hzc989
(Hzc989)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.7
【复现路径】N/A
【遇到的问题:问题现象及影响】
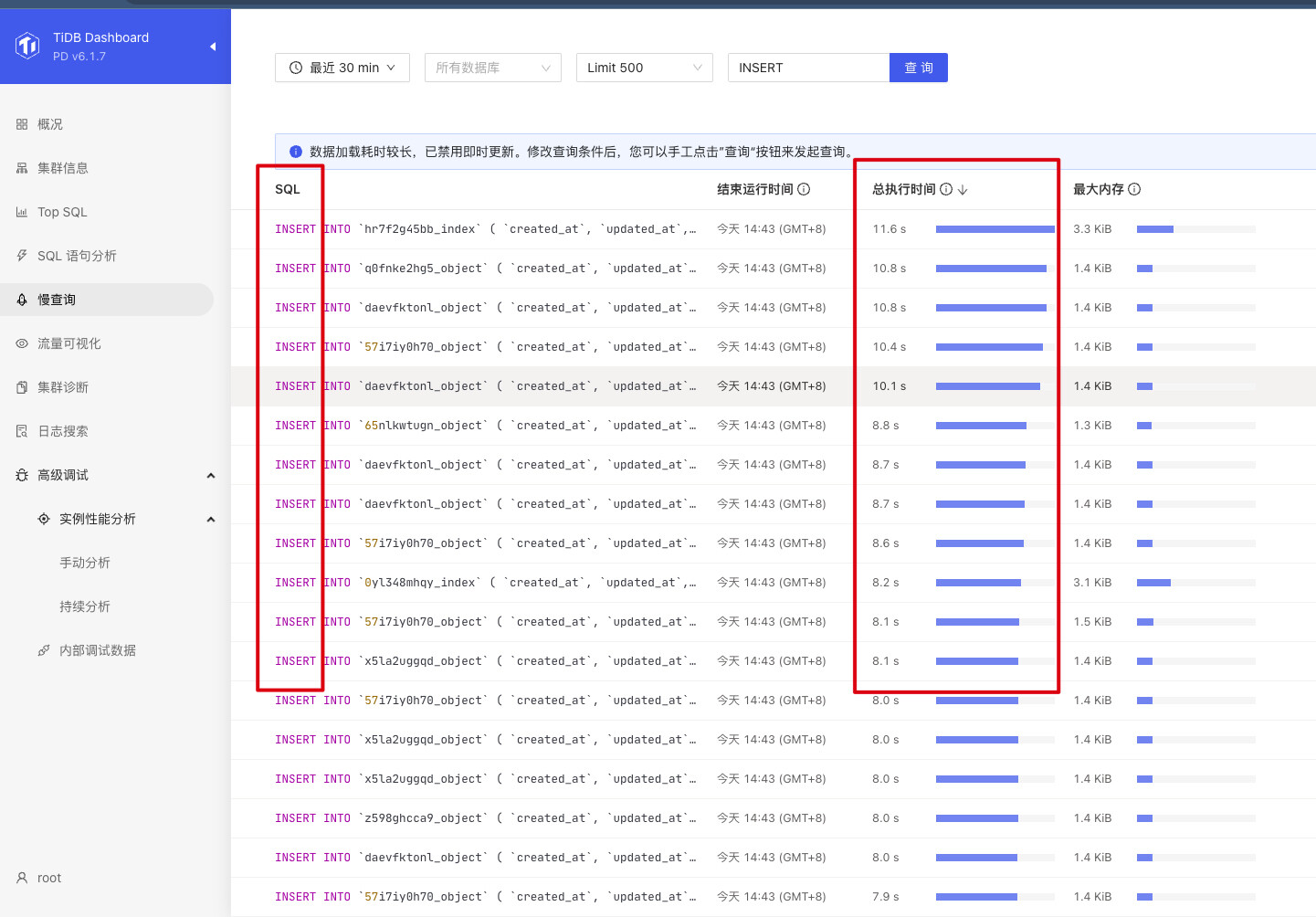
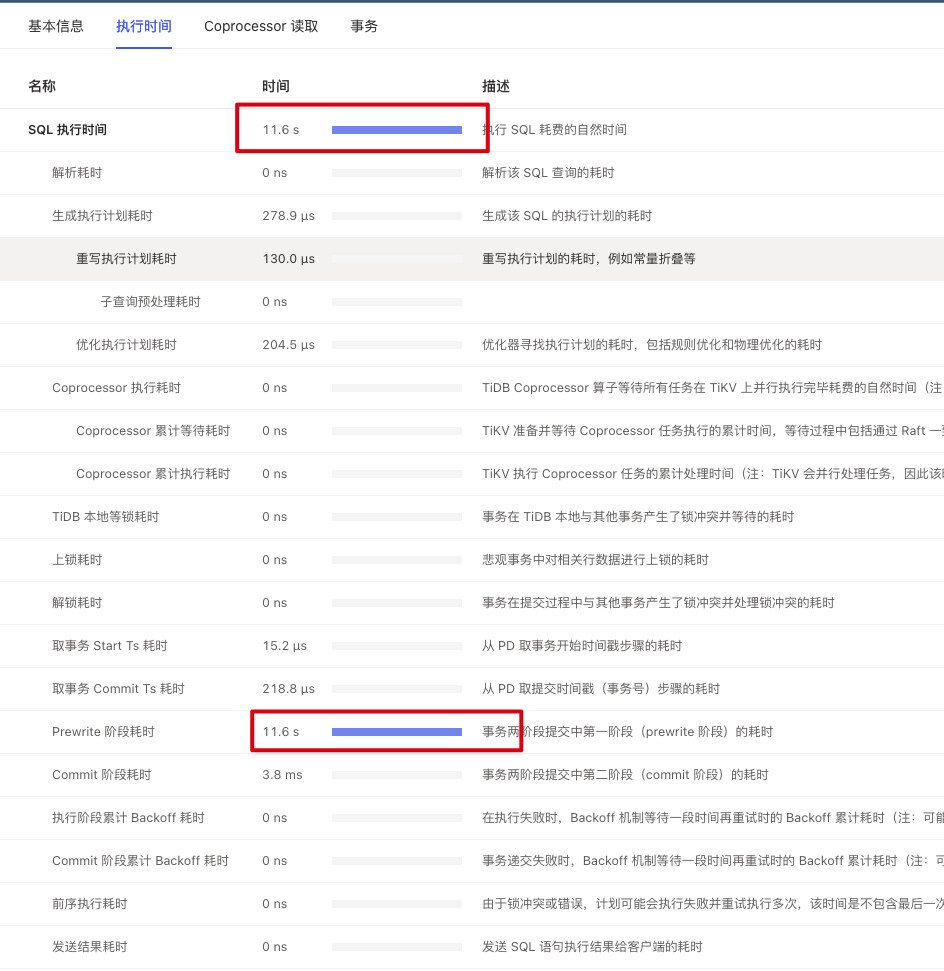
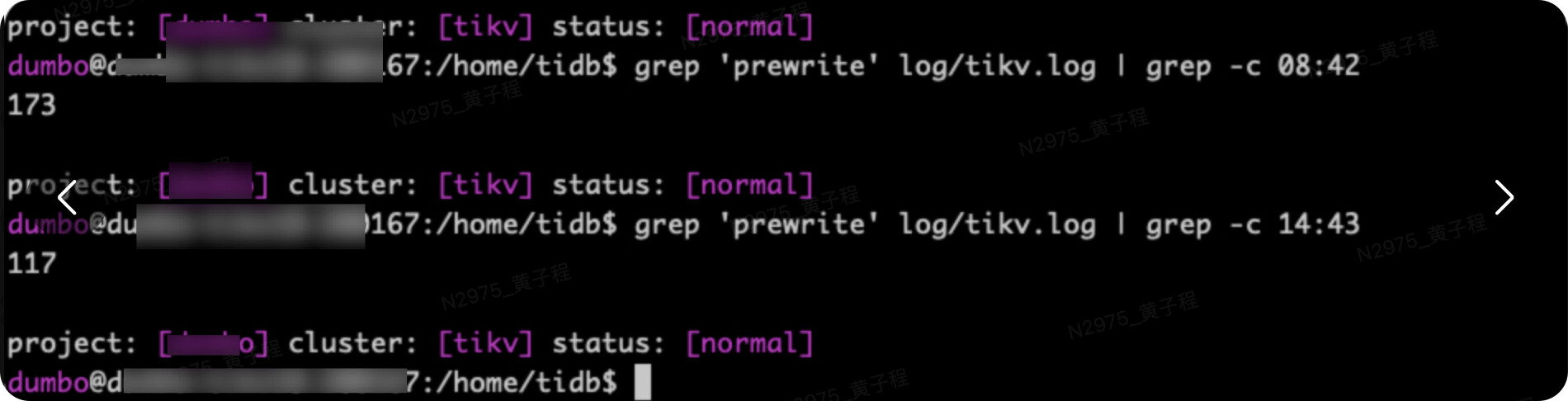
表现:线上偶发出现突然 SQL 请求变慢,排查定位后发现,出现时间点都是跟某个 TiKV store 出现大量 prewrite 报错有关,如下附图
【资源配置】
【附件:截图/日志/监控】
具体日志为:
[2023/11/07 08:42:44.631 +08:00] [WARN] [prewrite.rs:630] ["commit_ts is too large, fallback to normal 2PC"] [lock="Lock { lock_type: Put, primary_key: 748000000000011F3B5F698000000000000001017765766670613676FF3531373231373231FF3638393539313730FF383132373233325FFF64616576666B746FFF6E6C5F315F686663FF33365F733376322EFF646174612E313530FF2E31000000000000F9, start_ts: TimeStamp(445465955077456458), ttl: 3000, short_value: C000000B673C7FB3, for_update_ts: TimeStamp(0), txn_size: 1, min_commit_ts: TimeStamp(445465955077456459), use_async_commit: true, secondaries: [748000000000011F3B5F724000000B673C7FB3], rollback_ts: [] }"] [max_commit_ts=445465955601744458] [min_commit_ts=445465956086710572] [start_ts=445465955077456458] [key=748000000000011FFF3B5F698000000000FF0000010177657666FF70613676FF353137FF3231373231FF3638FF393539313730FF38FF3132373233325FFFFF64616576666B746FFFFF6E6C5F315F6866FF63FF33365F733376FF322EFF646174612EFF313530FF2E310000FF00000000F9000000FC]
另外看到tikv文档上,在 6.5 之后有一个新的参数enable-async-apply-prewrite,文档地址,从描述来看和这个问题有比较大的关联性,但我们找不到更进一步描述这一块内容的相关资料。想确认下是否存在 prewrite 慢导致偶发的请求延迟增大问题,是否可以升级到 6.5 ,使用这个新参数来改善相关问题?
xfworld
(魔幻之翼)
2
不建议升级,先看看是什么问题导致的数据竞争,产生了大量的 lock…
然后尝试看看,通过不同的路径解决这个竞争问题
生产环境要升级,要先 poc …
1 个赞
先不着急升级。
2PC的第一阶段prewrite主要是做数据的版本MVCC检查、写操作的锁冲突检测这几个事情。
zc 你这个问题看起来是大量insert 语句短时间同时插入,导致出现大量lock竞争,看看有没有可能从业务这一侧来进行调整SQL或者先降低并发量。
看一下coprocess图,是不是统计日志引起的资源占用
748000000000011FFF3B5F698000000000FF0000010177657666FF70613676FF353137FF3231373231FF3638FF393539313730FF38FF3132373233325FFFFF64616576666B746FFFFF6E6C5F315F6866FF63FF33365F733376FF322EFF646174612EFF313530FF2E310000FF00000000F9000000FC
