【 TiDB 使用环境】所有环境
【 TiDB 版本】
【复现路径】sql查询慢 例子 select * from t left join bt on t.cust_no=bt.cust_no where and bt.cust_name=‘adad’
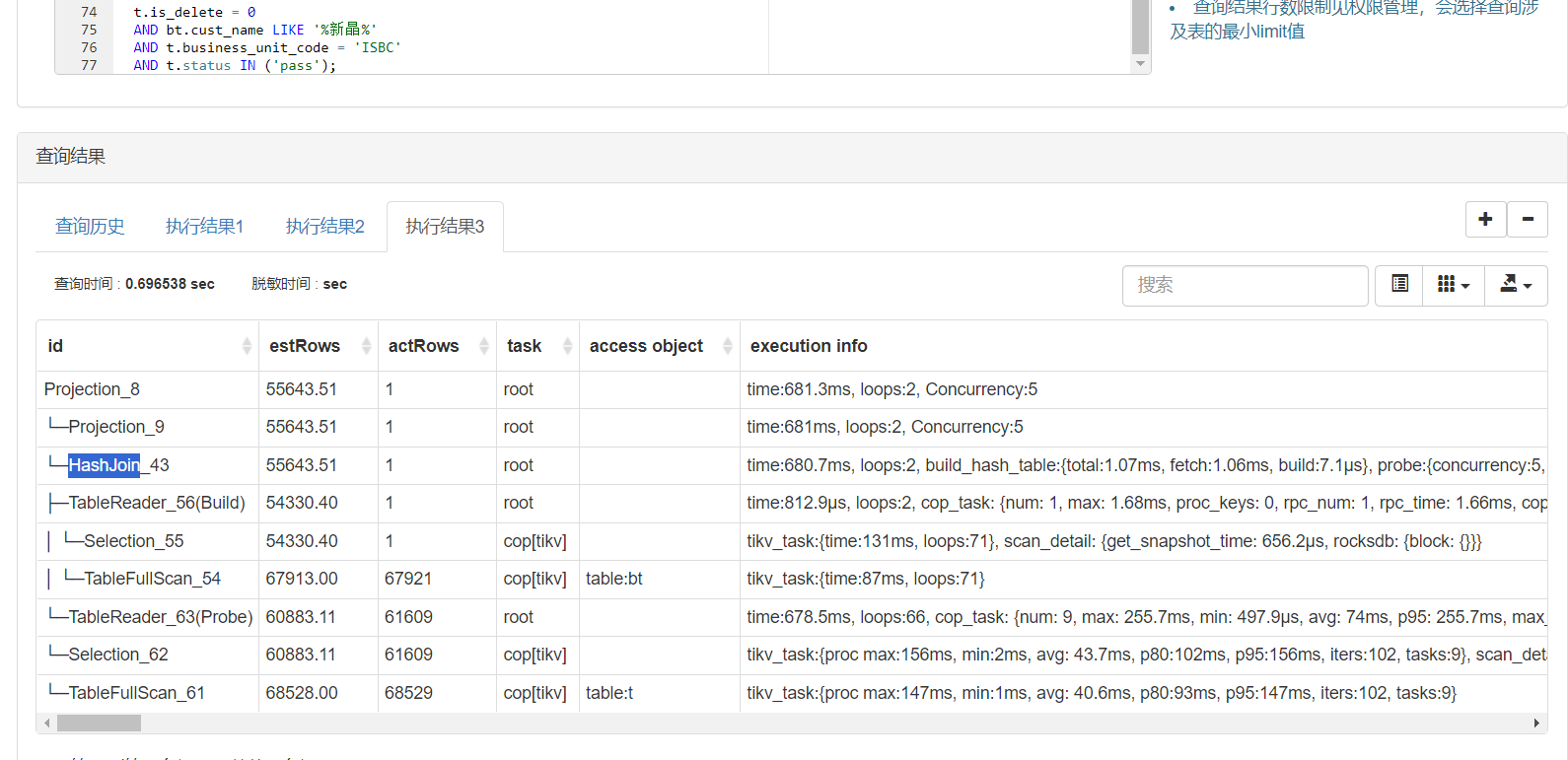
【遇到的问题:问题现象及影响】查询慢,进行hashjoin前,表bt过滤后符合数据1条,但是却读取了t表的全部数据进行hashjoin,是否有办法先根据查询条件查出bt表数据然后再进行hashjoin呢,如图二,但是使用=不符合业务需求,只能使用in,有什么办法可以优化吗
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】

1 个赞
可以考虑使用HINT呀
