【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
语句
use.sql (3.1 KB)
之前执行计划.xlsx (2.9 KB)
之后的执行计划.xlsx (3.6 KB)
【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
语句
use.sql (3.1 KB)
看走的索引也不一样
有什么好的建议
先把表做个分析看看能快点不
我先试试强制索引吧
两个sql的表都不一样啊,不只是条件不一样吧
把表结构贴出来
表结构.sql (1.4 KB)
当然一样
把sql贴完整
这就是完整
![]()
之前执行计划:执行计划中只出现了a和b,其他表在逻辑优化的时候移除了,因为c、cc、atc表关联方式都是left join,并且关联列上都有uniqe key,最终的sql查询列并不包括c、cc、atc,消除这3张表并不影响执行结果,优化器意识到了这点,所以直接消除了这3张表。
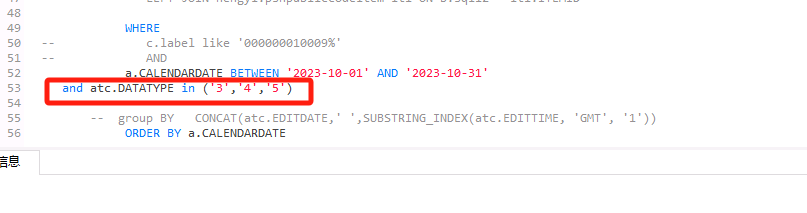
之后的执行计划:由于增加的in act.datatype (xxx)条件,导致与atc表的关联由left join变为inner join,其join结果影响最终SQL结果,所以atc表不能被消除,但是我不太理解为啥c、cc表没有被消除。
等待其他大佬分析🧐
优化器对原SQL做了左连接消除,所以原SQL快很多。
下面SQL是等价的:
SELECT DISTINCT T1.* FROM T1 LEFT JOIN T2 ON T1.C1 = T2.C1;
SELECT DISTINCT T1.* FROM T1;
楼主可以试下注释掉下面两行:
-- LEFT JOIN hengyi.ORGSTDSTRUCT c ON b.BRANCHID = c.UNITID
-- left join hengyi.cpc_job cc on b.JOBCODE=cc.id
现在我倒是可以解决,就是把这个东西写成子查询,让后在外面加条件,就变快了,但是原理是什么我真的不懂
而且同样的sql ,同样的数据mysql非常快
而到tidb跑不出来就因为这个in
我试试看吧