【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.11
【复现路径】无
【遇到的问题:问题现象及影响】
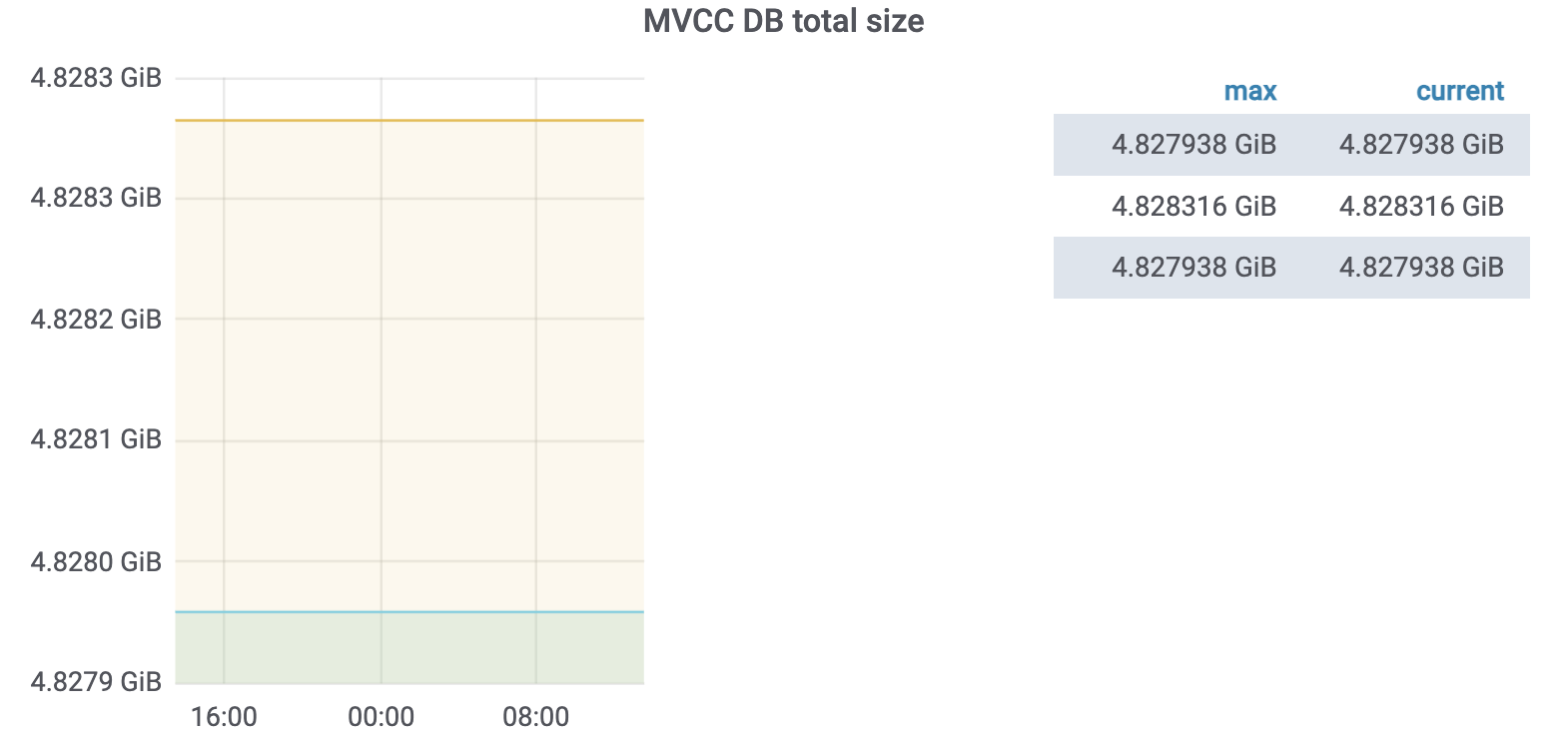
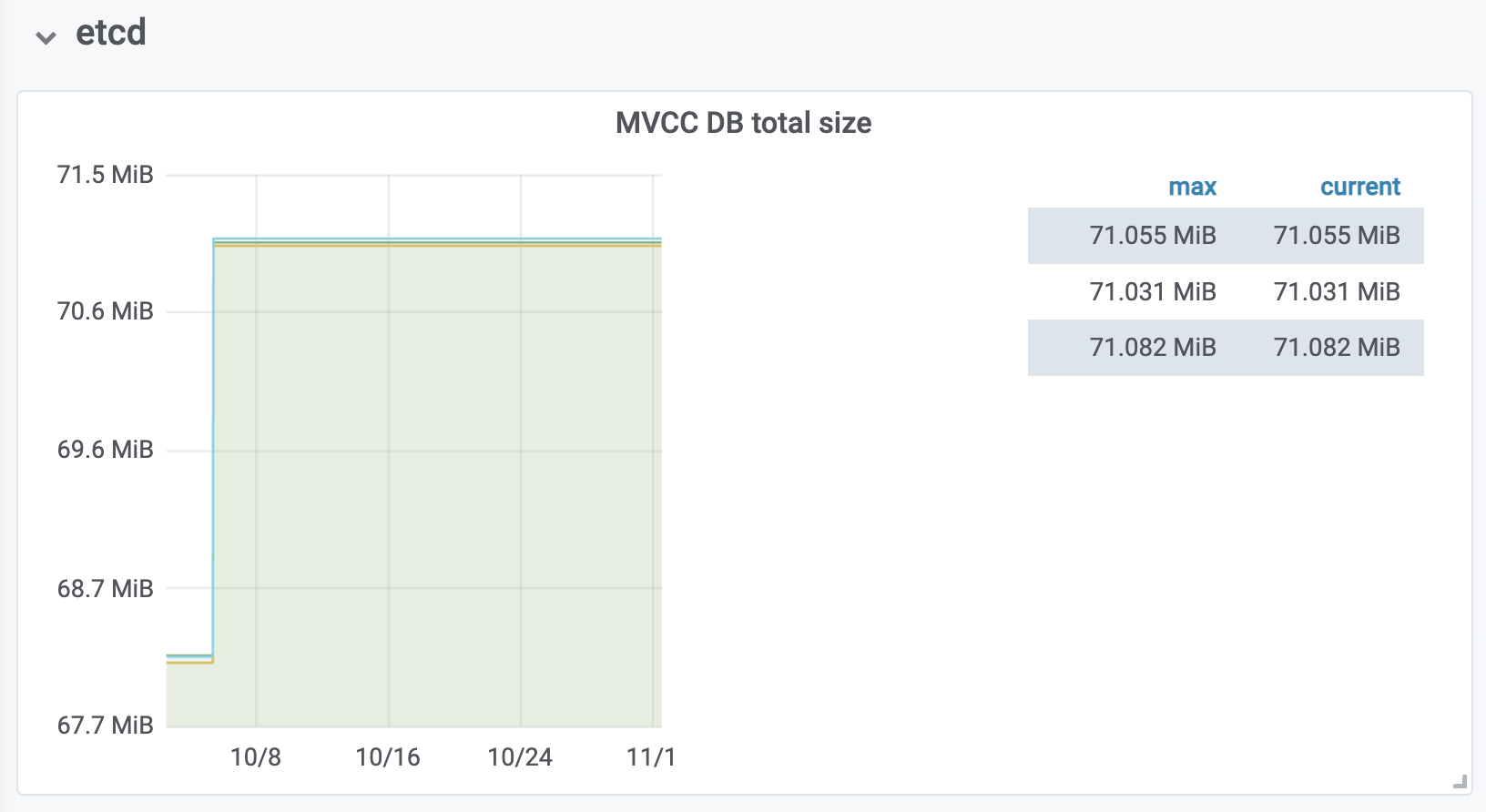
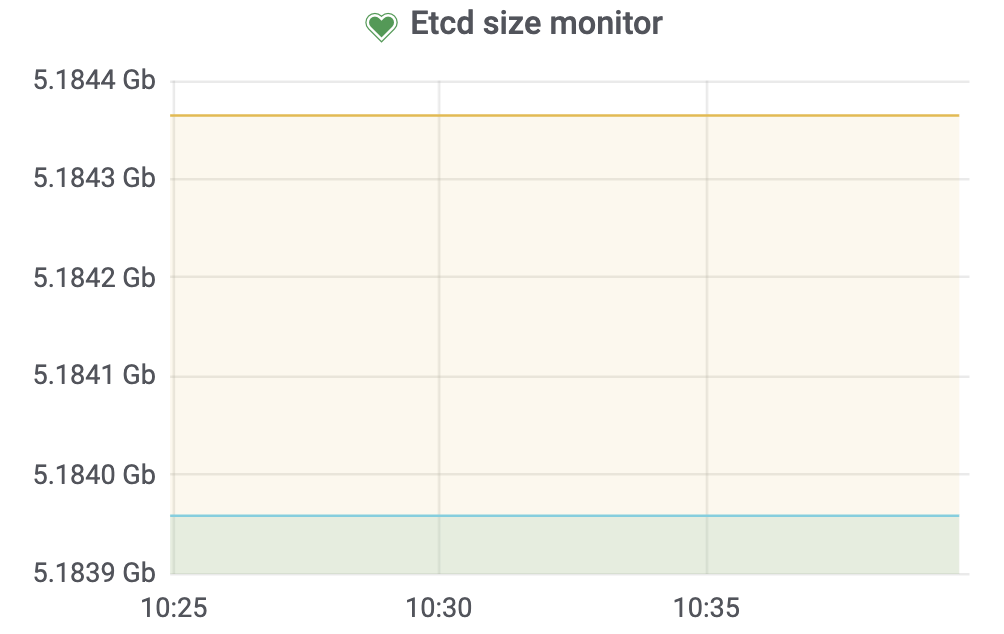
存在主备A、B两个集群,通过服务方的双写以及TiCDC保持数据一致,但近期发现B集群的mvcc_db_total_size达到了5G左右,但A集群只有100M不到
想了解可能的原因以及如何将其降下去
【资源配置】


【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.11
【复现路径】无
