【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
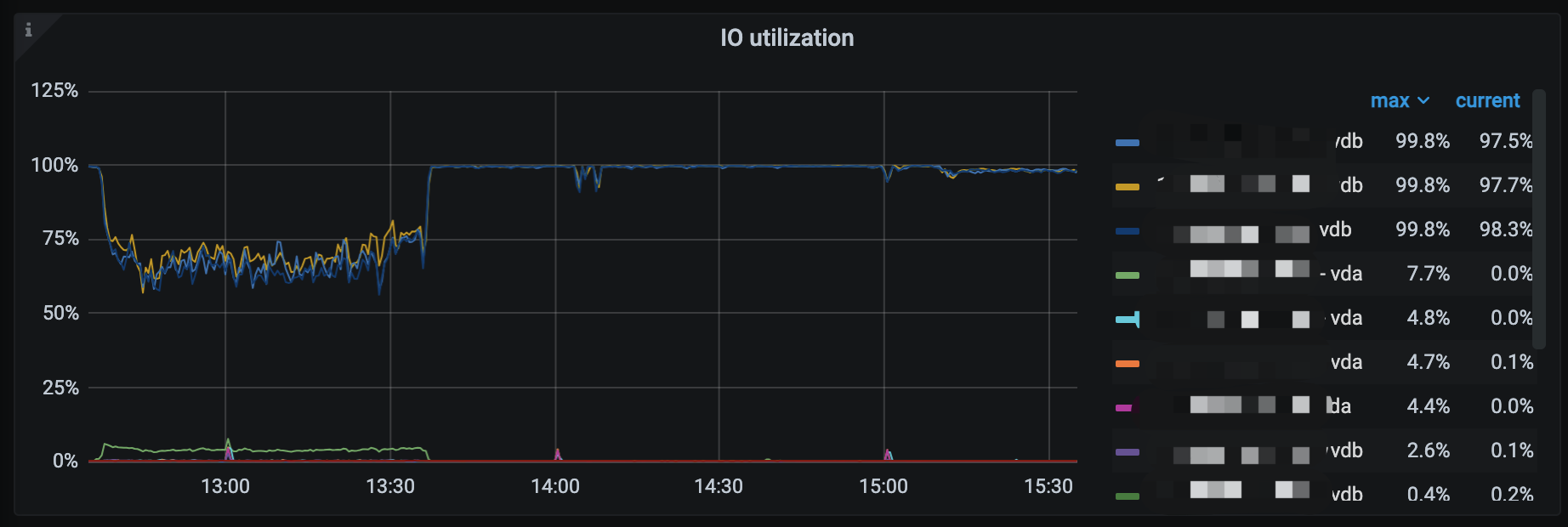
IO utilization 接近100%
tidb
slowlog
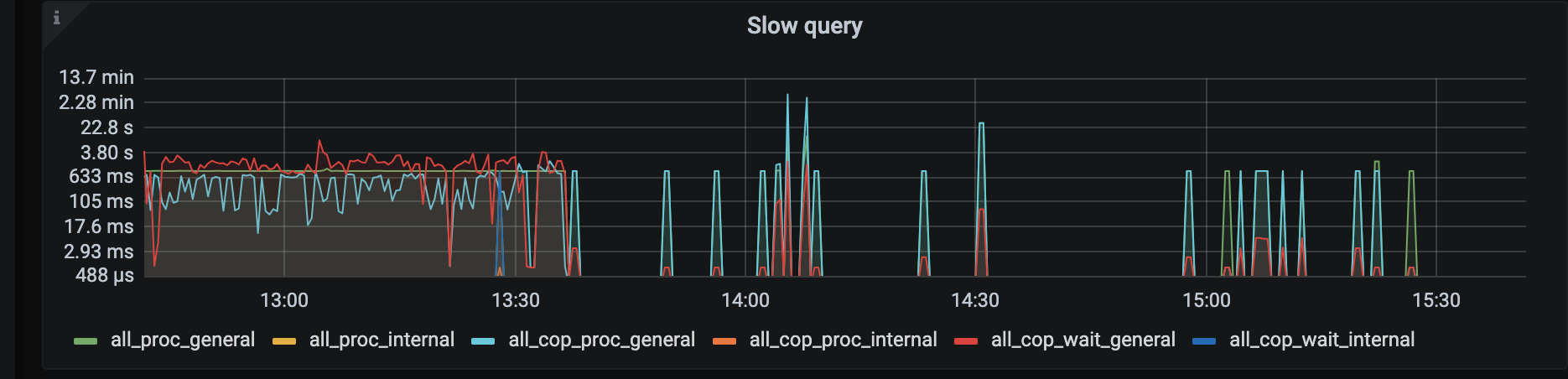
