【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.0
【复现路径】增加 spark 并行执行的 task 数时报错
【遇到的问题:问题现象及影响】我尝试用 spark 解析大小为 30GB ,约 2.7 亿条数据的 csv 文件到 TiDB,目标表有约一亿条数据,多个普通索引及一个唯一索引,写入代码如下
csvDataFrameTime.write.format("org.apache.spark.sql.execution.datasources.jdbc2").options(
Map(
"savemode" -> JDBCSaveMode.Update.toString,
"driver" -> "com.mysql.cj.jdbc.Driver",
"url" -> (DBConf.TIDB_TEST.get("url").get + dbConfigMap.get("dbName").get + "?rewriteBatchedStatements=true&autoReconnect=true&allowMultiQueries=true&serverTimezone=UTC"),
"user" -> DBConf.TIDB_TEST.get("user").get,
"password" -> DBConf.TIDB_TEST.get("password").get,
"dbtable" -> dbConfigMap.get("tableName").get,
"batchsize" -> "10000", # 此处是为了适配这个csv文件,将1000调整为10000后每个task的执行速度快了一倍
"useSSL" -> "false",
"showSql" -> "true"
)
).save()
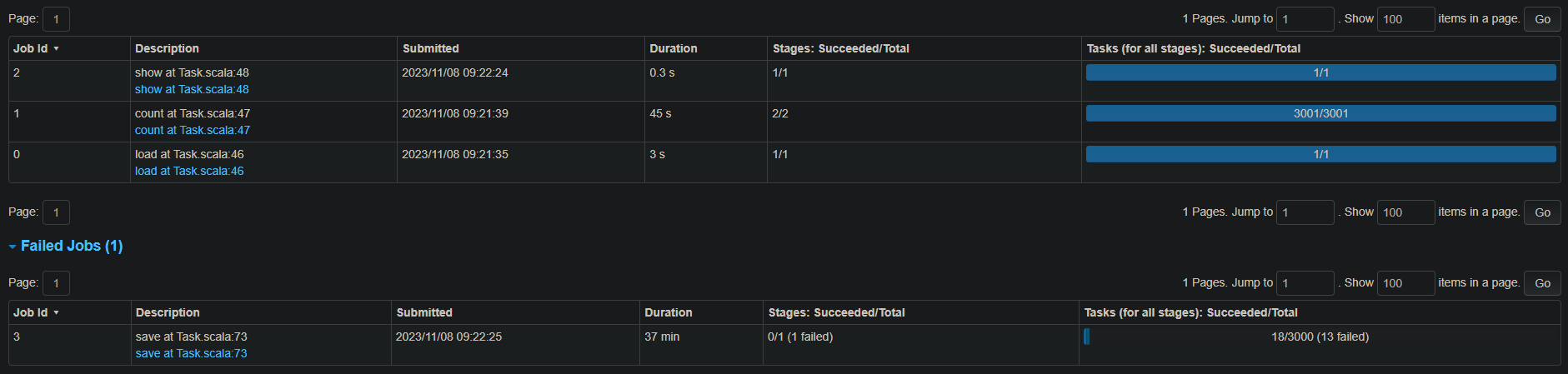
当我使用 spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 --master yarn --deploy-mode cluster --executor-cores 1 --num-executors 10 --executor-memory 2GB --conf spark.default.parallelism=3000 --class com.process.Task /dispose/spark/csvProcess 命令执行代码时,程序正常运行,同时执行十个task,速度约为 21万条元数据每小时每task
注:spark.default.parallelism=3000 是为了切分数据以不触发 TiDB 的事务限制和悲观锁报错
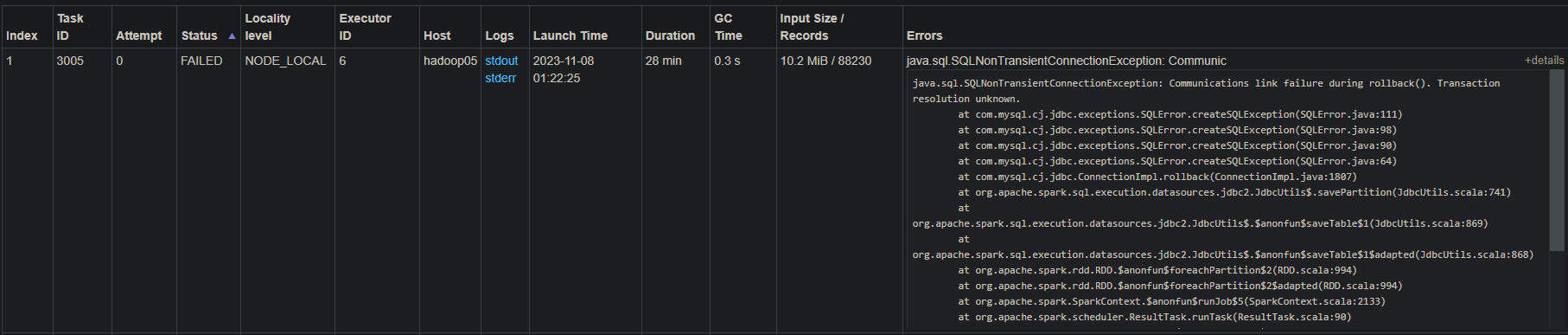
为了提高整体执行速度,我尝试分配更多的资源以并行执行更多的 task,例如使用 spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.0 --master yarn --deploy-mode cluster --executor-cores 2 --num-executors 10 --executor-memory 4GB --conf spark.default.parallelism=3000 --class com.process.Task /dispose/spark/csvProcess 执行,此时并行执行20个task,就会在执行成功十几或几十个task后开始集体报 java.sql.SQLNonTransientConnectionException: Communications link failure during rollback(). Transaction resolution unknown. 导致spark整体失败,我应该怎样才能并行执行更多的 task 而不触发此报错?