这是哪个表的主键?是你们自己生成的?
并行插入锁表等待。。。。
lock_type: Put
查询写冲突的那个表有什么事务造成锁等待
hzc989
(Hzc989)
12
感谢文杰大佬支持。最主要是业务没有特别的变化,日常一直都是这么并发插入的,就是有那么一些时间会存在这种问题
参考这个帖子,prewrite时间较长可能会导致出现这个报错。一般是 1PC或 aysnc commit 情况下,Prewrite时会根据写的key计算min_commit_ts,最后选择最大的作为commit_ts ,为保障start_ts → commit_ts间 schema的一致性,tidb增加了一个max_commit_ts,max_commit_ts以Prewrite+2秒的时间计算,当min_commit_ts超过max_commit_ts后 就会报 commitTStoolarge错误,然后回退到2PC提交模式。
所以,可以看看下集群当时的系统负载、磁盘IO压力,raft 线程CPU利用率、组件间的网络延迟等情况,再一起分析分析。
1 个赞
hzc989
(Hzc989)
14
目前并没有定位到明显的 CPU、内存、磁盘 IO 资源瓶颈点,这个问题比较诡异。要说是锁冲突等待,也跟业务确认过,事发时不存在并发的重复插入
hzc989
(Hzc989)
15
您问的 insert 类型指的是?这个表只有两个索引,一个是是主键(聚簇索引),还有一个业务上用的唯一索引。
我这边遇到类似的情况,也是时间消耗到prewrite,但是没有你这么长时间,我这边的的插入是这种形式 insert into … on duplicate key update,至今还没有找到是什么原因导致 prewrite消耗这么长时间 。
1.是否是乐观模式的事务,降少并发写
2.使用悲观模式
hzc989
(Hzc989)
20
悲观模式来的。大家都提到这个减少并发,我没理解,是怎么影响到的这个问题的,平时业务一直是高并发写入的,现在是偶发出现的,找不到其他问题迹象,也没定位到性能瓶颈点。