【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
一个tidb节点故障,机器拿走后,重启了pd, 但pd一直还有原来tidb节点的信息,一直打印这个log
2023/11/09 13:35:45.280 +08:00] [WARN] [proxy.go:181] [“fail to recv activity from remote, stay inactive and wait to next checking round”] [remote=192.168.1.6:4000] [interval=2s] [error=“dial tcp 192.168.1.6:4000: connect: no route to host”]
请问要怎么去掉?
【资源配置】
【附件:截图/日志/监控】
tidb节点从集群下线没
机器故障后连不上了,直接拆走了,scale-in 执行不了, 后面在tiup里改配置把1.6的节点全部去掉后,重启了整个集群,但看pd的log还是有这个节点
在tiup cluster 中可以看到嘛
display看不到了
把部署目录下run_pd.sh里的对应地址去掉 ,滚动重启下Pd
没太理解,之前看过run_pd.sh,但里面没有tidb节点的地址信息
看错了,tidb节点坏了后就只重启了pd,没有做这个tidb节点的缩容吗
缩了,没成功,节点连不上,在stop这步就错了
tiup cluster display看下
后面的状态也截取下,tidb是可以用–force来缩容
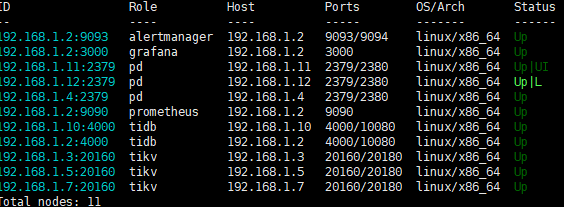
机器都迁走了,那就在执行scale-in时添加 -–force 参数,可以清理掉其在集群内的残留注册信息
节点如果已经损坏了,就直接缩容的时候加–force就会直接删除节点元信息
这是没有缩容成功,手工改配置是不行的,还是需要执行缩容,加上–force强制缩容
1 个赞
走前面老师说的强制下线了么?
scale-in 加force,如果pd还有tidb信息,就需要pd-ctl操作下remove
请问具体命令是什么? 只看到个delete的命令,不知道参数怎么传
https://docs.pingcap.com/zh/tidb/stable/pd-control
我理解错了。是remove是针对tikv的,你加了force执行缩容后,监控里那个pd面板还能看到tidb server吗?