表A信息:
数据量:80000
表结构:以常见字段类型在内的varcahr、char、int类型为主,共24个字段
包含自增主键在内,共4个索引:
primary、unique(column1,column2)、idx1(column1,column3,colum4)、idx2(column3,column4);
因为不想动原表,所以复制了临时表A_temp;
在做 insert into A_temp select * from A 时,8万数据跑了5分钟
然后我尝试其他表的插入情况:
insert into B_temp select * from B,74000的数据只用了5秒; 差距太大了
B表和A表表信息相,包含自增主键在内3个索引
primary、unique(column1,column2,column3,column4)、idx1(column5,colum2);
我该从哪些方面和手段能分析出现这种情况的原因?
zhanggame1
(Ti D Ber G I13ecx U)
2
先检查表A和B的实际regions数量和大小,tidb全表扫描和regions个数有关系
show table A regions
EXPLAIN ANALYZE select * from A
EXPLAIN ANALYZE select * from B
比较一下
小龙虾爱大龙虾
(Minghao Ren)
4
首先从慢日志中找到这两次执行,把执行计划发出来看下吧
随缘天空
(Ti D Ber Ivw R7o Pj)
8
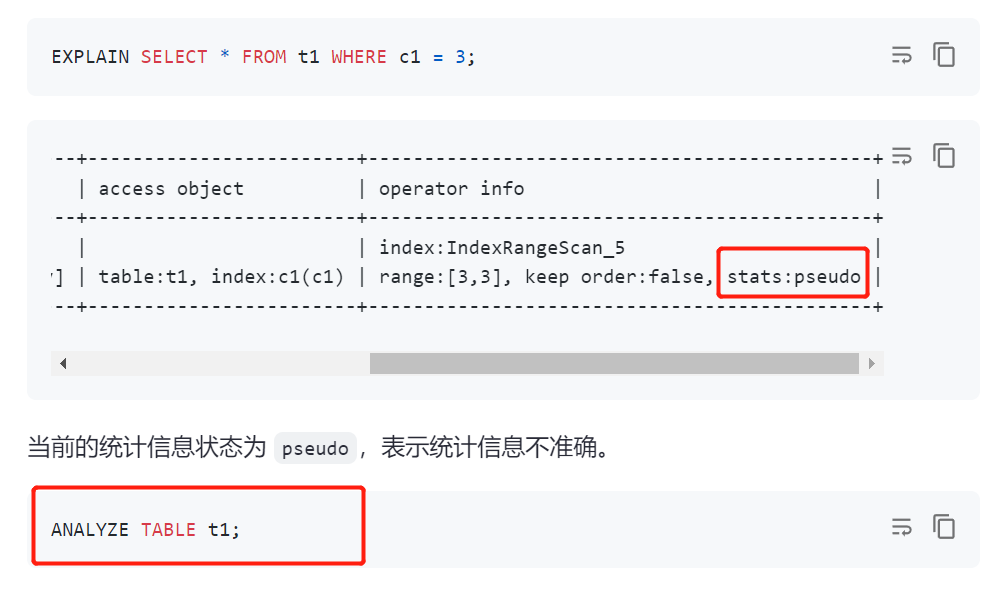
有可能是表的统计信息不准确,你可以参考如下图简单搜索一下,然后执行 ANALYZE TABLE t1;命令试试
Kongdom
(Kongdom)
9
 表A的索引字段值的区分度么?如果都是guid的那种字段,估计会占用时间相对久一点吧。
表A的索引字段值的区分度么?如果都是guid的那种字段,估计会占用时间相对久一点吧。
dba远航
(Ti D Ber M Lo7 Bqhk)
10
在没有其它事务影响的情况下,还要看两个表的字段多少,包括字段类型,如果有LOB字段,会慢很多
心在飞翔
(o落叶o)
12
锁等的概率比较大,你可以在创建一张临时表B_temp,用同样的方式,从A_temp 中把数据复制到B_temp,看看复制时间是否正常
1 个赞