【 TiDB 使用环境】生产环境
【 TiDB 版本】4.0
【复现路径】夜间1点34分报错
【遇到的问题:问题现象及影响】所有节点重启,TIDB服务基本无法提供读写
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
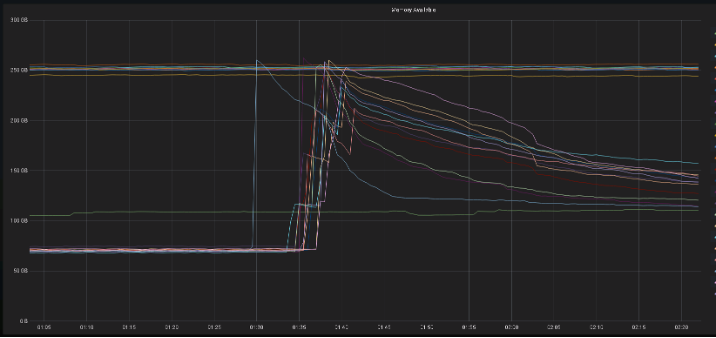
内存剩余量在故障出现的时间,出现大幅度空余,从剩余50G增加到200G
tidb问题排查.docx (56.2 MB)
重启好了没
重启过后,集群恢复正常了
看日志很像网络问题
https://github.com/tikv/tikv/issues/10130
也怀疑过网络问题,查看监控的网络延迟,没有波动,一直挺稳定。看上面链接这个 issue,根据最后的jemalloc报错。可能和 tidb bug有关吧。
版本也太低了,考虑升级吧
网络问题的话,tidb应该不会 重启,所有节点重启。 可能就是集群的bug,不清楚怎么触发
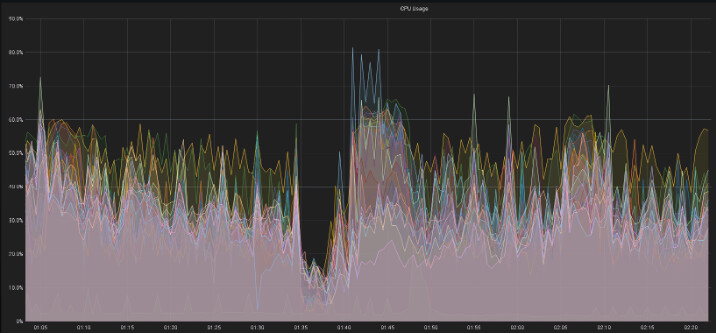
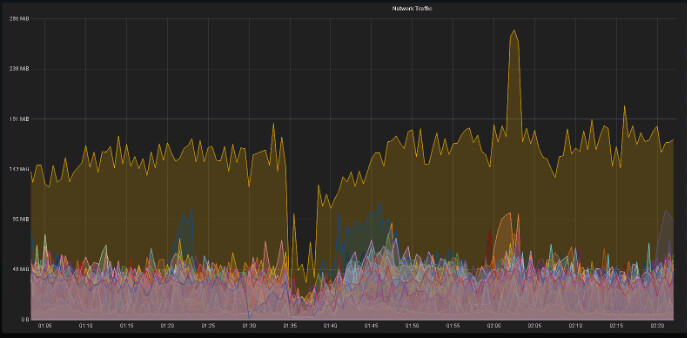
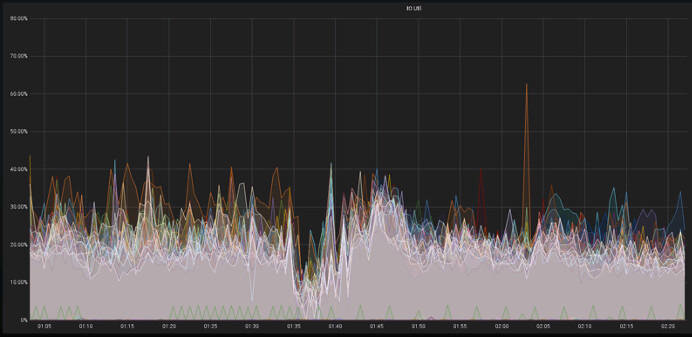
看看集群的资源利用率
1、建议升级
2、故障出现时可用内存增加,应该是节点重启释放了
1 个赞

具体的版本号是多少?
看系统日志应该是网络问题,到软件层面正好相互验证
4.0.13
如果是网络问题的话,不清楚怎么解释,各个节点在那2分钟左右全部重启。是因为大量region没有选出leader,造成集群重启? 或者乐观锁冲突过多,导致重启?(tikv日志里也有很多乐观锁冲突)
建议你小版本升级,,看看 4.0.14 修复的bug

这是 4.0.15 修复的bug
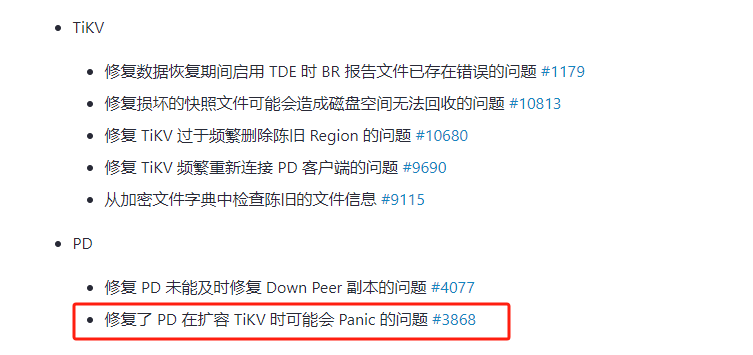
4.0.16
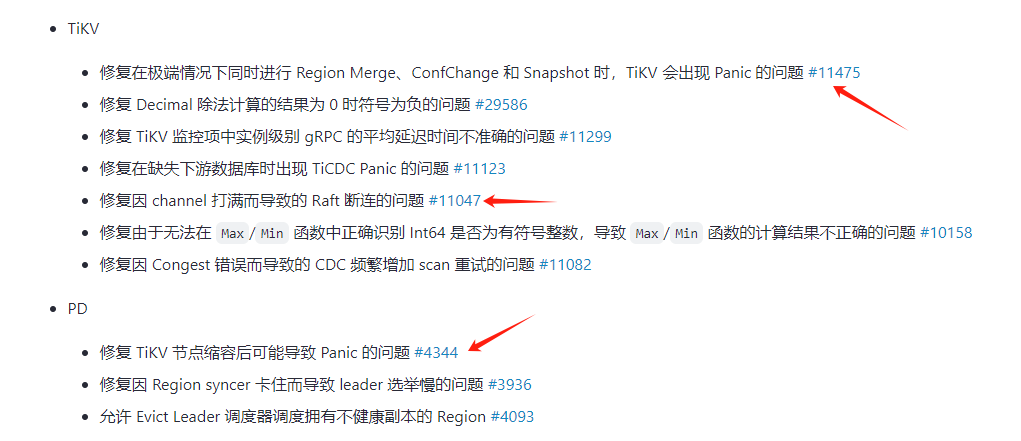
region 的选举和副本数所在的节点有关系的,这个不会造成重启。
乐观锁冲突过多,也不会导致重启…
只有 panic 的情况,会假死… 或者重启
问题原因找到了吗
最后解决了吗?能分享下吗
重启治一切