问下怎么使用嘛
先分析下表t和bt看看,执行计划有问题
这里的like语句能不能优化一下,会不会是like导致的索引失效
用/+ INL_JOIN(t)/试下,前提t表要有客户号开头索引
hnit指定索引
建议将 left join 换成 inner join。
因为当where条件里有left join表的字段时,相当于是inner join。
inner join的速度实践起来比left join快很多。
1 个赞
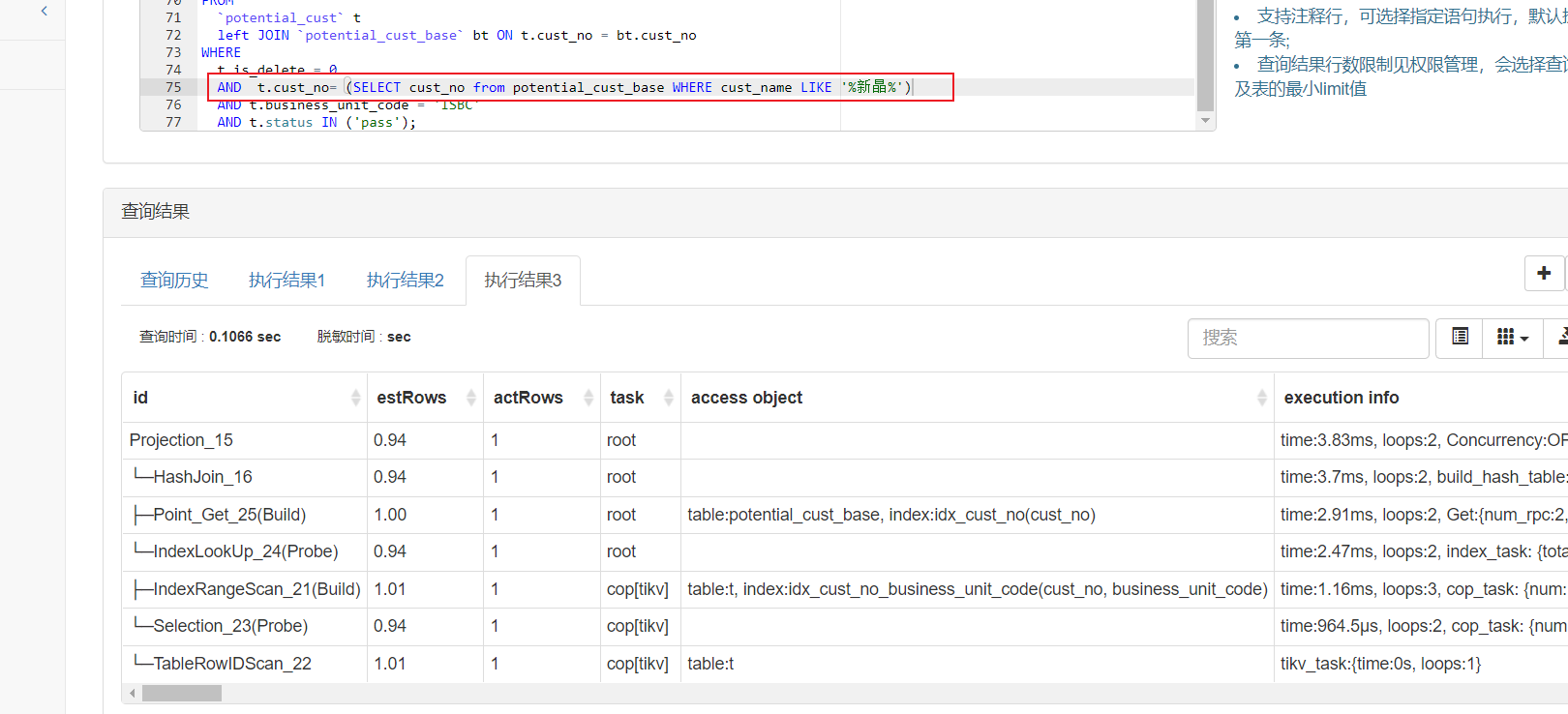
将in函数换成exists试试,比如
WHERE t.is_delete = 0
AND EXISTS (
SELECT 1
FROM potential_cust_base AS pcb
WHERE pcb.cust_no = t.cust_no