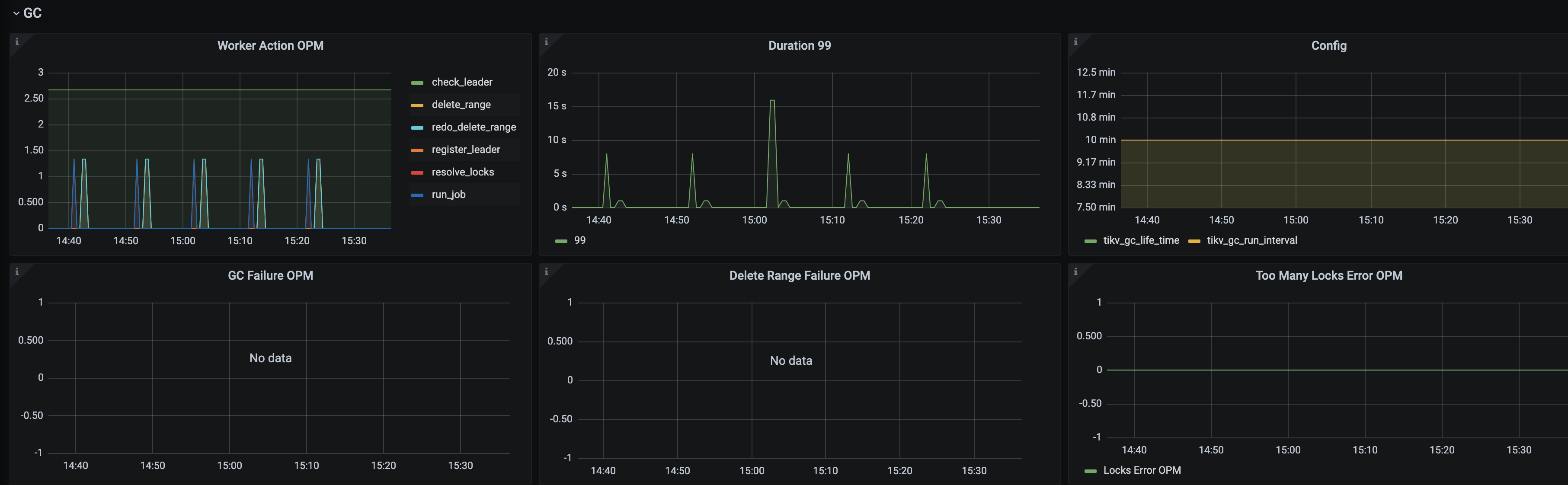
gc
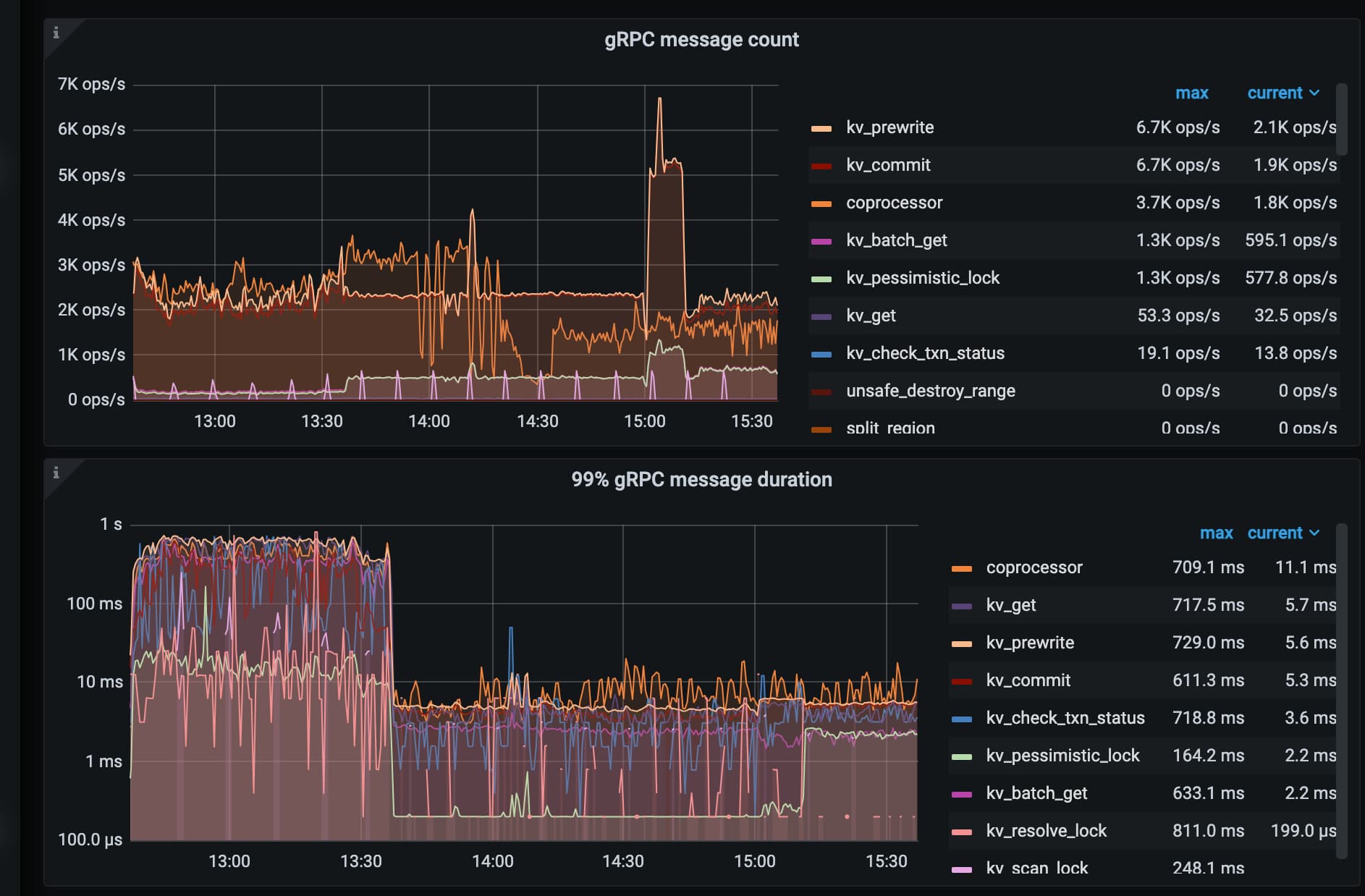
grpc
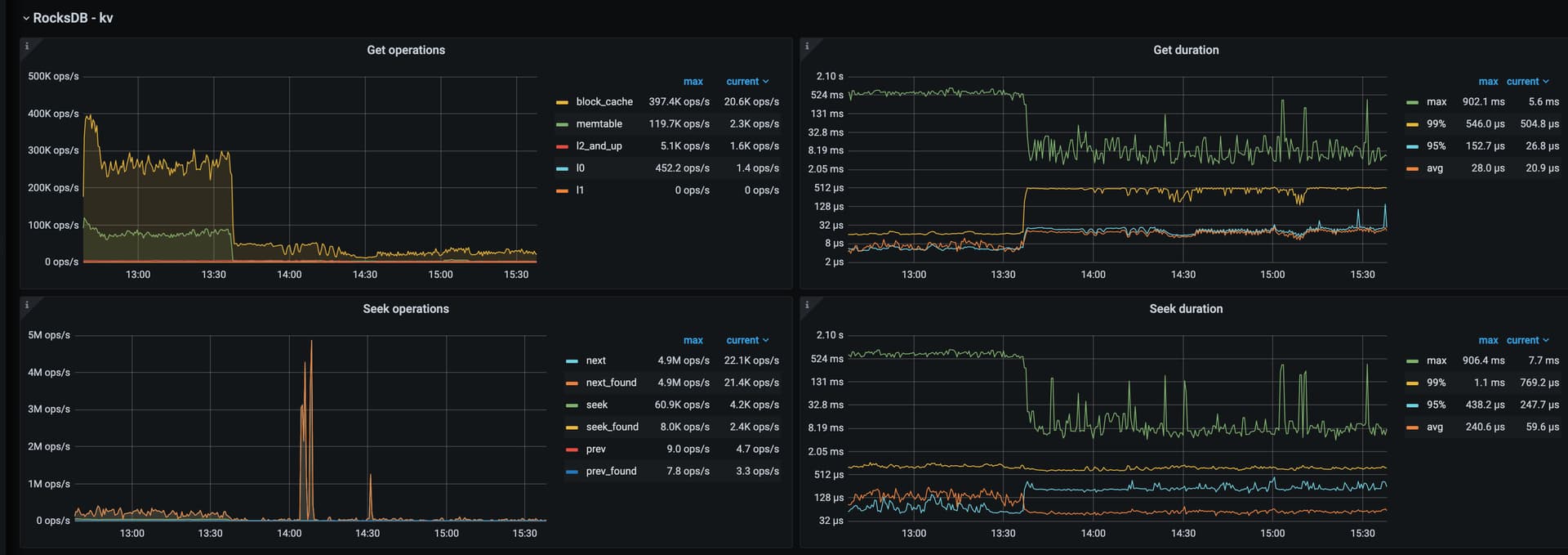
rocksdb compact
调度任务
