Dais
2023 年11 月 15 日 01:19
1
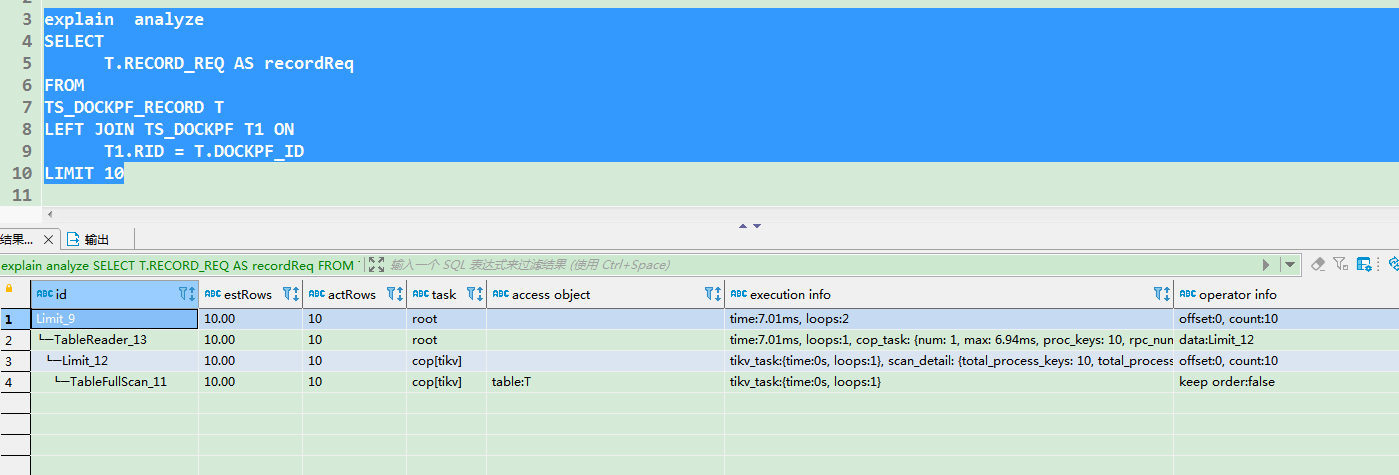
【 TiDB 使用环境】测试环境SELECT FROM LEFT JOIN TS_DOCKPF T1 ON LIMIT 10
【资源配置]
【上述SQL执行计划】
初步猜测会不会是机房突然断电重启后有可能某个tikv断电丢了region,但是不确定。也不知道如何锁定具体哪里出了问题,或者哪个TIKV节点出了问题。请各位大佬帮忙看看
这个应该和region损坏没关系,就是单纯的sql执行计划问题,你说去掉where T1.UID的条件,则查询只要几十ms,这时的执行计划可以贴出来看看
Dais
2023 年11 月 15 日 02:58
3
tidb菜鸟一只:
时的执行计划可以贴出来看
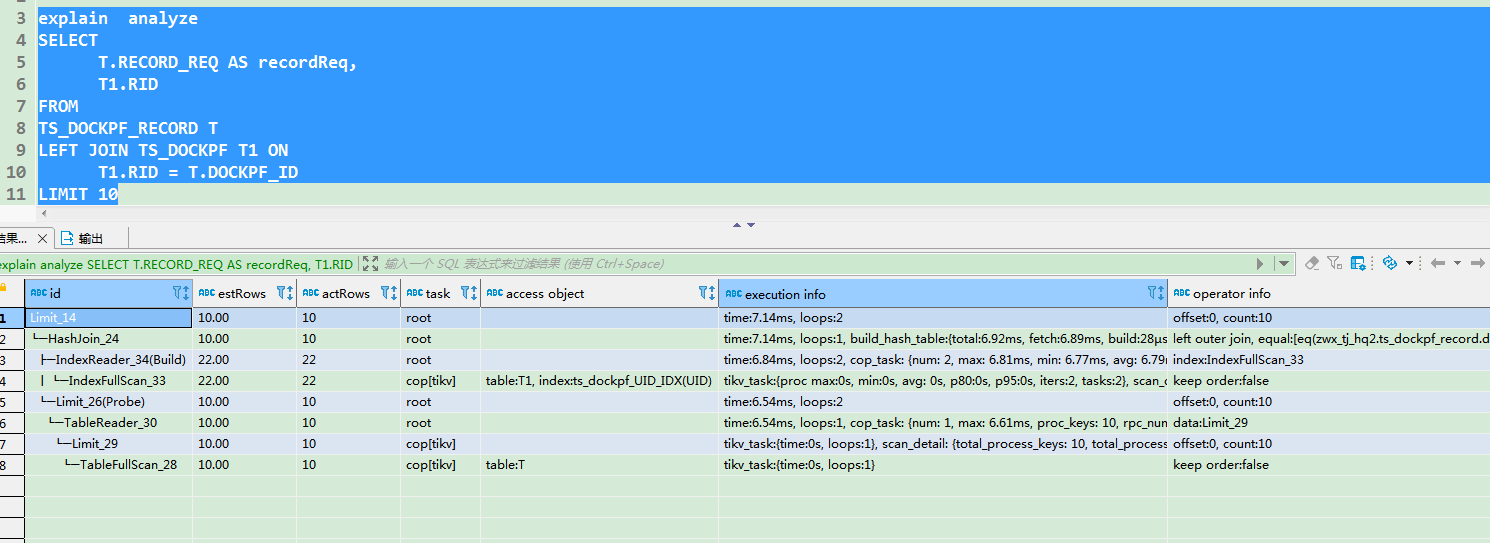
去掉where T1.UID的条件的执行计划
如果将T1.UID的条件跟在on后面,执行也只有几十ms。
或者查询结果中不带有大字段的结果,查询普通rid,name等等字段,查询也快。
你这执行计划不对吧,去掉where T1.UID的条件直接连join都没了吗?你给的执行计划看着是单表的啊
dashboard里面有个日志搜索,看下各个节点有什么报错没有?
Dais
2023 年11 月 15 日 05:38
6
这个去掉where条件的
为了区分,我在查询结果中多输出一个T1表的RID字段。
Dais
2023 年11 月 15 日 05:52
7
这是昨天下午的报错日志。
当时的业务现场是:我们的业务系统一旦启动连接数据库,数据库就卡顿,延时增高。后来,发现是业务系统中有个定时器在定时调用上述查询sql。后来分析锁定是上述sql查询太慢又频繁执行。