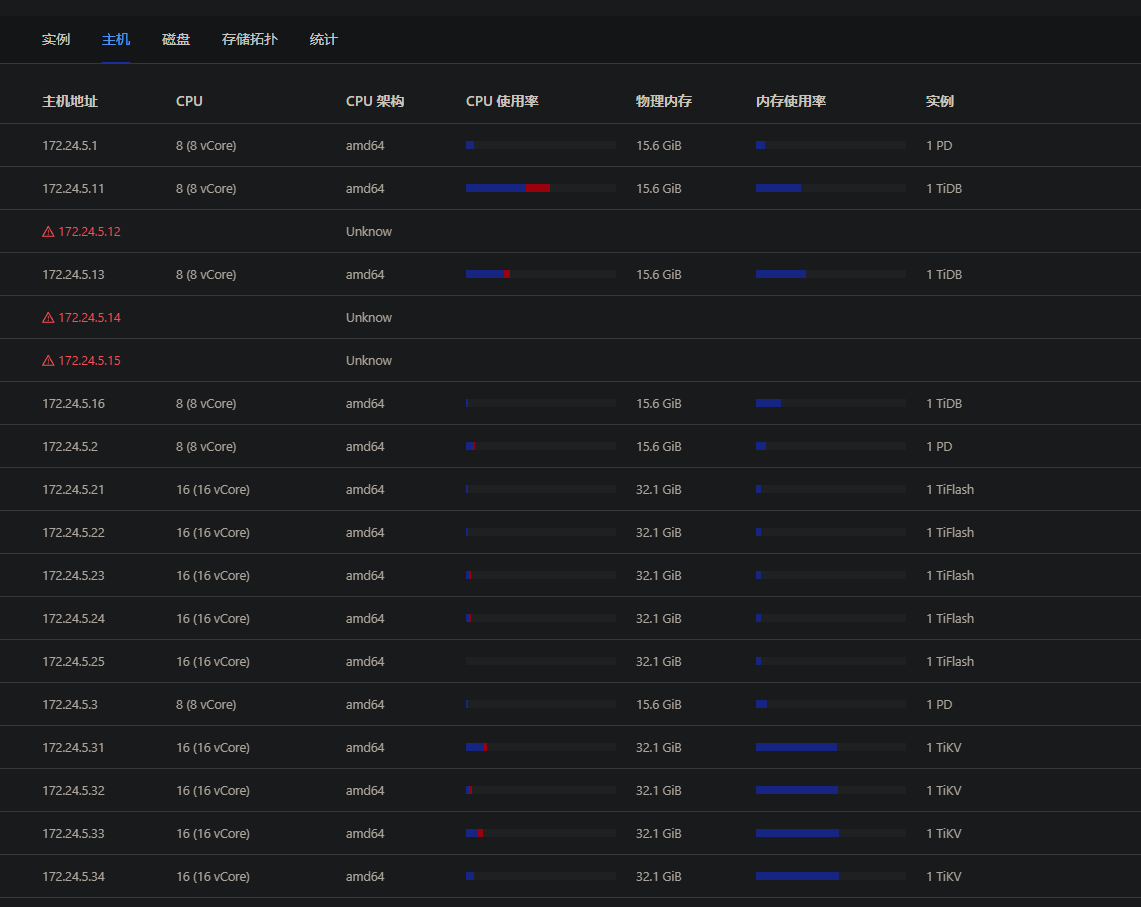
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
注:下方为20个 16C 32G 的 TiKV
【附件:截图/日志/监控】
spark 报错信息及执行信息