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
IO utilization 接近100%
gc
rocksdb compact
我关闭了gc
set global tidb_gc_enable=off;
依然没有下降的趋势
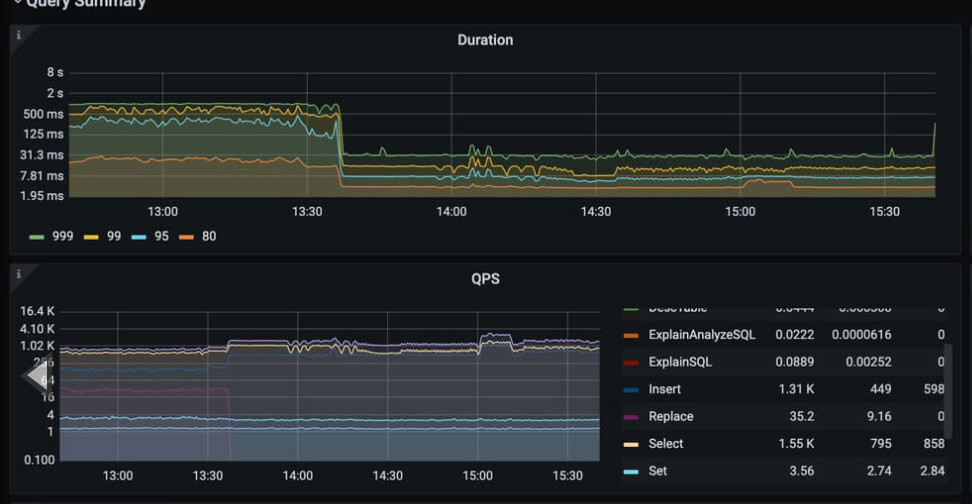