AND pcb.cust_name LIKE ‘新 晶%’
)
AND t.business_unit_code = ‘ISBC’
AND t.status IN (‘pass’);
表结构也发下吧,感觉索引设计的也不太合理
1 个赞
失效也没有关系的,问题是返回了t表的全量数据和bt表做join
t left join bt
图一。
left join的而情况下,t表符合条件的6w1肯定是都要的吧。
bt也没有查全表。bt只有一条数据,整个tableReader算子执行也不到1毫秒。
整个执行计划,瓶颈就在t表的6w1读取上。并非是bt表。

根源不是索引的问题
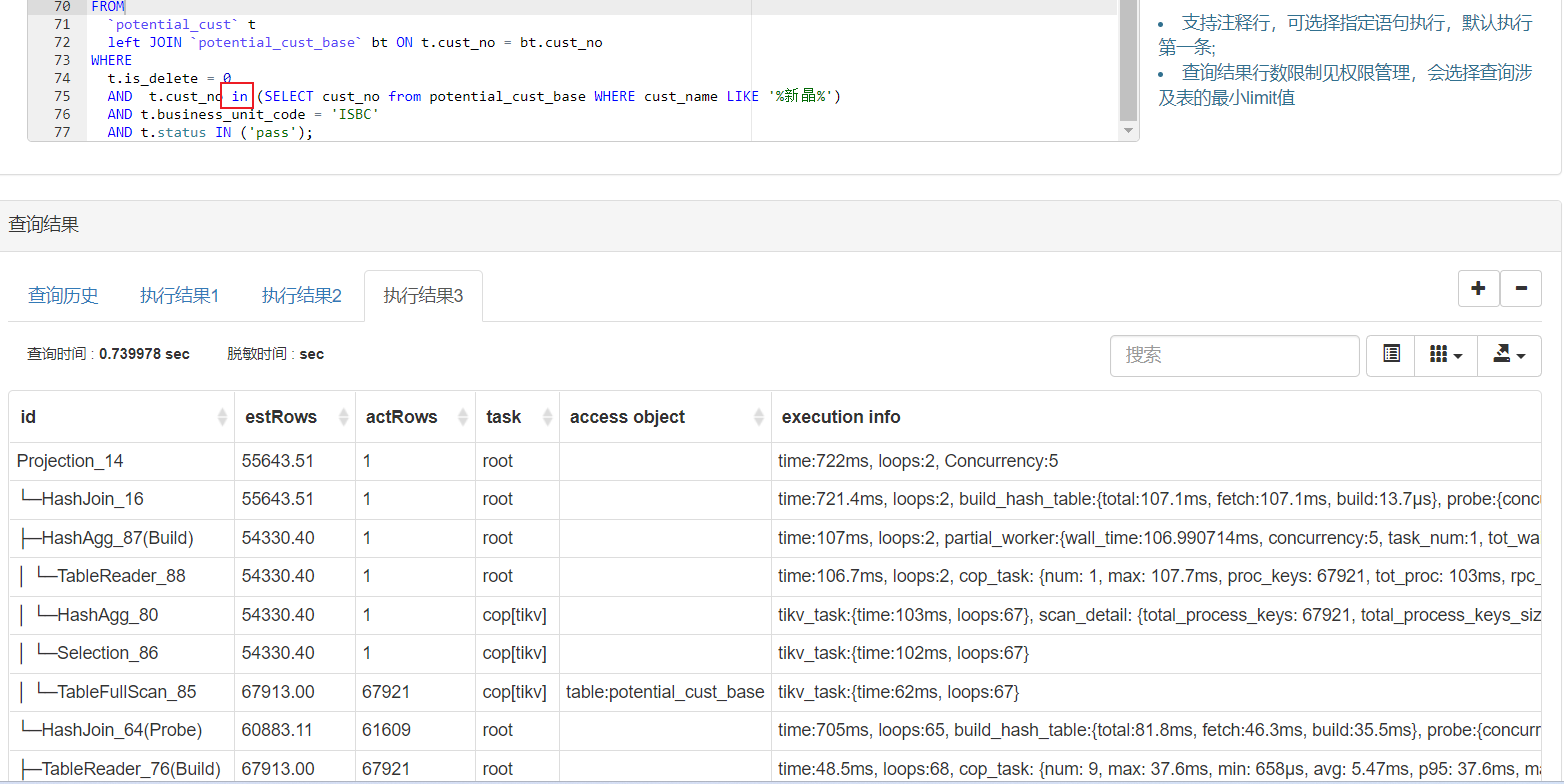
in和exsits本身是等价的
