我在查询tidb时,部分请求特别慢,我看了执行计划,差别在这里
{num: 8, max: 7.05s, min: 1.26ms, avg: 885ms, p95: 7.05s, max_proc_keys: 9184, p95_proc_keys: 9184, tot_proc: 7.07s, rpc_num: 8, rpc_time: 7.08s, copr_cache_hit_ratio: 0.00, distsql_concurrency: 80}
{num: 4, max: 3.28ms, min: 1.25ms, avg: 1.89ms, p95: 3.28ms, max_proc_keys: 2016, p95_proc_keys: 2016, tot_proc: 3ms, rpc_num: 4, rpc_time: 7.47ms, copr_cache_hit_ratio: 0.00, distsql_concurrency: 80}
核对了实行快的和执行慢的sql ,发现执行快的基本上读取tikv时都是4个线程,慢的全部是8个线程,是有推测执行或者重试机制吗
h5n1
(H5n1)
2
cop num不一样 说明请求的数据量也是不一样的 最好能完整贴下2个SQL执行计划,另外可以trace看下 慢在哪个region上
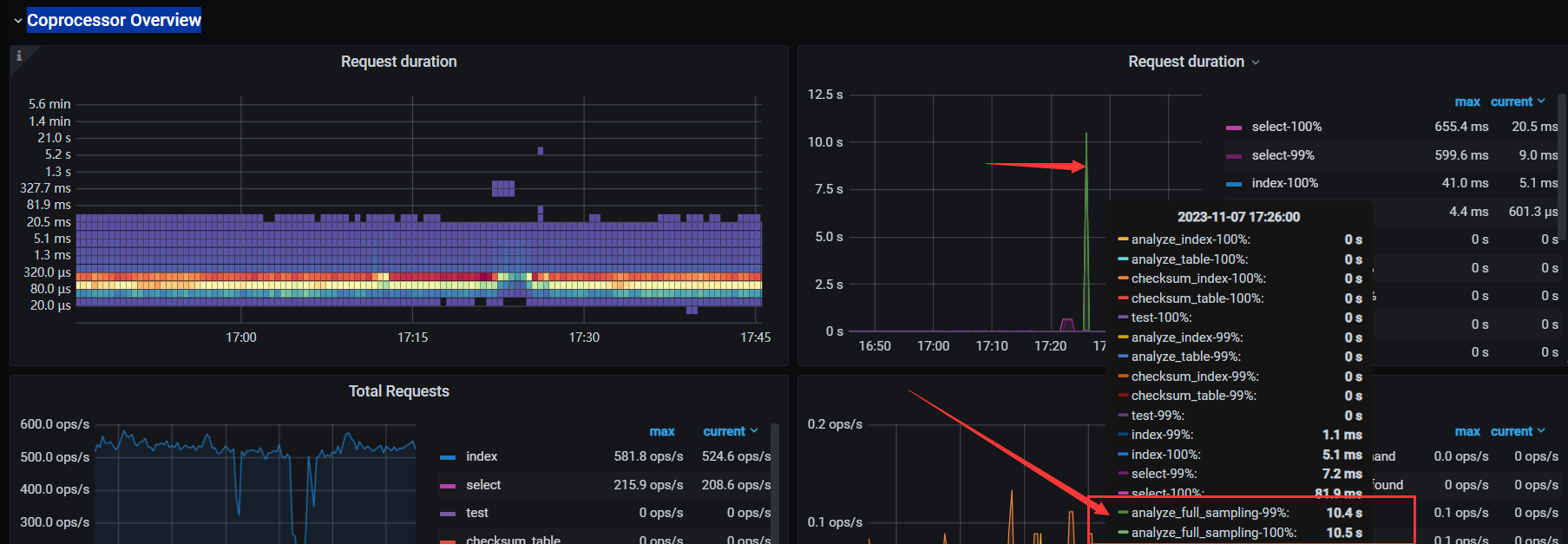
你可以看一下是不是因为统计信息的收集导致的慢,看一下tikv-detail-Coprocessor Overview
的监控图,看你的表,是一个分区表,而且分区挺多的。多数原因是跟统计信息有关,统计信息占用资源,导致资源短暂的占用等待,我这也出现类似于你这种现象:我的监控图如下:
另个下面还有一个监控图。你可以看一下你的是不是也是这样的,我这类似于这样的:
感谢回答,我看了我这边的和您这个还不一样,我的是select 耗时长,收集统计信息占用时间不长
执行计划几乎一样,差距就在我贴的这里,这是接口大量请求才会出现少数,手动执行很难复现
人如其名
(人如其名)
8
贴一个完整的执行计划就这么困难吗?对于疑难问题本身就很复杂,然后又给这么少的信息,让人非常难以判断。最起码的也要给一个执行差的完整执行计划信息,如果再慷慨一点贴一下执行不差的完整的执行计划信息。
Kongdom
(Kongdom)
9
是相同sql么?
如果是相同sql时快时慢,可以考虑是否是有热点或者慢查询时集群繁忙
如果不是相同sql,建议上传完整的慢sql执行计划,敏感信息可以打码
2 个赞
就是相同的sql,执行计划都是完全一样,不一样我也不会问了.我也怀疑是tikv那块繁忙,但看监控吧,比平时也相差不大。
从流量图上看是存在热点的,因为我们这边存在批任务,我也怀疑是io相关的影响。