【遇到的问题:问题现象及影响】
存在主备A、B两个集群,通过服务方的双写以及TiCDC保持数据一致,但近期发现B集群的mvcc_db_total_size达到了5G左右,但A集群只有100M不到
想了解可能的原因以及如何将其降下去
【资源配置】
【附件:截图/日志/监控】
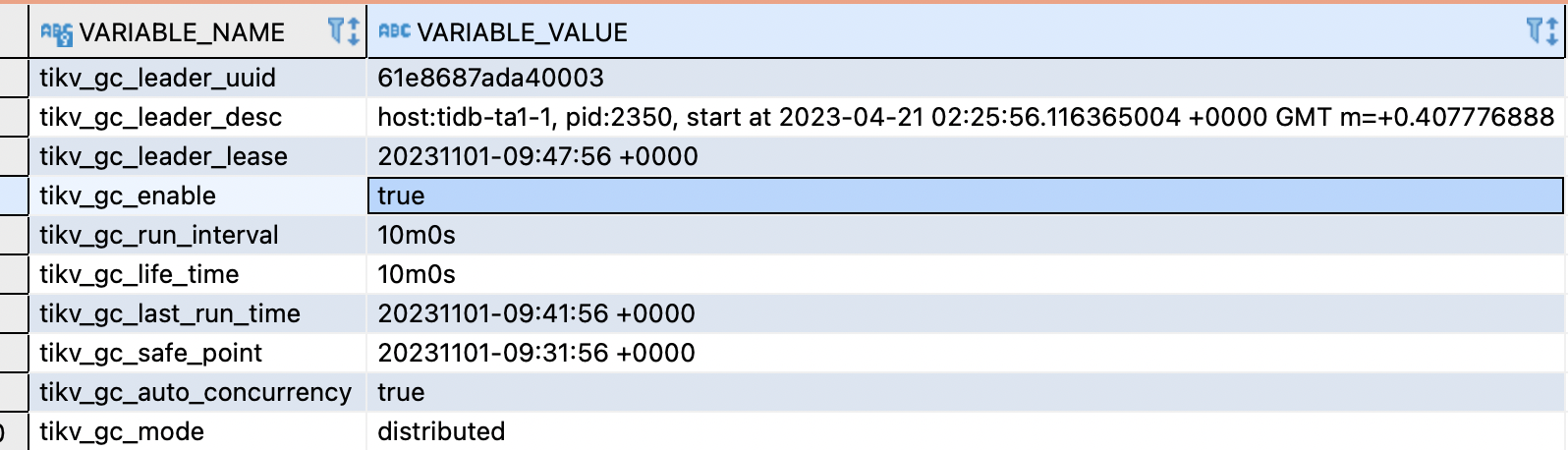
查下两个集群的 GC 的配置是否一致…
我看了PD的配置
高ETCD集群
pd:
auto-compaction-mode: revision
auto-compaction-retention: "5"
log.file.max-days: 3
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
正常集群
pd:
