
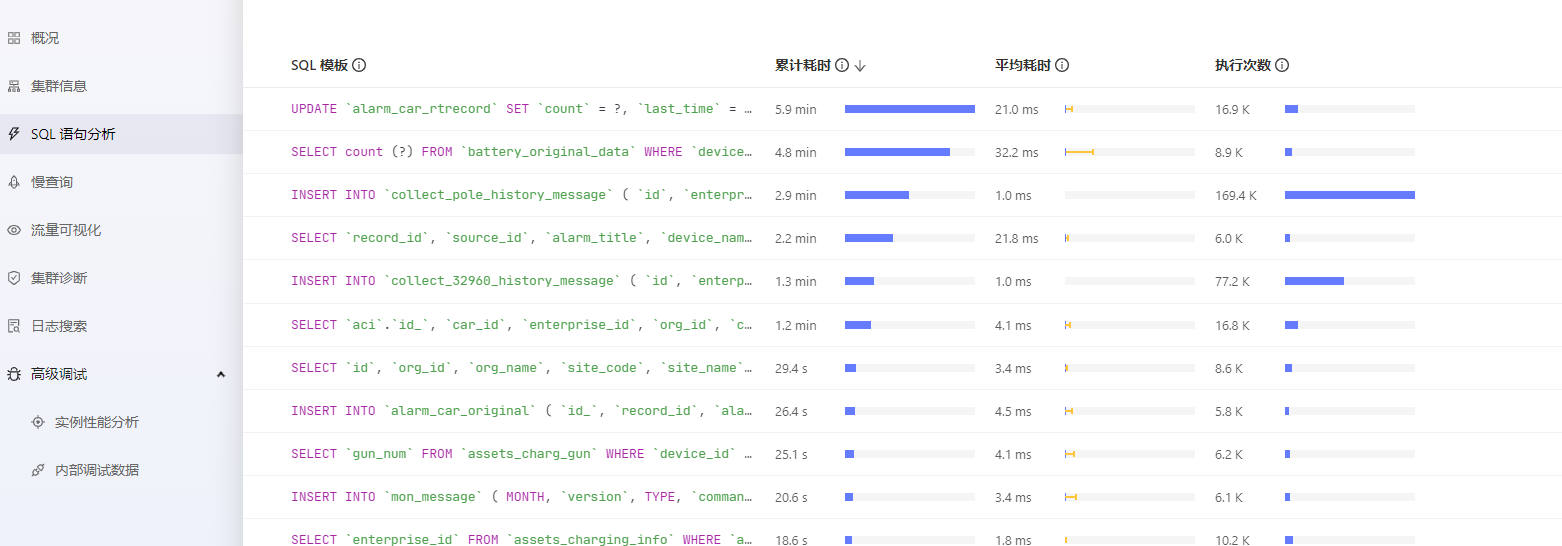
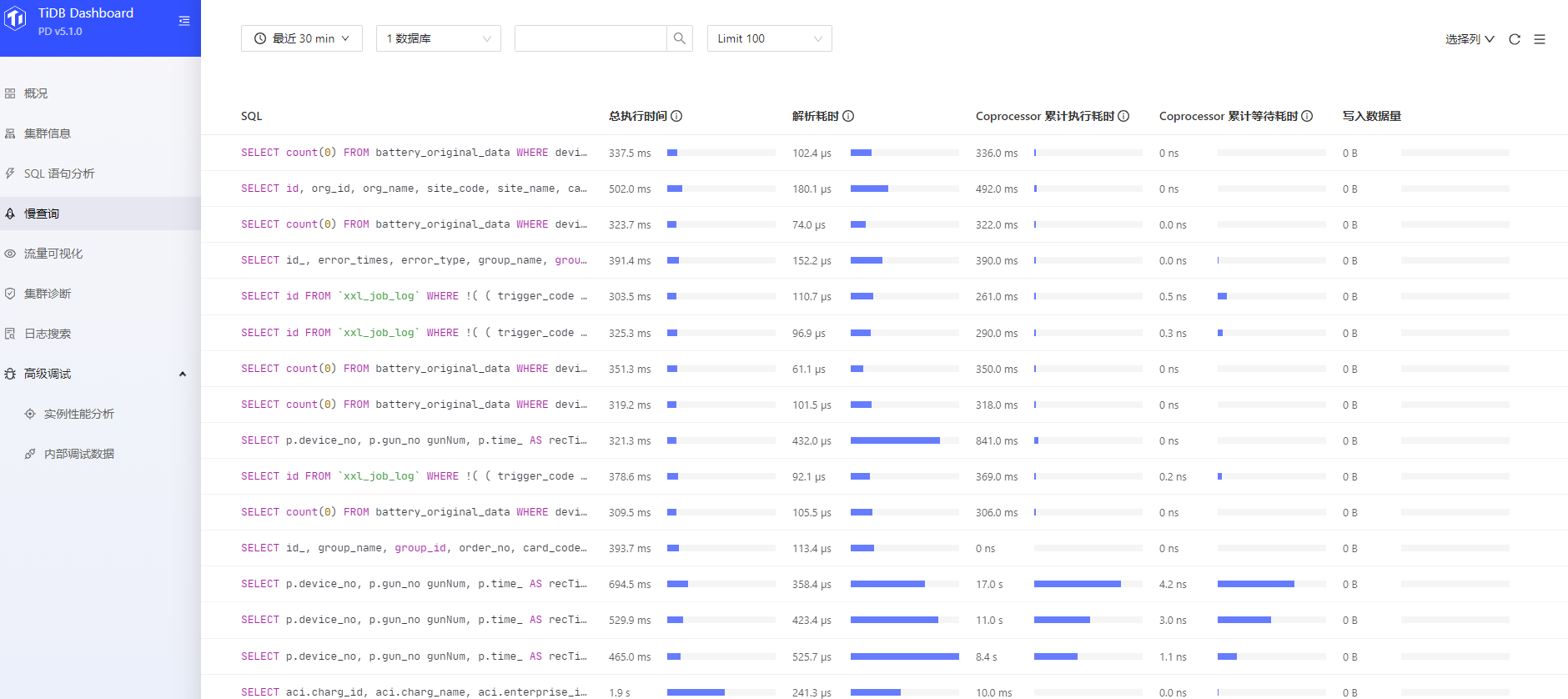
![]() 看看Dashboard的TopSQL,看看是不是有大sql?
看看Dashboard的TopSQL,看看是不是有大sql?

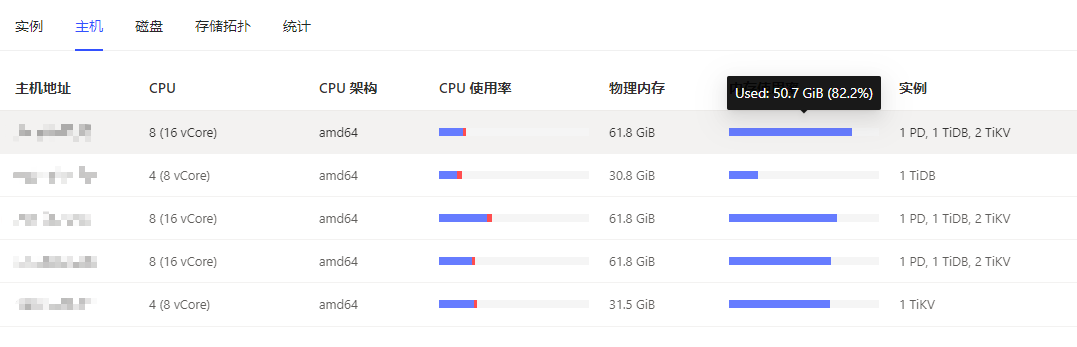
你这是混布的节点啊!都是1PD、1TiDB、2TiKV的配置啊
嗯嗯是的呀,就算是混合部署,也不知道为啥TIKV的进程占用内存怎么会偏高呢,奇怪了
第一个那个sql,1秒要执行2次?执行频率有点高吧。
刚注意到是混布,并且还是1台服务器混布2个tikv,这种很容易造成资源争用。
你这个看上去就是sql问题,或者你打开dashbord的topsql看下,而且你是混布会造成资源争抢
