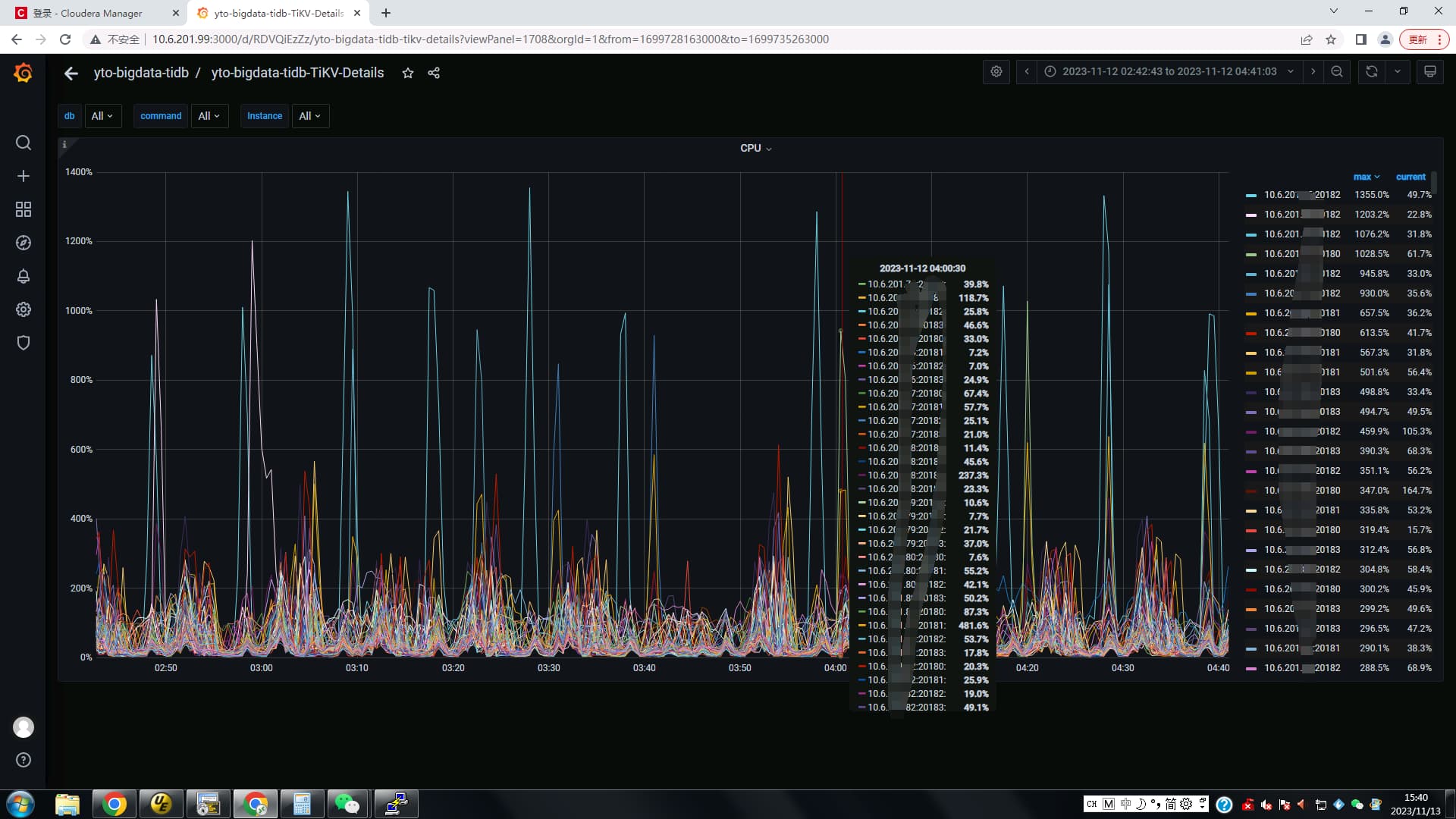
【 TiDB 使用环境】生产环境 ,24个节点,共500T存储,已使用5%。region共10万。
CPU 64vcore。内存512G。4块SSD对应4个tikv实例。
【复现路径】
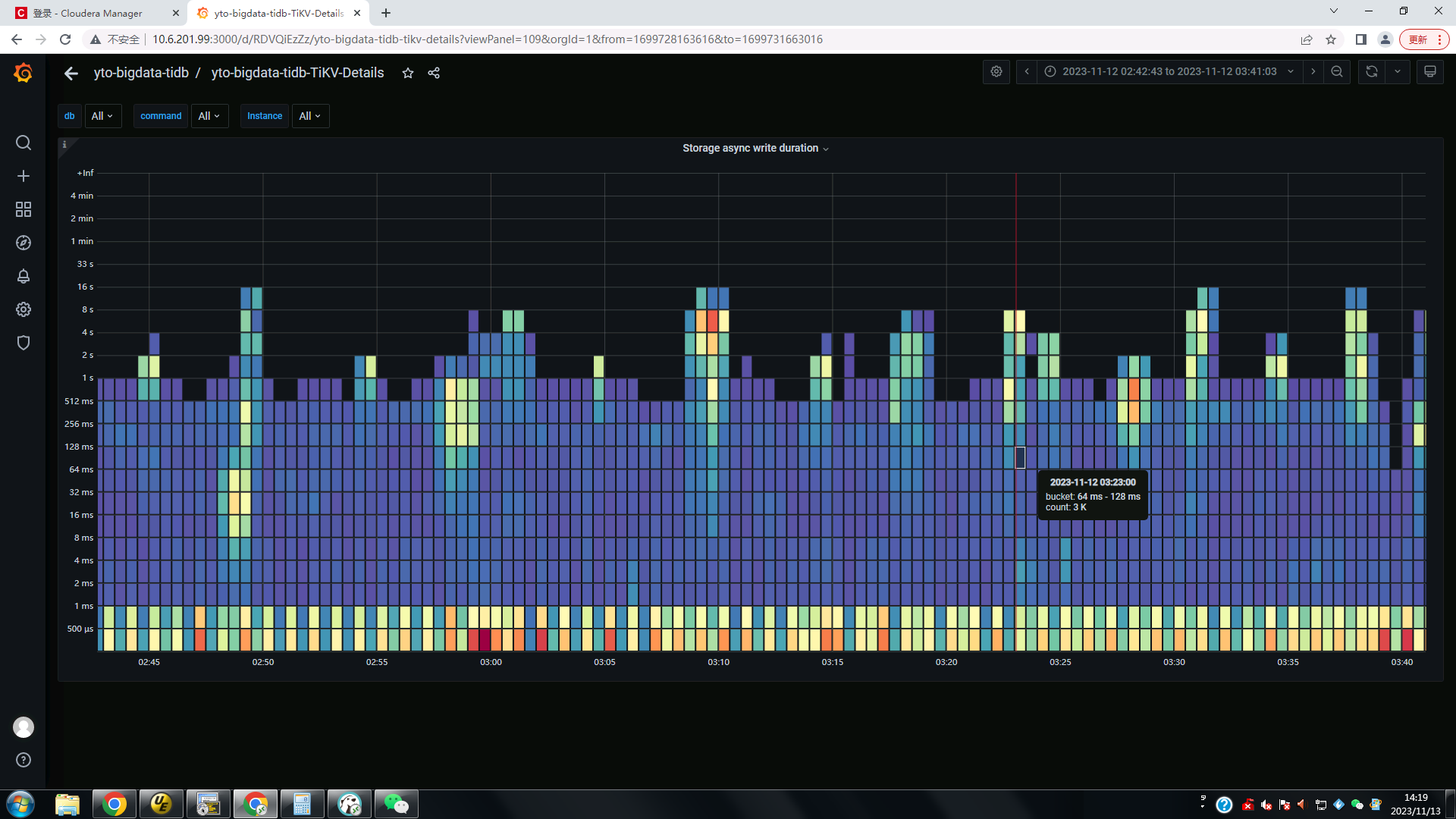
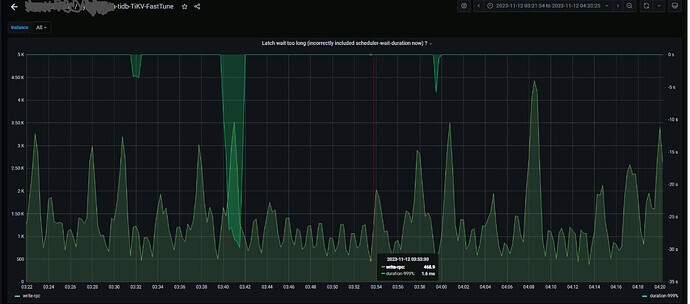