auto-compaction-mode: revision
auto-compaction-retention: "5"
log.file.max-days: 7
quota-backend-bytes: 17179869184
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
所以看起来唯一不一样的只有quota-backend-bytes即元数据存储空间大小,默认值为8G,但看起来正常集群反而更大一些
那你要看下为啥,gc没有执行,看看日志,是哪里hang住了还是什么
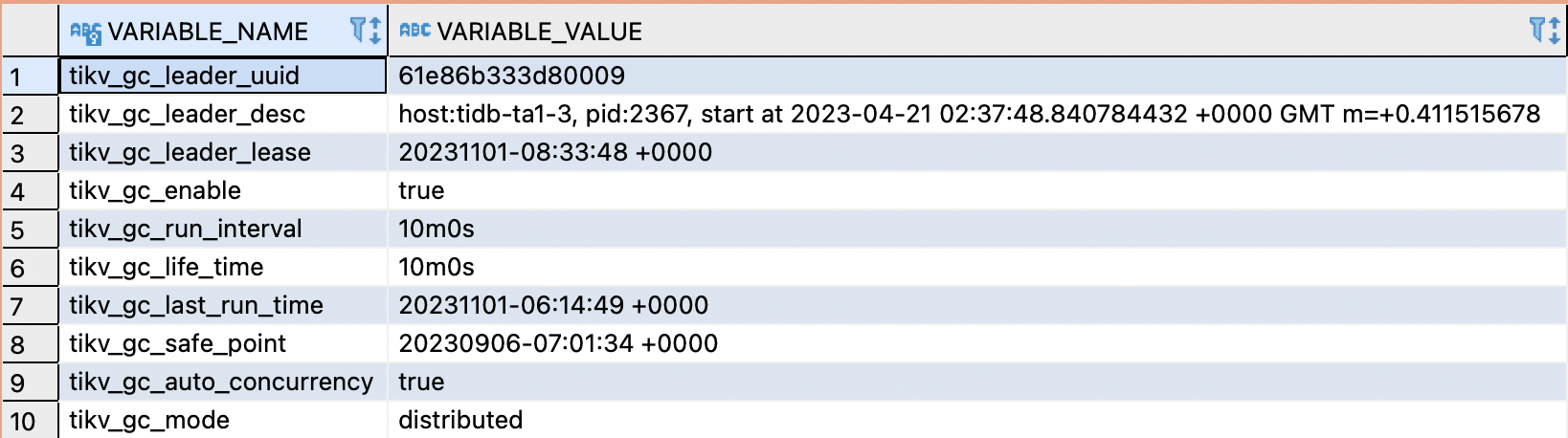
gc safe point 时间是今天的了,比前面发的变化了
GC 如果正常,MVCC 的版本信息就会被正常清理掉的,就是需要多给点时间
