yuqi1129
(Yuqi1129)
1
TiDB 在commit 阶段会清锁并写入版本数据, 这两个操作能保证原子的吗?
TiDB 编码大致如下:
Data column
${key}${start_ts} —> ${value}
version column:
${key}${commit_ts} → ${start_ts}
lock column
${key}–>${start_ts,primary_key,…etc}
commit 阶段,primary 会将lock column 的锁信息清掉并将commit_ts写入version column, 这应该是两个不同的row, 对于rocksdb来说并不能保证这两个操作的原子性(两行可能落在不同的region上, region内应该是可以保证原子性的, 跨region应该不能), 哪位大佬能帮忙解惑一下
WalterWj
(王军 - PingCAP)
2
可以,因为锁是任意选一行加 primary lock,其他锁都是指向锁,相当于一个定向。主锁清理之后,其他指向锁异步清理。查的时候会确认指向锁 指向的 lock 是否存在,所以跨 region、节点没问题。
1 个赞
yuqi1129
(Yuqi1129)
3
primary 会将lock column 的锁信息清掉并将commit_ts写入version column
清理锁与写version column 这个由于不是同一个row, 不能确保会落在同一个region上, 不能保证原子性吧?
我是哪里的上下文没有get 到么
yuqi1129
(Yuqi1129)
5
大佬, 我说的是commit 阶段修改primary的lock的commit_ts 和 version column。
关于指向锁我明白, 只要primary 修改成功了, 事务就成功了, secondarys 可以异步完成, 即使失败了也没有关系, 有指向primary的标记
Percolator 中 lock列和version列信息共享同一个row_key, 对同一行的不同cf修改确实是原子的。 TiDB上面我看
lock列与version列用的是不同的row_key, 怎样能保证是原子的?
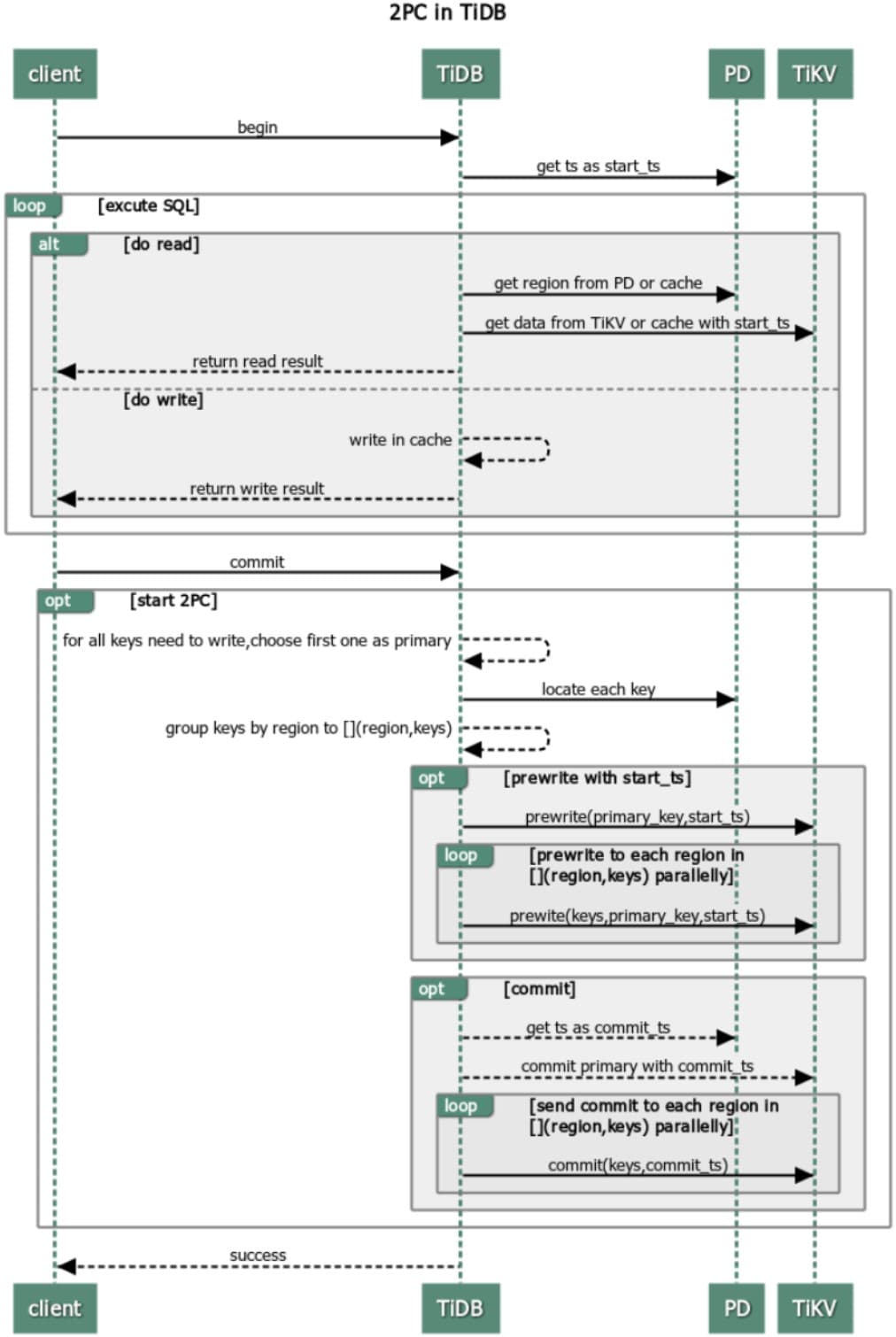
两阶段提交2PC
RocksDB Column Family 简称:
D 列:rocksdb.defaultcf
L 列:rocksdb.lockcf
W 列:rocksdb.writecf
事务提交前,会在 TiDB 缓存所有数据。这边有遇到过同时并发写入上百MB数据,结果导致 TiDB OOM。
1、TiDB 从当前要写入的行中选择一个 Key 作为当前事务的 Primary Key,剩于的 Keys 为 secondary
2、TiDB 从 PD 获取所有数据的写入路由信息,并将所有的 Key 按照路由进行分类
3、TiDB 发起 prewrite 请求,将Primary Key与数据写入到 TiKV,并进行加锁【加锁前会检查是否有写入冲突】,
加锁成功后执行下面操作:
(1) 锁信息写入L列,示例:<1,(W,pk,1,100 … )>
(2) 行数据写入D列,示例:put<1_100,‘相亲相爱一家人’>
4、然后 Secondary Key 并发地向所有涉及的 TiKV 发起 prewrite 请求,流程同 Primary Key 类似
区别是锁信息指向了 Primary Key :
(1) 锁信息写入L列,示例:<2,(W,@1,2,100 … )>
5、TiDB 收到所有 prewrite 都成功
6、TiDB 向 PD 获取 commit_ts
7、TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交的 Commit
(1) 写入 W 列,示例:put<1_110,100>
(2) 删除 L 列,示例:<1,(D,pk,1,100 … )>
(3) 最后清理锁信息
8、Primary Commit 提交成功后,Secondary 可以进行异步提交
9、TiDB 收到两阶段提交成功
【加锁前会检查是否有写入冲突】
- 检查 L 列,是否已经有别的客户端已经上锁 (Locking)