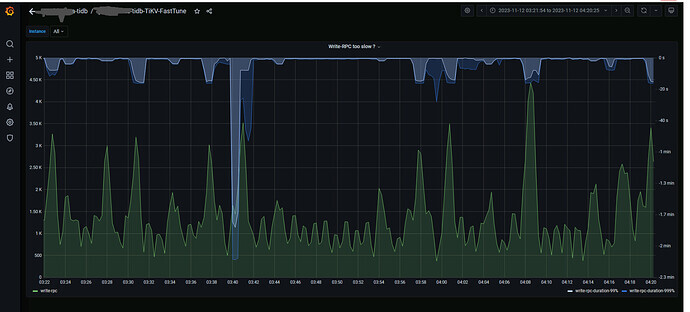
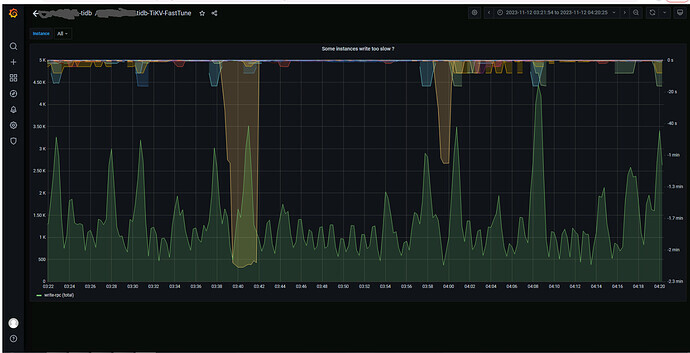
每十分钟写入1200万数据,现在每次在写入时集群延迟非常高,还会很诡异的不时出现在查询表时
table not found , pd不定时切换。
作为实时引擎使用,主要是实时写入,直接读请求很少,主要用tispark分析。
写入时数据经过预处理,无锁冲突。
主要想通过优化apply-pool-size提升。目前是默认值2.