消息终结者
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.2
【遇到的问题:问题现象及影响】
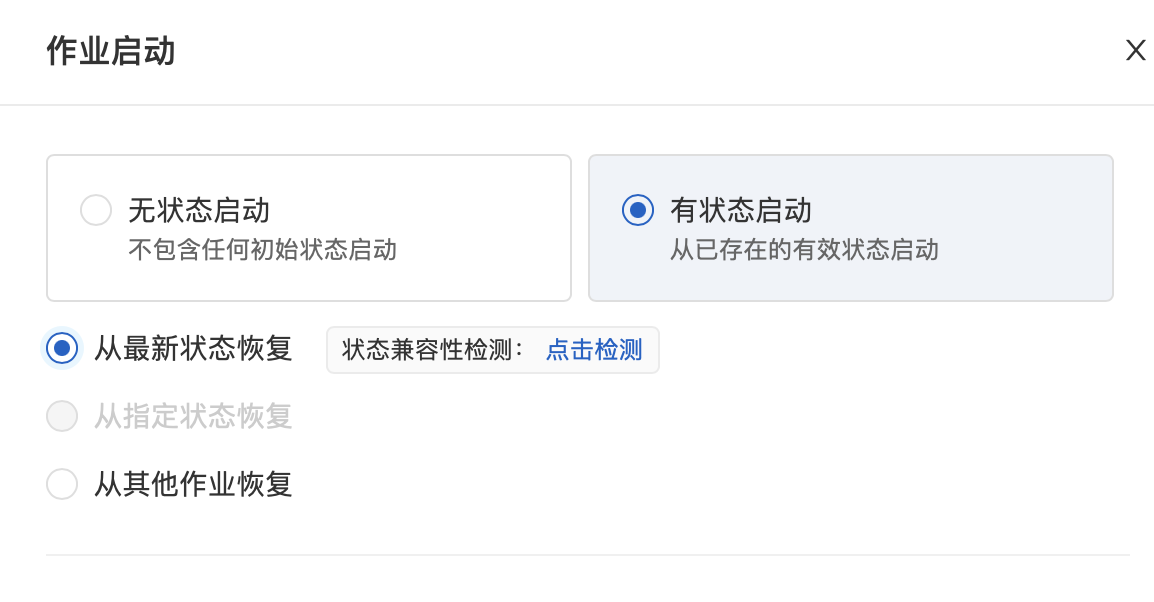
flink cdc tidb 无法从checkpoint 或 savepoint 状态启动
1、使用的环境是阿里云flink sql 方式
2、checkpoint ,savepoint 由阿里云flink托管,存放在oss
3、tidb源表数据量5000kw左右
4、使用的连接器 flink-connector-tidb-cdc-2.4.1.jar
问题现象
第二次重启flink任务,启动采用最新状态恢复(即ck),启动后,观察数据量仍从最早位置启动