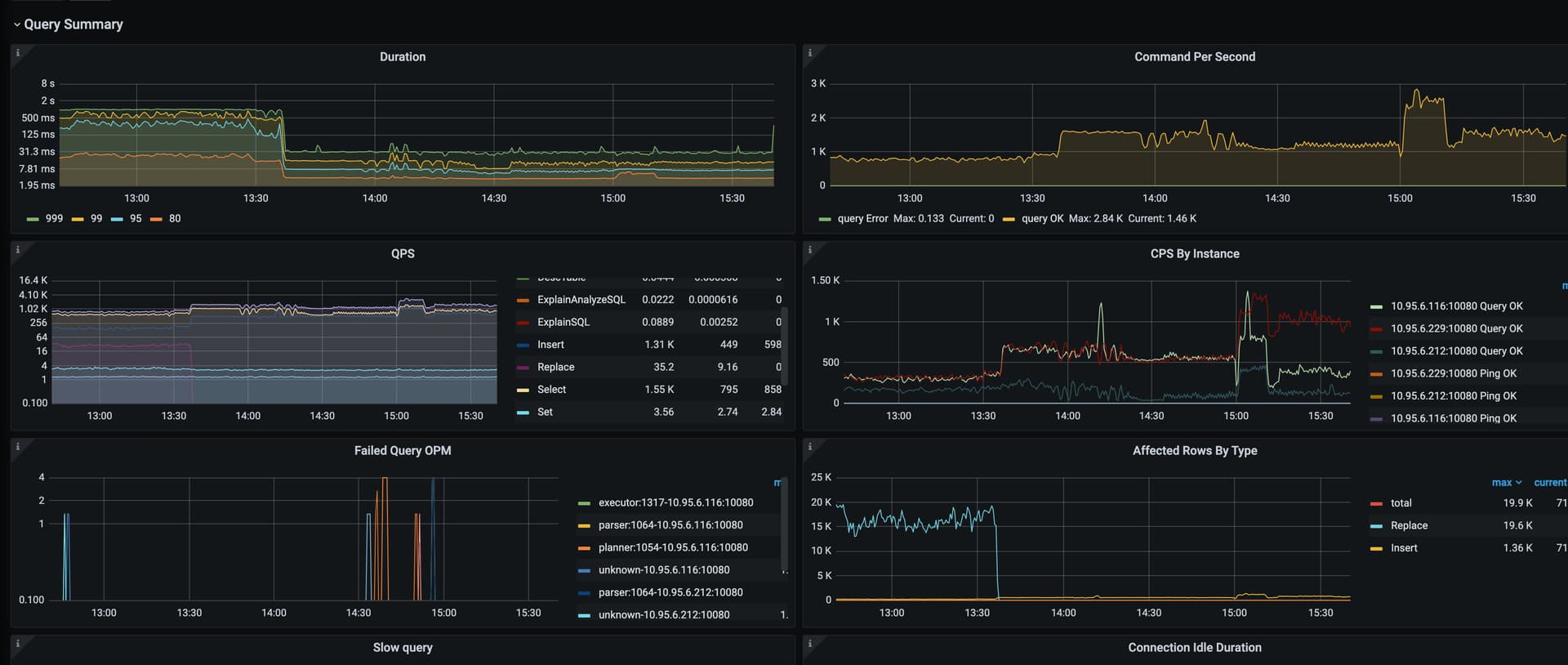
数据库整体延迟大吗?慢查询多吗?
duration和slowlog监控和tikv io不同步
io实际速度看看
dashboard中有个topsql能看到各个节点的sql资源使用情况
dashboard看下慢查询,看看系统在执行哪些SQL,看看是不是有大表在analyze table
排除analyze,我加了begin,end执行区间
根据我个人经验,一般都不看那个了,ssd那个经常是满的,更多应该关注吞吐量、IOPS、读写相应时间等指标。
想看tikv是什么IO在写入,可以看下tikv-detail-》IO breakdown。
这个节点有跑其他服务吗?
