【 TiDB 使用环境】生产环境
现象与尝试
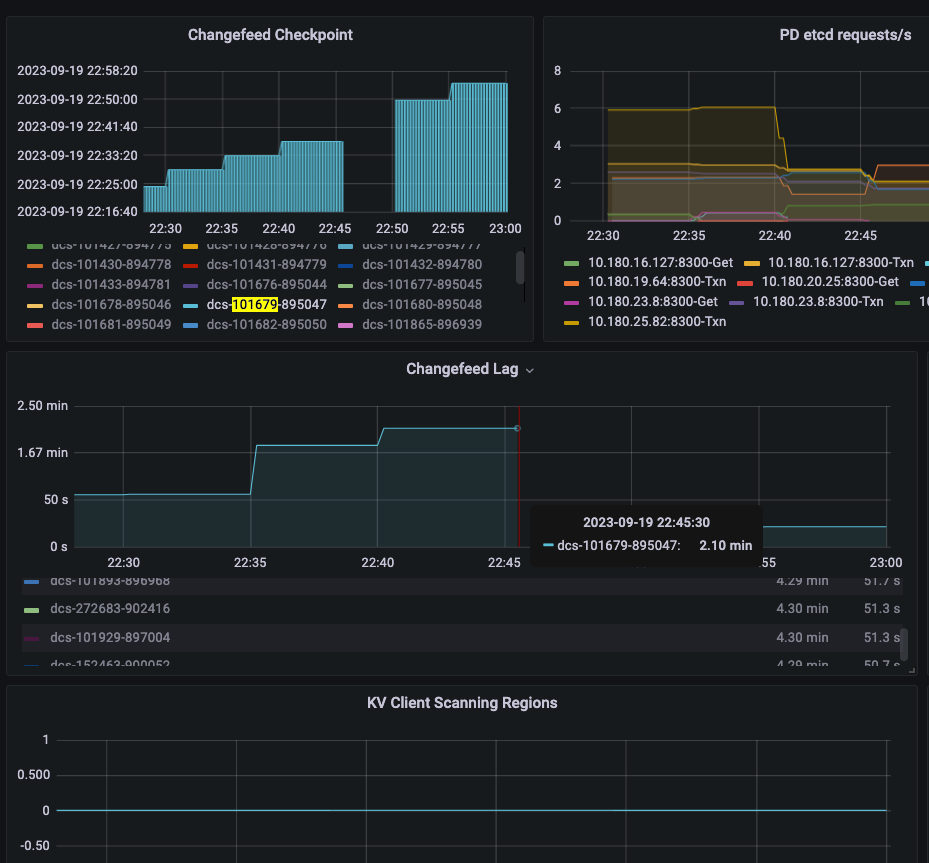
丢数集中在个别几个集群,每次都伴随着对应的changefeed “重启”, 因为metric重置了,伴随着延迟(从几分钟到几小时不等,最后大概率会自动恢复)与大概率的region scanning(下面这个例子就没有观察到region scanning)
图中时间段内数据有74条投递成功,但是实际puller,sink收到了76条,最终下游还是没有收到这2条数据,topic中没有。
单纯从延迟的日志情况上看有大量“synchronize is taking too long, report a bug”,没有特别的error日志TiCDC同步卡住,提示:GetSnapshot is taking too long, DDL puller stuck?
通过对TiCDC内部puller与sink的metrics以及自己加的计数统计,数据有发送到puller与sink ,但是没有投递kafka成功(但也没有观察到sarama的报错),结果来看changefeed崩了重启之后没有重新发送以保证 at least once. 丢的条数按比例来说不多,集中在延迟的某个时间段内。
TiCDC部署在K8S上,对于发生问题的集群,资源都是给够的。
似乎主动的集群重启不会导致数据丢失。
TiKV 侧的监控也没有观察到资源紧张或错误日志,甚至大多时候没有region的明显变动。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
WalterWj
2023 年11 月 14 日 08:29
2
任务重启应该不会导致数据丢失,ticdc 的 task 是有 checkpoint 记录的,重启讲道理是按照 checkpoint 来续传的,可能会多传,最后幂等,但是会少有点奇怪
是不是只是有延迟 不是有丢数。
是,这点非常费解。
WalterWj
2023 年11 月 15 日 02:11
4
如果是这样的话 就比较难排查了,难道是遇到了什么 bug? 确保下游没有人连接执行删除么?
xfworld
2023 年11 月 15 日 02:14
5
下游是hive on hudi,没法变更的。
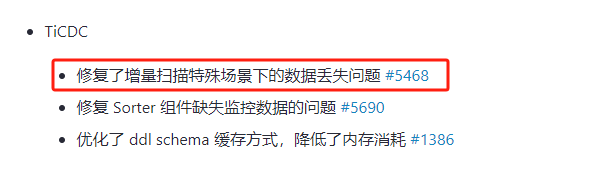
感谢,这个关注到了,之前没有合进来是因为感觉解决的问题不一样,之前以为
观察到的是event的丢失
现在看来也许event并没有丢失。现象还是挺像的
xfworld
2023 年11 月 15 日 03:13
8
最终原因是内部版本改崩了。
这类问题一般就几个思路:
下游发送是否有确认,比如Kafka的ack机制
检查内部puller和sink的event条数是否一致
有异常cdc任务重启的现象时,排查checkpoint在任务重启前(checkpointTs)后(as start-ts)的值,是否真正反映了数据下发的情况
system
2024 年3 月 11 日 03:45
10
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。