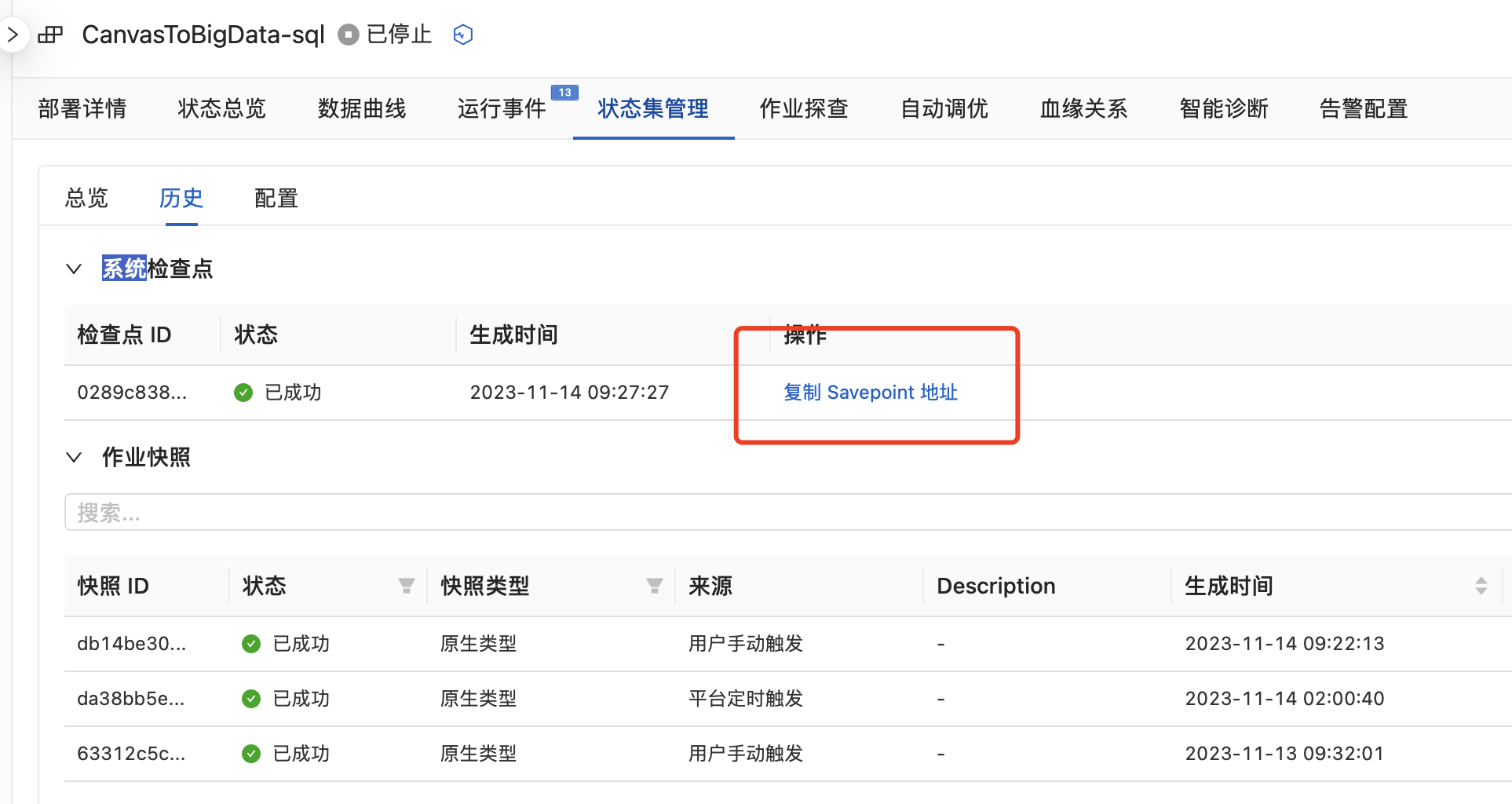
检查点数据也是存在的
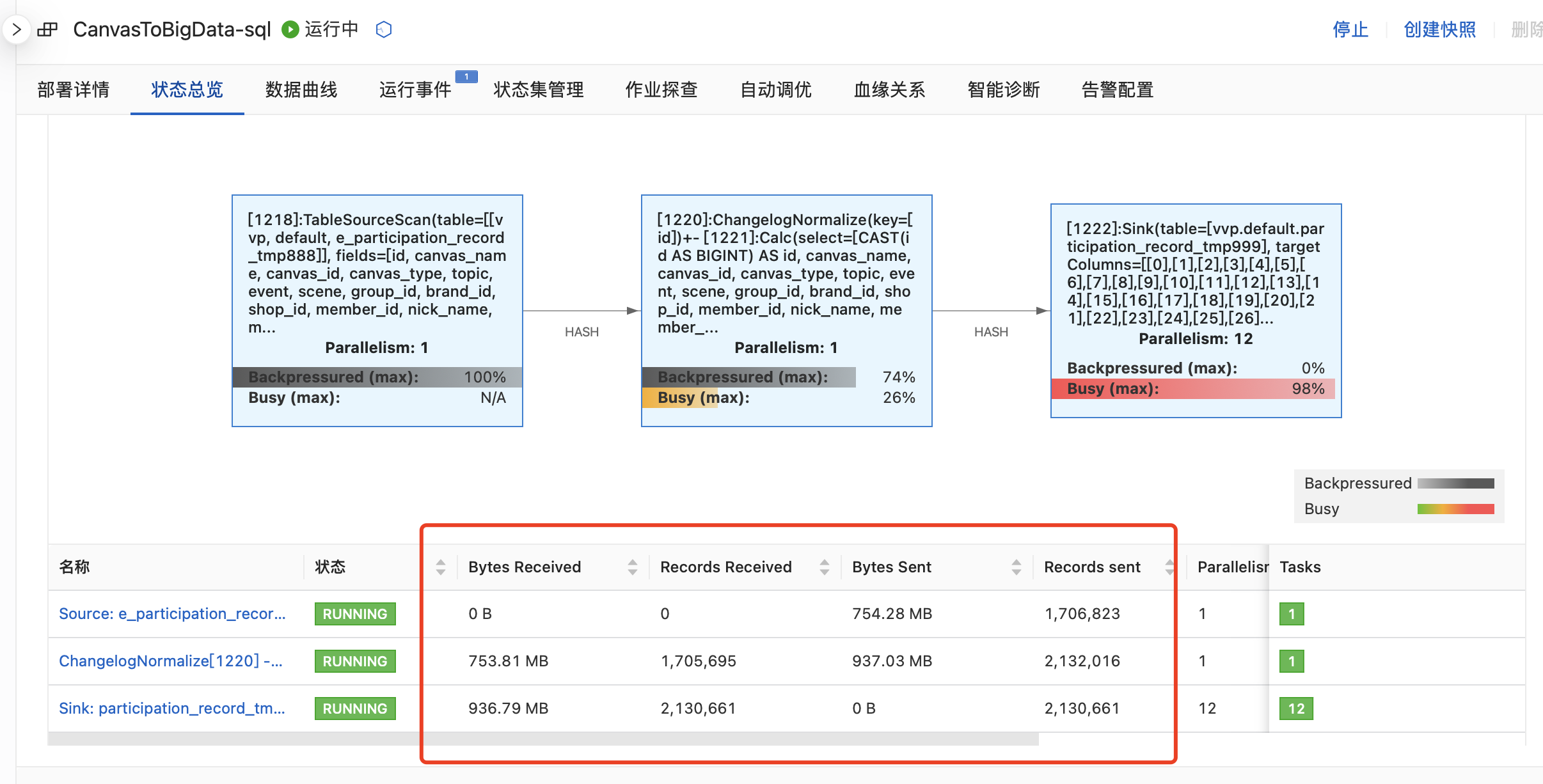
启动后看着还在跑全量数据
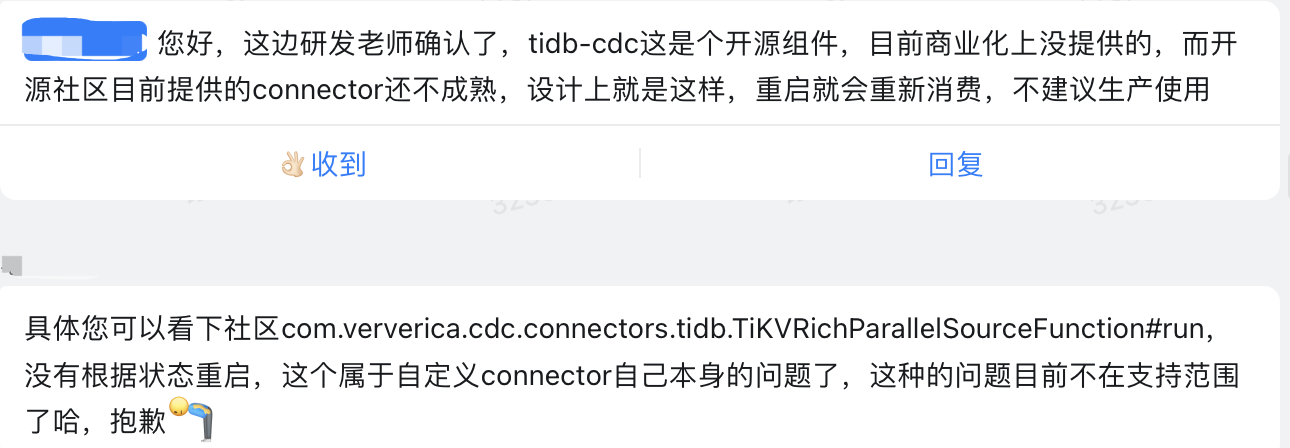
阿里云支持排查原因:
大家是否有遇到一样的问题呢?
按理说一个支持实时增量数据读写的连接器,从checkpoint重新读数据是基础功能。
可以去确认一下最新版本的 connecttor 是否支持从checkpoint重启,是否需要额外的配置才能开启。
xfworld
(魔幻之翼)
4
换个模式会好一些:
采用官方的 ticdc 组件,对接下游的 kafka,然后在接 flink,如下图:
tidb → tikv → ticdc → kafka → flink → N
数据变更事件都暂存于 kafka,flink 可以很容易的从kafka进行消费和处理
ticdc 会和PD 的 TSO 同步,会有变更状态的跟进… 只需要管理好,ticdc → kafka 的通讯管道即可
可以参考看看…
PS: flink-connector-tidb-cdc 是apache flink cdc 社区的作品,不是 tidb社区的…
如果有可能的话,后面看有没有机会改进一下…
消息终结者
5
如果接入ticdc,对公司来说耗费资源太大,不会被采纳 
flink-connector-tidb-cdc 用的已经是最新的了
消息终结者
6
用的已经是最新的连接器版本了,这边试了下用一个小表作为源,第一次跑完吧目标表数据清空,二次根据ck重启任务,目标表数据全量的
xfworld
(魔幻之翼)
7