【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.4
【复现路径】tikv 某一个节点重启后,另一个节点开始输出 prepare_write_err 异常。
【遇到的问题:问题现象及影响】集群整体时延上升
【资源配置】8台tikv 机器 24 实例
【附件:截图/日志/监控】
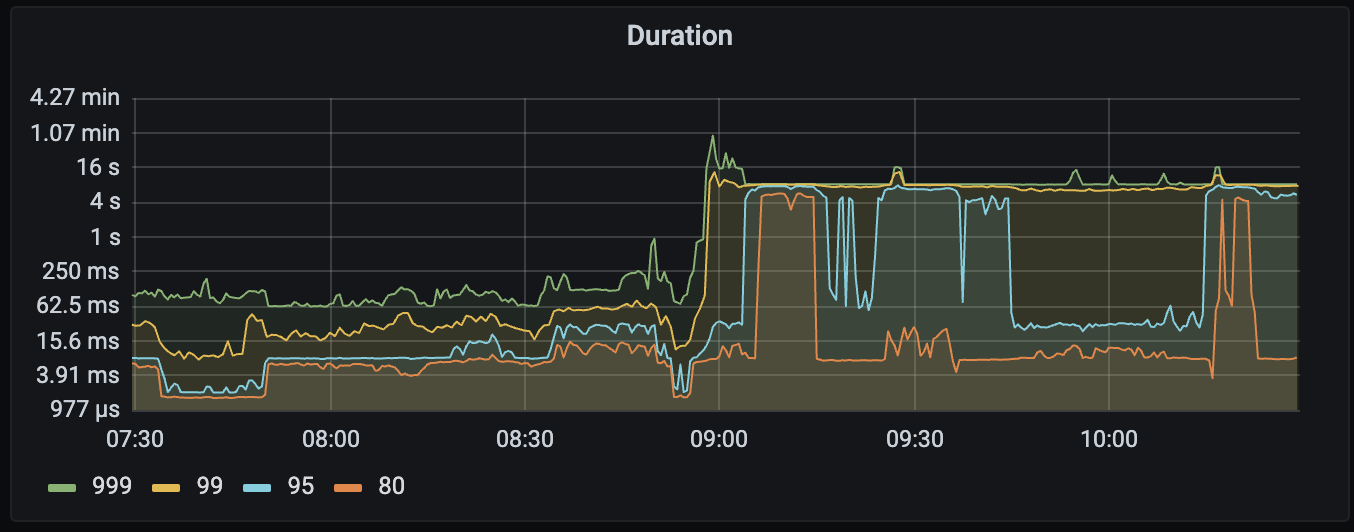
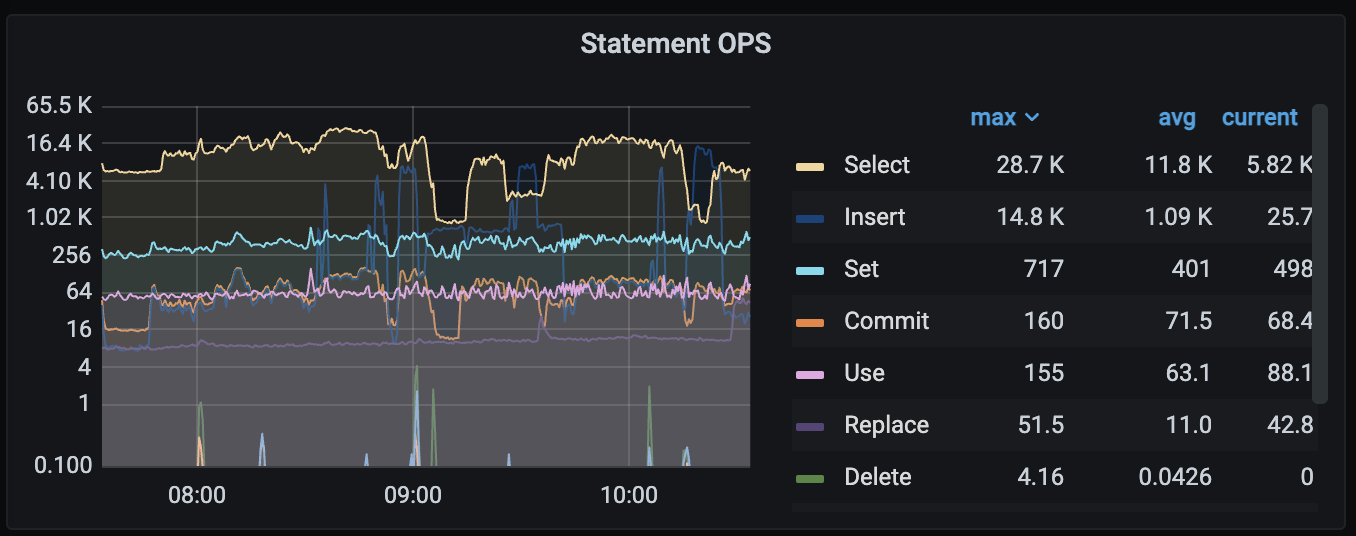

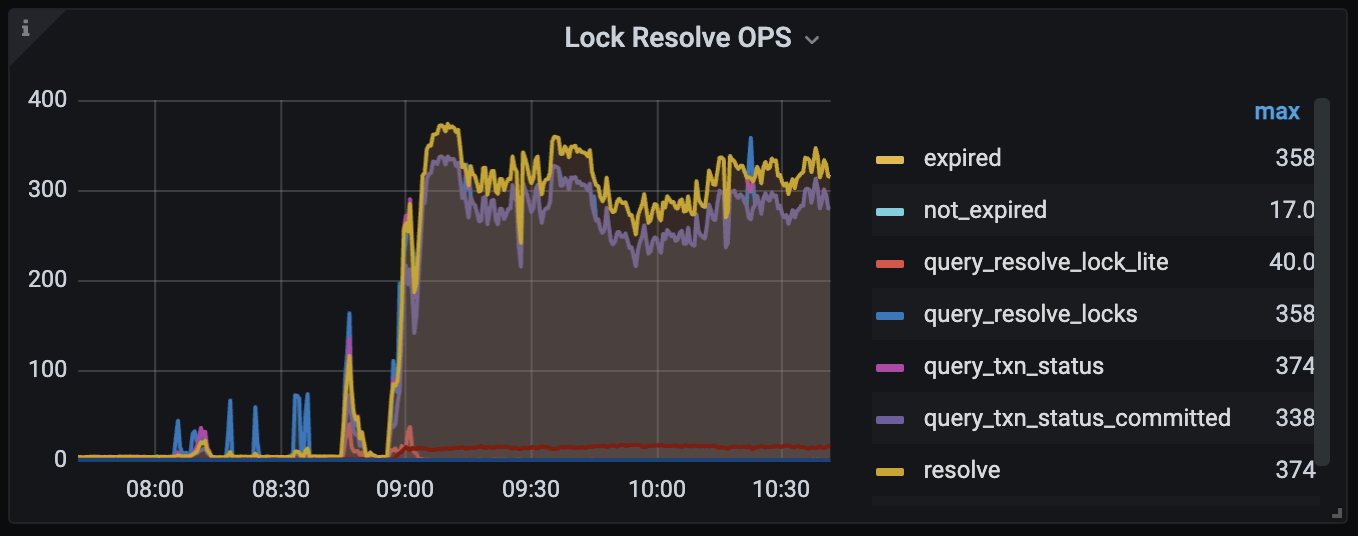
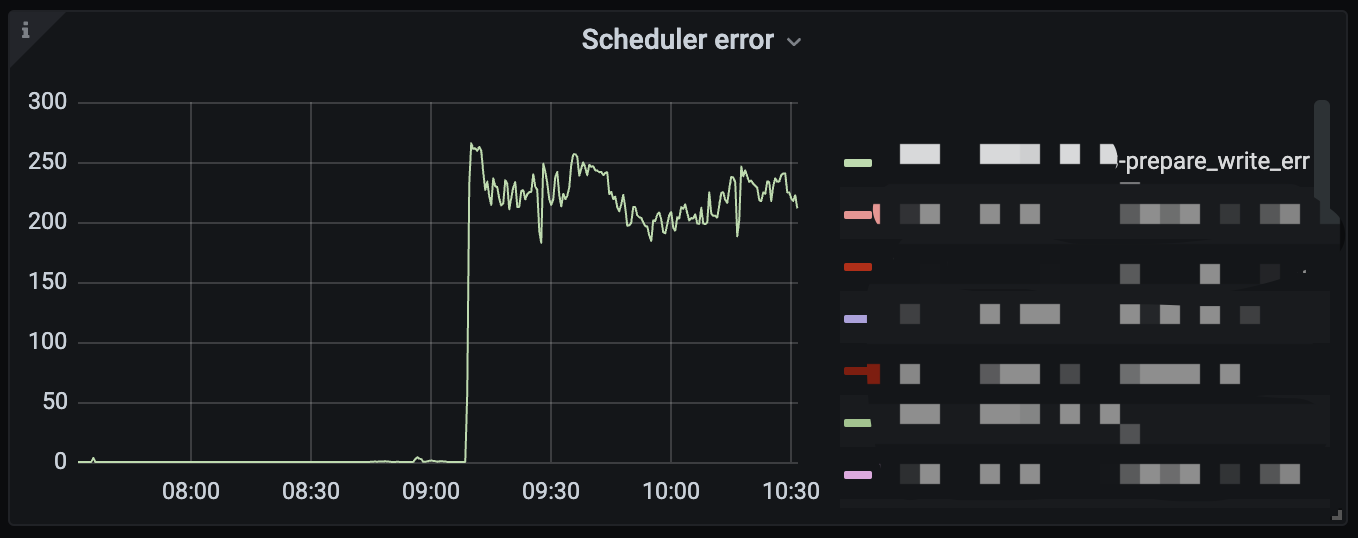
tidb 节点有报错:
[2023/11/09 11:15:08.205 +08:00] [WARN] [session.go:1966] [“run statement failed”] [schemaVersion=233964] [error=“previous statement: update mysql.table_cache_meta set lock_type = ‘READ’, lease = 445513650692423680 where tid = 203252: [kv:9007]Write conflict, txnStartTS=445513651491963030, conflictStartTS=445513651491963037, conflictCommitTS=0, key={tableID=57, handle=203252} primary=[]byte(nil) [try again later]”] [session=“{\n "currDBName": "",\n "id": 0,\n "status": 2,\n "strictMode": true,\n "user": null\n}”]
[2023/11/09 11:15:08.205 +08:00] [WARN] [cache.go:205] [“lock cached table for read”] [error=“previous statement: update mysql.table_cache_meta set lock_type = ‘READ’, lease = 445513650692423680 where tid = 203252: [kv:9007]Write conflict, txnStartTS=445513651491963030, conflictStartTS=445513651491963037, conflictCommitTS=0, key={tableID=57, handle=203252} primary=[]byte(nil) [try again later]”]