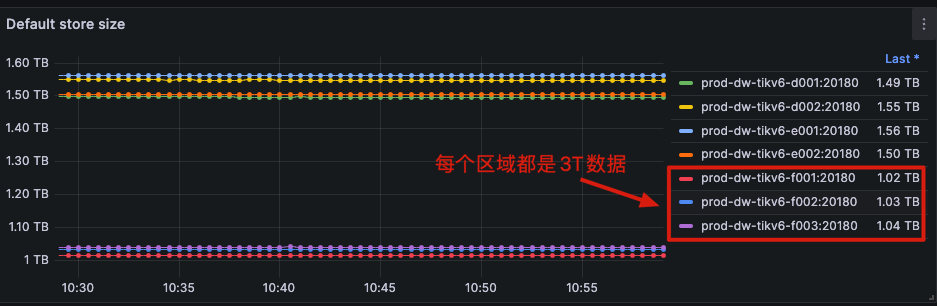
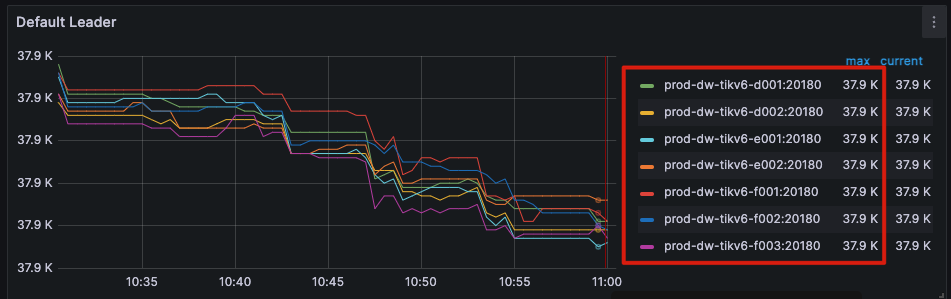
如题,集群有几台TiKV数据分布不均匀(Leader是平均的,但是总region数量不一样),但是看store score都是一致的,设置的isolation-level也是host,但是看起来是按照zone级别来隔离了。相关参数如下:
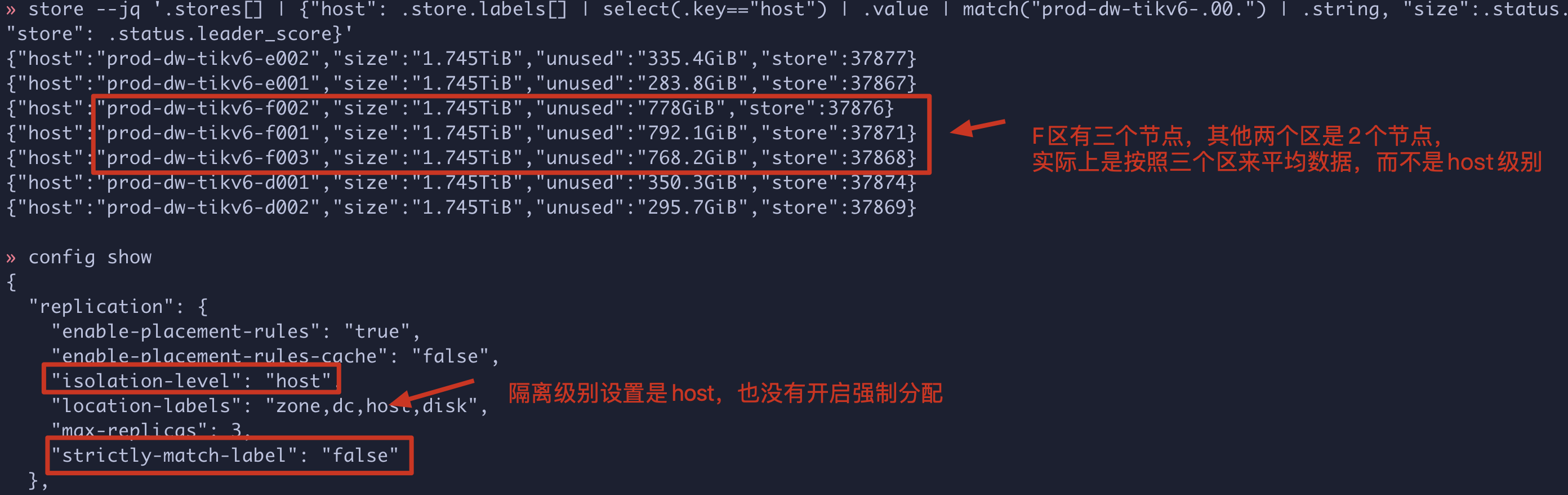
通过grafana监控,其实更清晰,每个区域都是3T数据,但是Leader数据量一致。
如题,集群有几台TiKV数据分布不均匀(Leader是平均的,但是总region数量不一样),但是看store score都是一致的,设置的isolation-level也是host,但是看起来是按照zone级别来隔离了。相关参数如下:
不严格匹配应该是自上往下匹配满足副本数的label吧。节点数2 2 3,没办法做到按host级均衡
tikv的label怎么打的?
[{“key”:“disk”,“value”:“ssd”},{“key”:“zone”,“value”:“cn-shenzhen”},{“key”:“host”,“value”:“prod-dw-tikv6-d001”},{“key”:“dc”,“value”:“cn-shenzhen-d”}]
类似这种的,分了zone, dc, host, disk四级
额,意思是如果我设置了strictly-match-label=true,反而会真的强制按照host隔离么?
可以搞个 1 1 2的环境测下,到时再看看region health监控有没有异常的
按照文档描述,确实是按照label的层级来优先分散。如果假设单个节点的Leader个数为x,计算下来2个节点的DC里总region个数是(2x + 2x + 3x),平均下来每个节点是7/2x。三节点DC里单节点的region数是7/3x。
实际上生产的Region个数也满足这个关系,单节点Leader是37.8k, D/E区节点是130k左右,F区单节点是88k,和计算出来的一模一样。
https://docs.pingcap.com/zh/tidb/stable/schedule-replicas-by-topology-labels#基于拓扑-label-的-pd-调度策略
不过按照这个描述来看,设置strictly-match-label这个参数并不能解决这个问题,strictly-match-label是个兜底设置,还是会优先按照label级别来进行follower副本的部署
貌似可以通过replication.location-labels来考虑,从原来的zone,dc,host,disk改成host,这样应该就只考虑host这个label的值来平均分配了。
不过,这样下来跨机房的容灾策略就得不到保证了,我还是再多申请两台机器扩容一下吧 ![]()
你这个大概率也是机器分布不均导致的,不过差别不大
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。