【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.14
【遇到的问题:问题现象及影响】今天发现有个任务写入有堆积 查看监控有几个指标异常,麻烦大佬指点下怎么优化
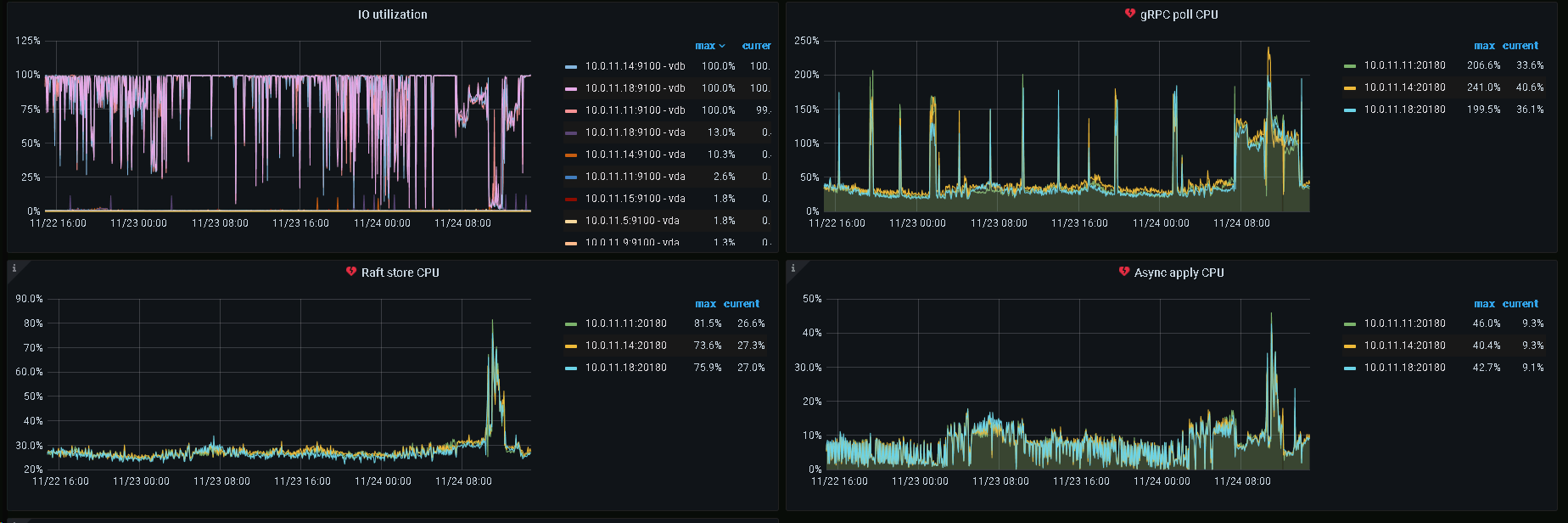
gRPC poll CPU使用率达到了200%
【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.14
【遇到的问题:问题现象及影响】今天发现有个任务写入有堆积 查看监控有几个指标异常,麻烦大佬指点下怎么优化
gRPC poll CPU使用率达到了200%
优化这么多其实还不如升级下版本,我之前用的4.0.9很多insert慢,升级后性能提升非常大,基本在慢查询看不到insert
你升级到哪个版本了呀 现在迭代太快了 我反而不敢升
去年从4.0.9升到5.4.3了 迭代是快,现在没动力升级了
看了下文档 升级很简单 你在升级的时候没踩坑吧
你们升级是直接升级还是重新建一个集群然后同步数据过去?
两个方式都可以实现升级
具体看你们的业务重要程度,最稳妥的方法就是两个集群主从切换
低版本通过cdc同步到高版本。这样升级吗
建议升级一下版本
是的,我们做过好多次4.0到5.4的升级,都是cdc主从同步然后切换升级。
原地升级也做过不少,两种方式都可行
我半夜升级的, --force升级的,不加–force需要每个kv驱离leader非常慢,但是前提是你要测试过各个方面没问题再升级
直接升级啊,4.0升到5.4测试过没问题才直接升的
我目前tidb是5.2,dm是2.06,之前在测试试过升级,dm数据同步异常,异常后降级也降不了,现在也不敢升级,要不然出问题老板得坐我旁边上班
稳定运行、没特殊需求就别升级。
确实,我们有个集群升级后,ddl执行特别快
新版本䏌会解决原来很多BUG
13点30分 后 Command* Per Second 增加,QPS增加, Duration减少。
感觉是突然增加了大量的小SQL执行,导致IO使用率增加,不一定是慢SQL,因为慢SQL一般比较大。大量的小SQL同样有较大危害,可以看看这段时间的小SQL执行频率大量增加的是什么?
COM_PING、COM_SLEEP、COM_STMT_FETCH、COM_SEND_LONG_DATA 之类的命令执行时间select 1; select 1; select 1;。此时,统计的执行时间是所有 SQL 语句执行完之后的总时间SELECT、INSERT、UPDATE 类型进行了区分感觉象是网络传输慢造成的异常
多观察,是这个表的写入慢,还是特定时间段的写入慢,更进一步定位问题
建议大神们按升级版本整理出来一个文档,比如3-6,4-6之类的