关闭对应的定时器后,数据库恢复正常。其他数据查询sql正常,唯独上面那个sql。执行需要50多秒。
慢查询引起了tidb的oom啊。
zhanggame1
2023 年11 月 15 日 05:55
9
单独查询T1.UID = ‘78AA82AA0C01474C88238161234567890’* 这个表速度怎么样
Kongdom
2023 年11 月 15 日 06:03
10
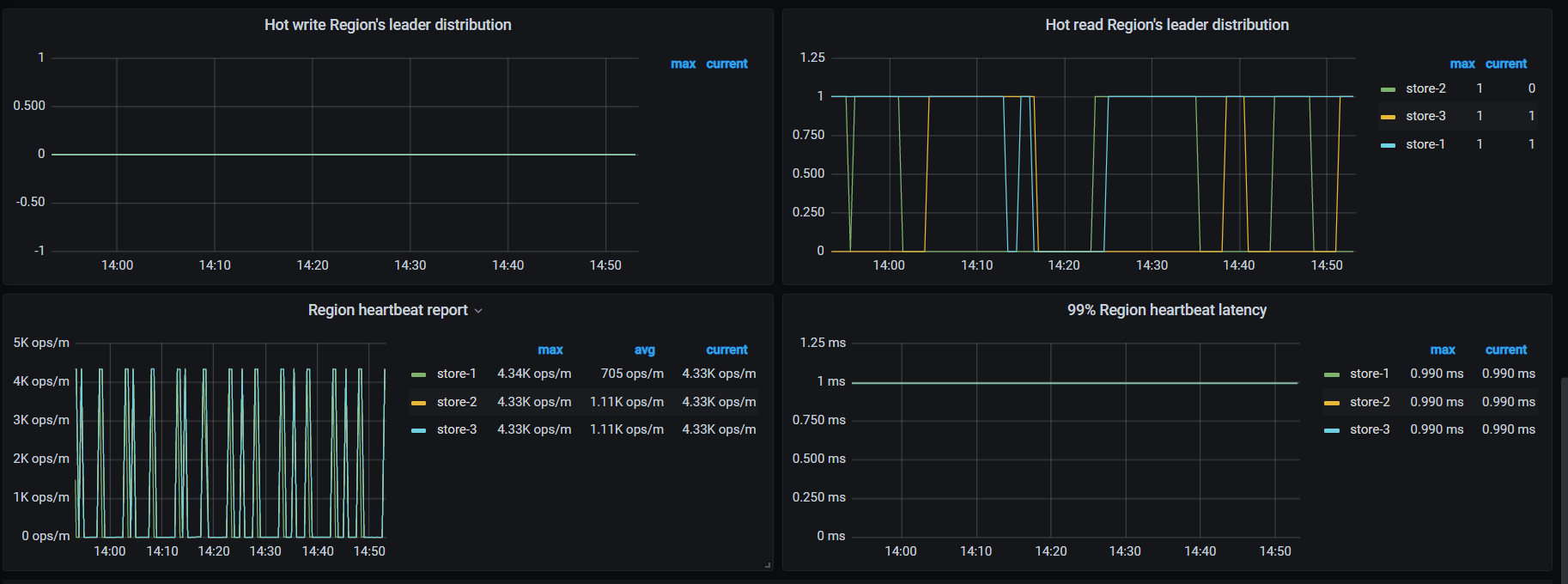
看看grafana里的监控,资源有没有异常情况,确认是否是OOM
1 个赞
小龙虾爱大龙虾
2023 年11 月 15 日 06:09
11
去掉where T1.UID的条件后join没了的原因是逻辑优化的时候给消除了,优化器发现不查T表不影响执行结果
region的健康可以看下grafana监控里的overview的pd,有个region状态的图
小龙虾爱大龙虾
2023 年11 月 15 日 06:21
13
从执行计划看有部分回表变慢了,可以看下慢日志,具体是哪个tikv慢,看下那个tikv有没有什么异常
有猫万事足
2023 年11 月 15 日 07:22
16
主要就是这个慢,这一行完整的Execution info给一份。看看扫描的key的数量是否有异常。
感觉像是gc,历史版本过多之类的问题。
Dais
2023 年11 月 15 日 07:50
17
time:1m55.7s, loops:11, cop_task: {num: 16, max: 49.6s, min: 1.75ms, avg: 14.3s, p95: 49.6s, max_proc_keys: 637, p95_proc_keys: 637, tot_proc: 4.73s, tot_wait: 8ms, rpc_num: 16, rpc_time: 3m48.7s, copr_cache_hit_ratio: 0.06, distsql_concurrency: 15}, tikv_task:{proc max:196ms, min:9ms, avg: 109.1ms, p80:144ms, p95:196ms, iters:71, tasks:16}, scan_detail: {total_process_keys: 7019, total_process_keys_size: 1281178524, total_keys: 7039, get_snapshot_time: 12.2ms, rocksdb: {key_skipped_count: 14018, block: {cache_hit_count: 6702, read_count: 510, read_byte: 7.20 MB, read_time: 4.86ms}}}
1 个赞
tidb菜鸟一只
2023 年11 月 15 日 08:07
18
感觉是T表上的dockpf_id索引问题,这个表只有8000条数据是吧,你把这个索引重建一下看看呢
有猫万事足
2023 年11 月 15 日 08:23
19
和gc应该无关了。
看不出什么异常,也就是total_process_keys_size: 1281178524 有点大。但7000+行读取的数据也不大。
h5n1
2023 年11 月 15 日 08:34
20
Dais:
cop_task: {num: 16, max: 49.6s,
时间慢在T表回表上,用trace select 执行看看 慢在哪个region , 然后通过tikv_region_status看看region leader所在tikv有没有异常,网络延迟,thread CPU情况