看看磁盘延时,有时候io util不准
这个即使长期 100% 也不能直接说明磁盘"满载"
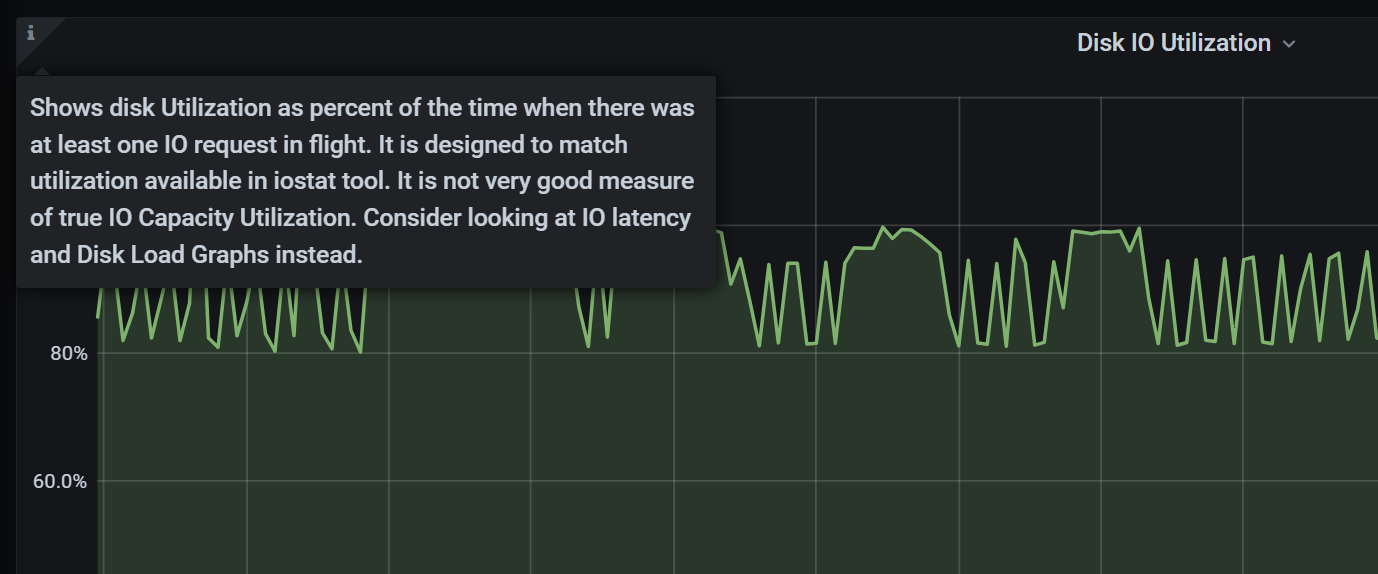
有一个专门展示磁盘指标的 Dashboard 叫 Disk-Performance, 这个 Dashboard 里也有一个图是 Disk IO Utilization, 官方还给了一个说明
Shows disk Utilization as percent of the time when there was at least one IO request in flight. It is designed to match utilization available in iostat tool. It is not very good measure of true IO Capacity Utilization. Consider looking at IO latency and Disk Load Graphs instead.
这个图使用的指标来自 node_exporter 的 node_disk_io_time_seconds_total, tidb 用的表达式是
rate(node_disk_io_time_seconds_total[$interval])
这个结果对应于 iostat 工具的 %util 列, 手册里是这么说的
man iostat
%util
Percentage of elapsed time during which I/O requests were
issued to the device (bandwidth utilization for the de‐
vice). Device saturation occurs when this value is close
to 100% for devices serving requests serially. But for
devices serving requests in parallel, such as RAID arrays
and modern SSDs, this number does not reflect their per‐
formance limits.
我们这边用的aws的磁盘,io util基本都是满的
也正常,QPS高了后999线已经不足以显示哪些比较慢的SQL的执行情况,但那些执行慢的SQL可能并未消失 ![]()
查看一下IO排名前几位都在做什么
这个指标不是很准,具体要看是不是IO瓶颈
尝试修改raftstore.sync-log =false参数,并观察这是否对IO情况产生影响。
1、dashboard看一下慢查询
2、show full processlist看一下当前进程
3、就是我们机械硬盘经常遇到的,本身就是IO读写低,经常打满。