你这配置资源不够了,扩容吧。别混合部署了一个服务器就一个节点。
storage.block-cache生效了吗?v6.6.0之前的版本仅在开启 shared block cache 时起作用
[storage.block-cache]
是否为 RocksDB 的所有 CF 都创建一个 shared block cache。
RocksDB 使用 block cache 来缓存未压缩的数据块。较大的 block cache 可以加快读取速度。
推荐开启 shared block cache 参数。这样只需要设置全部缓存大小,使配置过程更加方便。
在大多数情况下,可以通过 LRU 算法在各 CF 间自动平衡缓存用量。
storage.block-cache 会话中的其余配置仅在开启 shared block cache 时起作用。
从 v6.6.0 开始,该选项永远开启且无法关闭。
shared = true
shared block cache 的大小。正常情况下应设置为系统全部内存的 30%-50%。
如果未设置该参数,则由以下字段或其默认值的总和决定。
* rocksdb.defaultcf.block-cache-size 或系统全部内存的 25%
* rocksdb.writecf.block-cache-size 或系统全部内存的 15%
* rocksdb.lockcf.block-cache-size 或系统全部内存的 2%
* raftdb.defaultcf.block-cache-size 或系统全部内存的 2%
要在单个物理机上部署多个 TiKV 节点,需要显式配置该参数。
否则,TiKV 中可能会出现 OOM 错误。
capacity = “1GB”