如果 GC 不正常,就排查下Gc 的问题就可以了
这个问题可能是低版本cdc的bug,我们最近遇到一个类似的问题,etcd 元数据太多占据了pd 集群的空间
看起来目前距离GC恢复已经过去24小时了,但是ETCD依然很高,我理解应该还是有其他原因导致的,是否和较高的empty-region以及number of region有关?我理解如果ETCD存储的是meta info的话这个是比较有可能的
我这边操作发现GC safepoint的停止必然和CDC有关,因为停止的时间恰好和某个stopped的CDC task的tso一致,清理CDC任务后GC就正常了,但是ETCD还是没有变化
empty-region 可以合并掉的… 这样可以减少资源占用,提速~
上游的cdc版本是什么,低版本的cdc有bug,参考这个https://docs.pingcap.com/zh/tidb/v5.4/troubleshoot-ticdc#ticdc-占用多少-pd-的存储空间
是CDC任务影响了嘛
看起来不是文档上提到的版本
Release Version: v4.0.11
Git Commit Hash: 52a6d9ea6da595b869a43e13ae2d3680354f89b8
Git Branch: heads/refs/tags/v4.0.11
UTC Build Time: 2021-02-25 16:40:37
Go Version: go version go1.13 linux/amd64
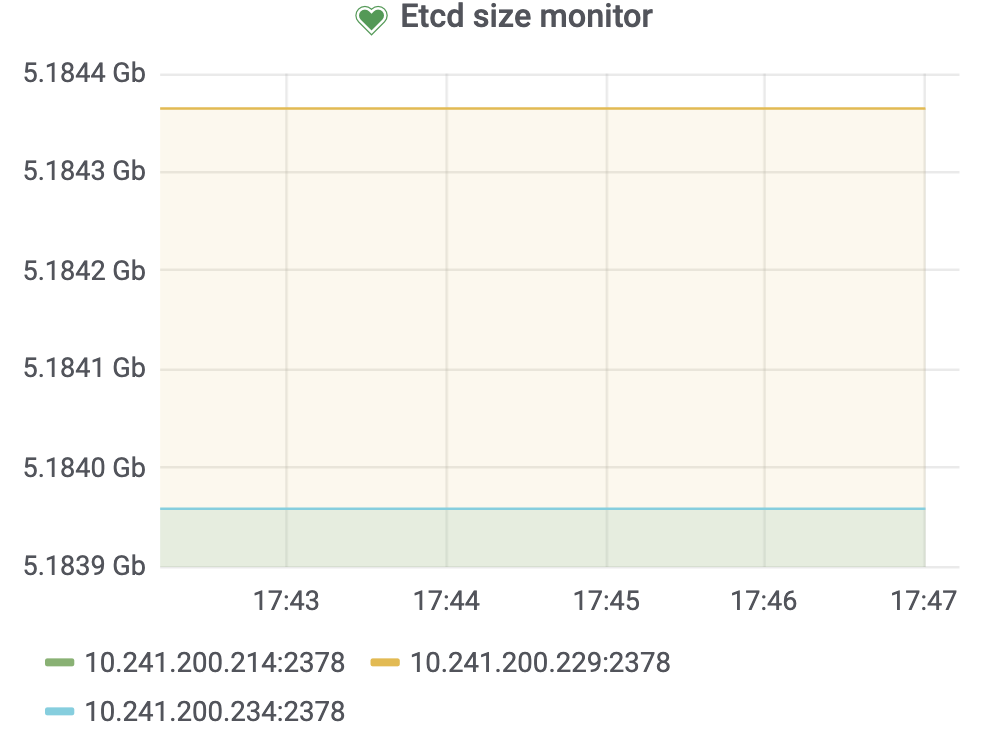
之前应该是的,不过清理CDC任务后目前GC safepoint已经恢复正常了,但ETCD size还是维持在5G左右,没有变化
我稍后试一试