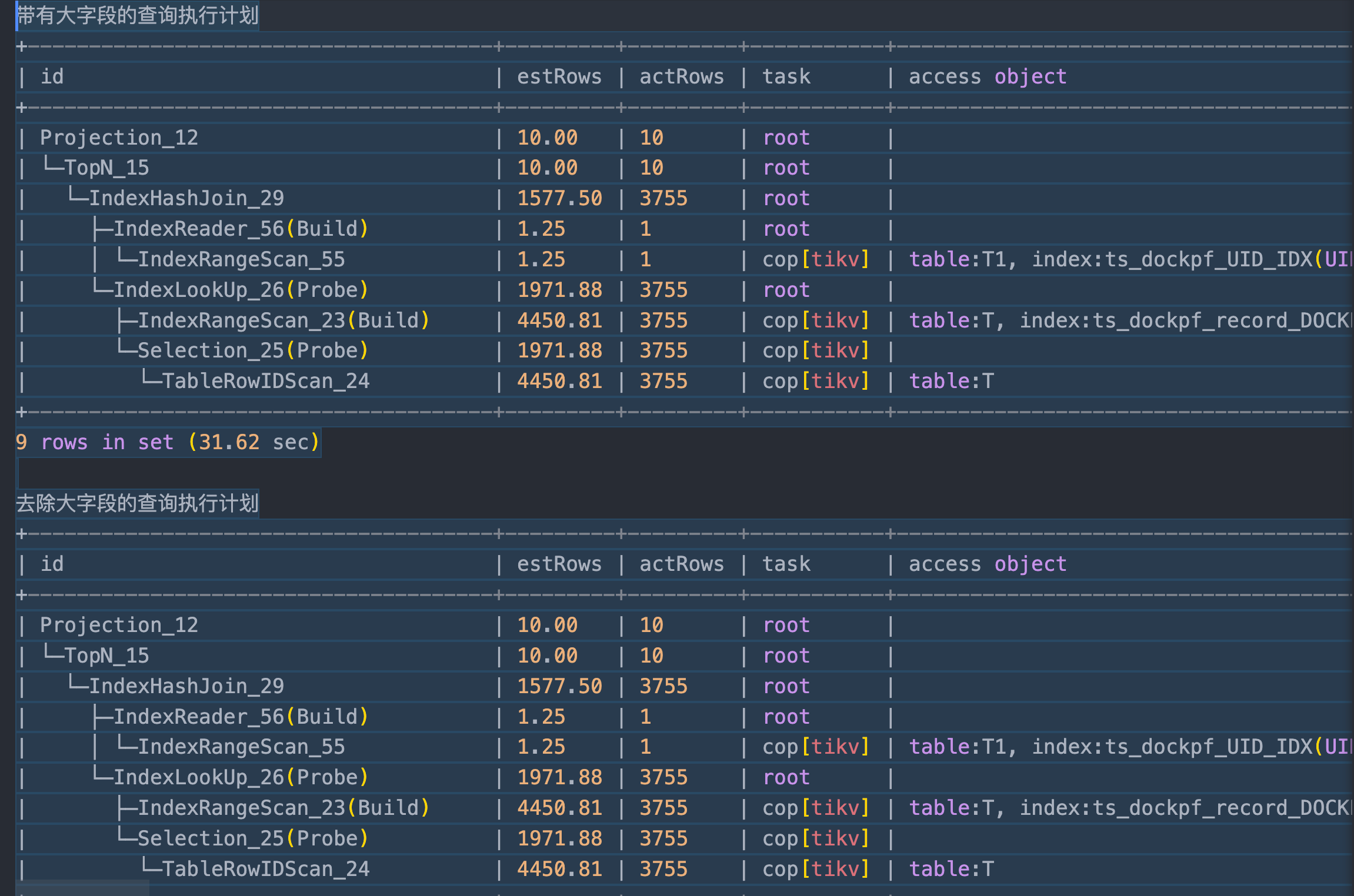
两次执行计划
bbb.sql (27.2 KB)
对于这种大字段查询的耗时,请教各位大神,如何优化?