https://docs.pingcap.com/zh/tidb/stable/tune-tikv-memory-performance
注意这句话 ## 要在单个物理机上部署多个 TiKV 节点,需要显式配置该参数。
tidb使用LSM-Tree内存算法,本来就特别费内存,如果想降低内存使用率,可以调整它的参数,尽快刷新内存到硬盘进行固化
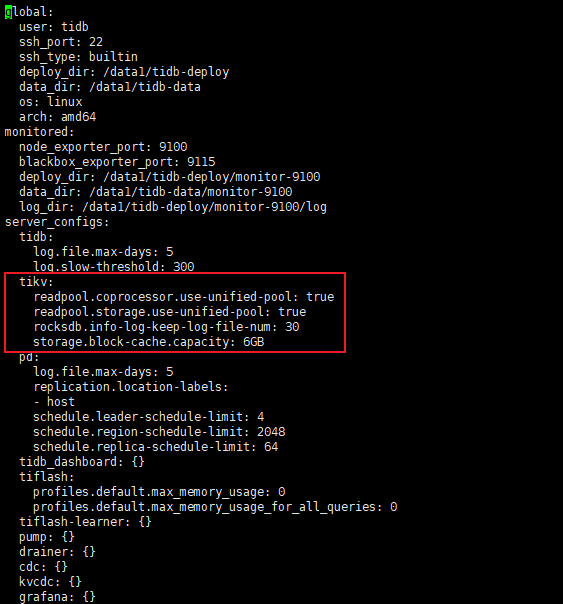
我的第五个节点是单独的TIKV,也是内存占用过高呢。
慢sql贴出来看看呢,估计读写太高了把???
问题解决了吗
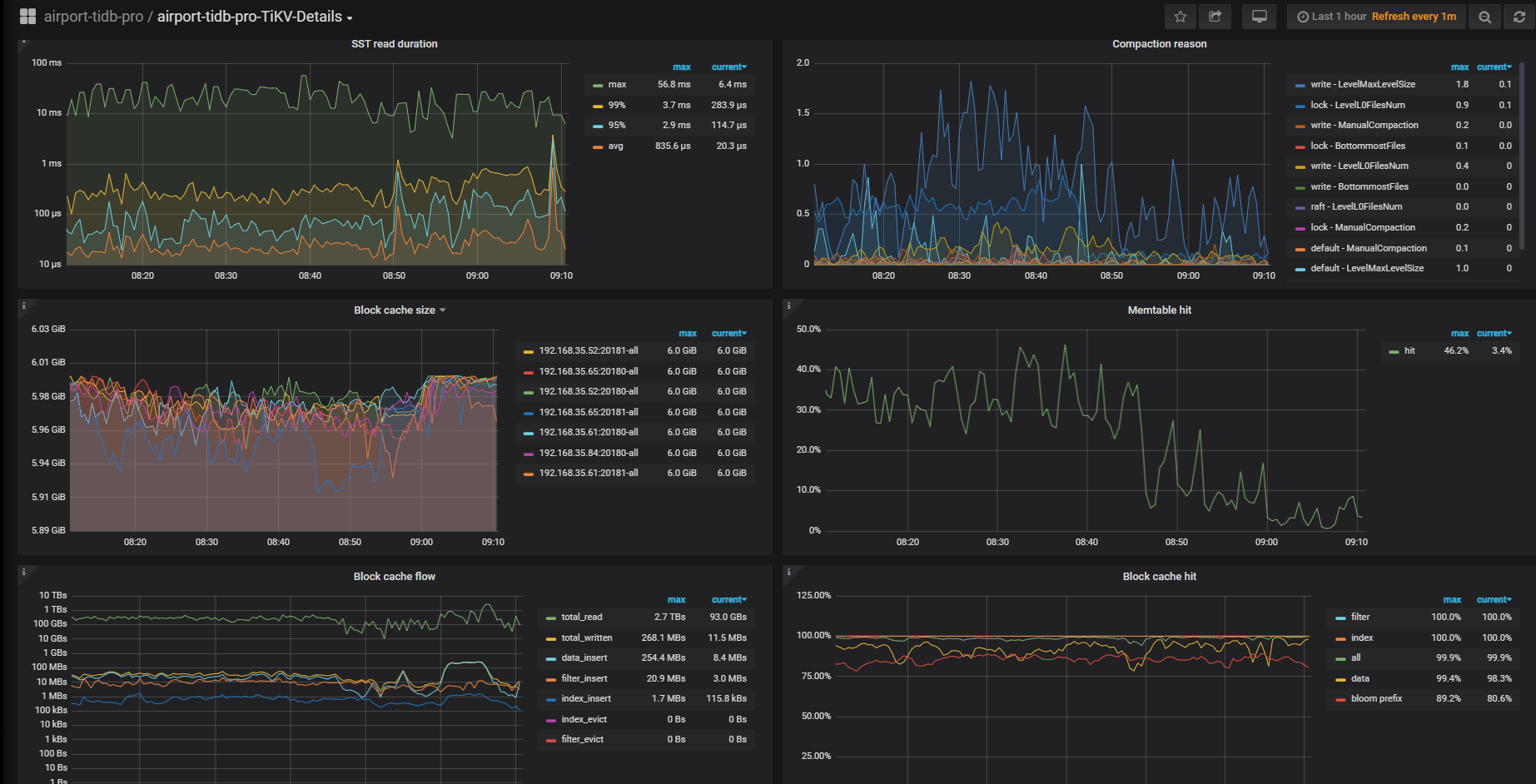
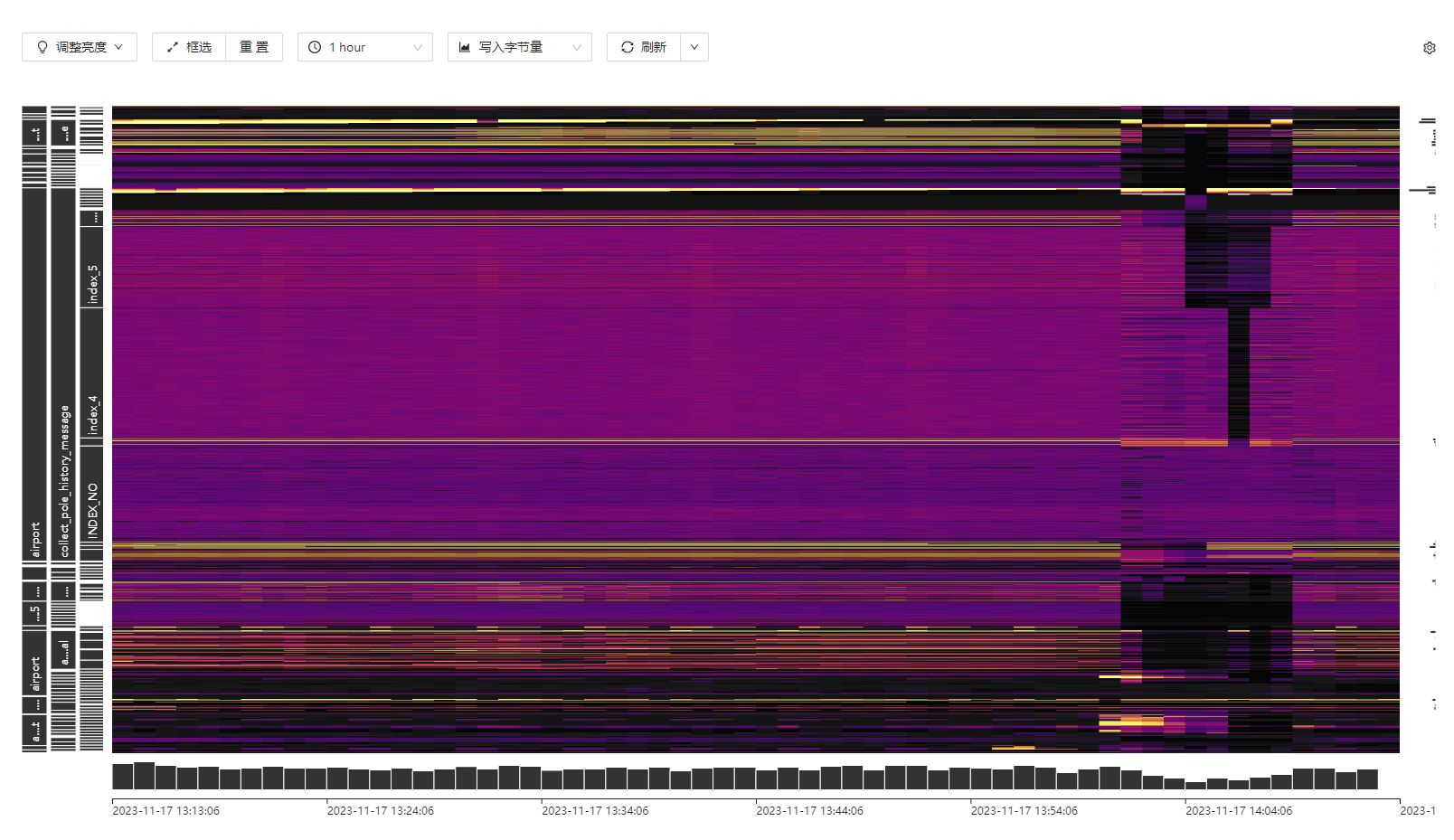
看一下这个有没有热点
看一下这个参数,调节内存写入硬盘的:max-write-buffer-number