我大概明白你的意思了,你的意思是需要bt表先查出关联t表的id,然后带入t表的条件直接去扫描t表。而不是执行hashjoin。
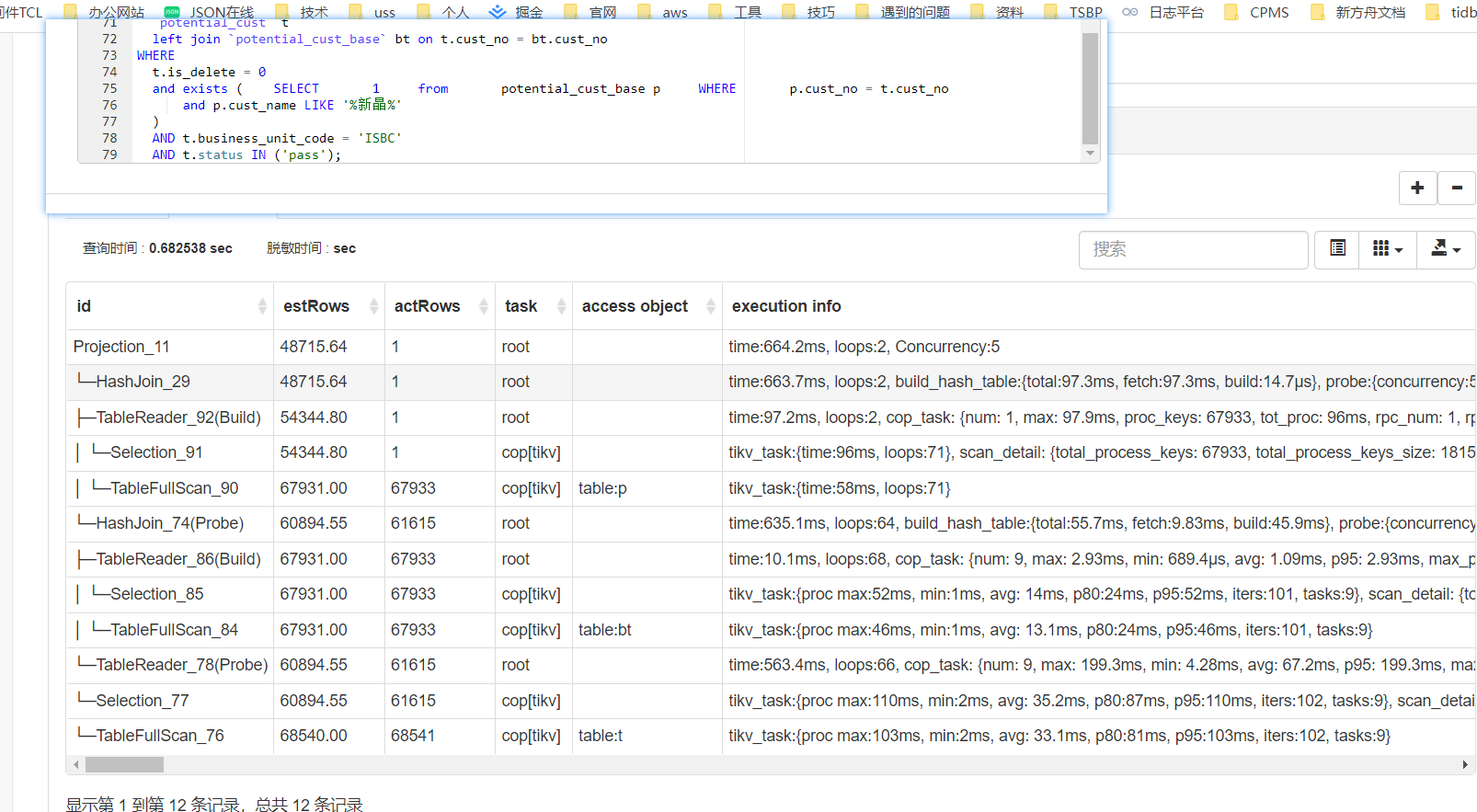
优化器没有这么做的原因,我感觉在于统计信息,图1里面根据你bt表的条件,预估数据是5w4.
当使用=连接的时候,预估数据变成了1条。然后查询符合预期了。
使用in的时候,统计信息还是5w4,执行时间就又变长了。
解决办法,感觉还是建立索引后,尝试index-join hint。会靠谱一些。
https://docs.pingcap.com/zh/tidb/stable/explain-joins#index-join
2 个赞

嗯,因为过滤后再执行sql的话扫描的数据就会少很多。所以在执行之前,尽量把无效的数据先用条件过滤掉,减少扫描的范围
是的,问题就是怎么样可以过滤了 ![]()