- 检查 W 列,在本次事务开始时间之后,是否有更新 [startTs, +Inf) 的写操作已经提交 (Conflict)
Prewrite 出现冲突,当前事务回滚。
Primary Commit 出现冲突,全事务回滚。
yuqi1129
(Yuqi1129)
8
7、TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交的 Commit
(1) 写入 W 列,示例:put<1_110,100>
(2) 删除 L 列,示例:<1,(D,pk,1,100 … )>
(3) 最后清理锁信息
整个第7步是原子的吗? (1)成功了(2) 失败了怎么办?还是说整个1,2,3是一个原子操作, 那这个原子操作如何实现? W、L列的row_key不一样, 不能保证落到同一个region中吧?
yuqi1129
(Yuqi1129)
11
我明白了, 还是利用同一行不同cf可以原子更新的机制。
yuqi1129
(Yuqi1129)
12
我再多问一个问题, 目前Rocksdb不能像Hbase那样支持存多版本数(CF 上同时存个版本的值), 上面你说的write列,是如何保存多版本的?所有的版本数据写在一起,读的时候时候全部捞出来吗?如果是这样如何快速根据读快照找捞到可读的版本?
rocksdb的底层实际上是一堆key-value键值对,TiDB中TiKV的数据存储的多版本数是通过MVCC实现的,通过在 Key 后面添加版本号来实现的,举例如下:
没有 MVCC 之前,
Key1 → Value
Key2 → Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1_Version3 → Value
Key1_Version2 → Value
Key1_Version1 → Value
……
Key2_Version3 → Value
Key2_Version2 → Value
Key2_Version1 → Value
……
对于同一个 Key 的多个版本,版本号较大的会被放在前面,版本号小的会被放在后面,这样当用户通过一个 Key + Version 来获取 Value 的时候,可以通过 Key 和 Version构造出MVCC的Key,也就是Key_Version。然后可以直接通过 RocksDB的SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
当用户确信自己需要更长的读取时间时,比如在使用了 Mydumper 做全量备份的场景中(Mydumper 备份的是一致性的快照),可以通过调整 TiDB 中mysql.tidb表中的tikv_gc_life_time的值来调大 MVCC 版本保留时间,需要注意的是tikv_gc_life_time的配置是立刻影响全局的,调大它会为当前所有存在的快照增加生命时长,调小它会立即缩短所有快照的生命时长。过多的 MVCC 版本会拖慢 TiKV 的处理效率。
针对每个key存储多个版本的数据,怎么表示版本信息呢?
在TiKV中,我们只是简单地将key和timestamp结合成一个internal key来存储在RocksDB中。下面是每个CF的内容:
F_DEFAULT: (key,start_ts) → value
CF_LOCK: key → lock_info
CF_WRITE: (key,commit_ts) → write_info
将key和timestamp结合在一起地方法如下:
将user key编码为 memcomparable 的形式;
对timestamp按位取反,然后编码成big-endian的形式;
将编码后的timestamp添加到编码后的key之后。
例如,key key1和时间戳 3 将被编码成 “key1\x00\x00\x00\x00\xfb\xff\xff\xff\xff\xff\xff\xff\xfe”。这样同一个Key的不同版本在rocksdb中是相邻的,且版本比较大的数据在旧版本数据的前面。
system
(system)
关闭
16
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。