【 TiDB 使用环境】生产环境
【 TiDB 版本】
【复现路径】
之前是 haproxy timeout client 30s 导致全部任务报同样的错误,把配置调整回 timeout client 30000s 后部分任务正常,还是有不少任务报错
【遇到的问题:问题现象及影响】
“errors”: [
{
“ErrCode”: 10006,
“ErrClass”: “database”,
“ErrScope”: “not-set”,
“ErrLevel”: “high”,
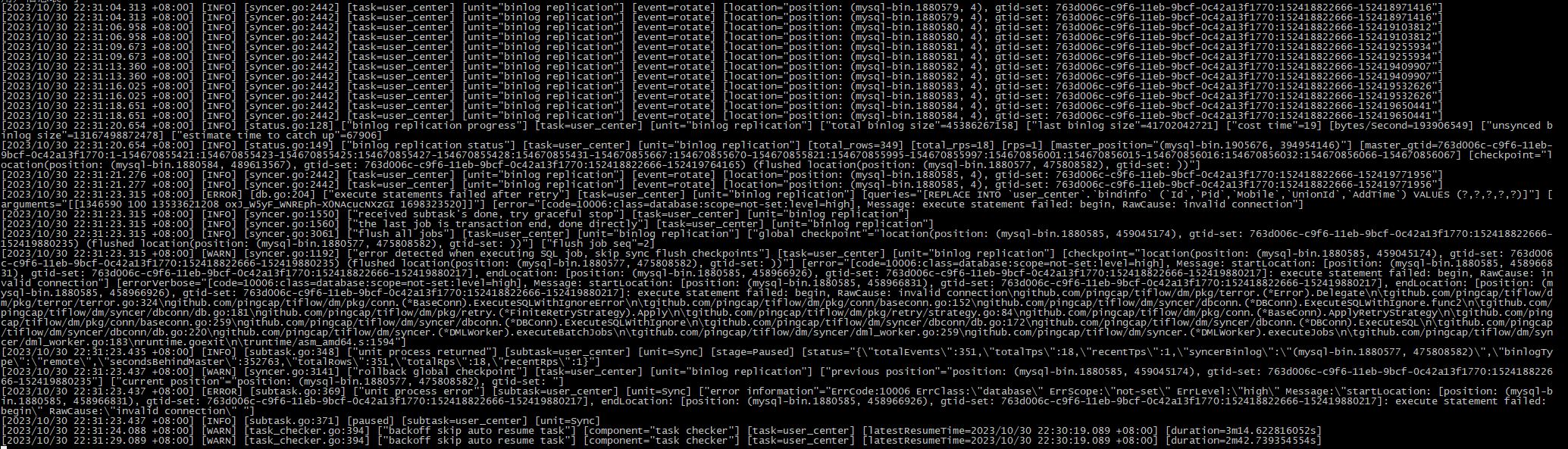
“Message”: “startLocation: [position: (mysql-bin.1880585, 458966831), gtid-set: 763d006c-c9f6-11eb-9bcf-0c42a13f1770:152418822666-152419880217], endLocation: [position: (mysql-bin.1880585, 458966926), gtid-set: 763d006c-c9f6-11eb-9bcf-0c42a13f1770:152418822666-152419880217]: execute statement failed: begin”,
“RawCause”: “invalid connection”,
“Workaround”: “”
}
],
【资源配置】
【附件:截图/日志/监控】
dm-worker_stdout.log
dm-worker_stderr.log
dm-worker.log
环境问题,不太好直连,可以试试。
但看 dm-worker_stdout.log 中 syncer 被 kill 的时间,也就 20s,dm 这边还有之类的超时配置或者缓存吗?试过 start-task --remove-meta 重建任务也是没效果
贴一份 dm 配置:
name: xxx
task-mode: incremental
target-database:
host: "127.0.0.1"
port: 3306
user: "root"
password: "xxx"
syncers:
global:
worker-count: 128
batch: 500
compact: true
multiple-rows: true
block-allow-list:
ba-rule1:
do-dbs: ["xxx"]
mysql-instances:
- source-id: "xxx"
meta:
binlog-name: mysql-bin.1880577
binlog-pos: 475808582
block-allow-list: "ba-rule1"
syncer-config-name: "global"
走了 socat 转发,绕过了 haproxy,还是有同样的问题
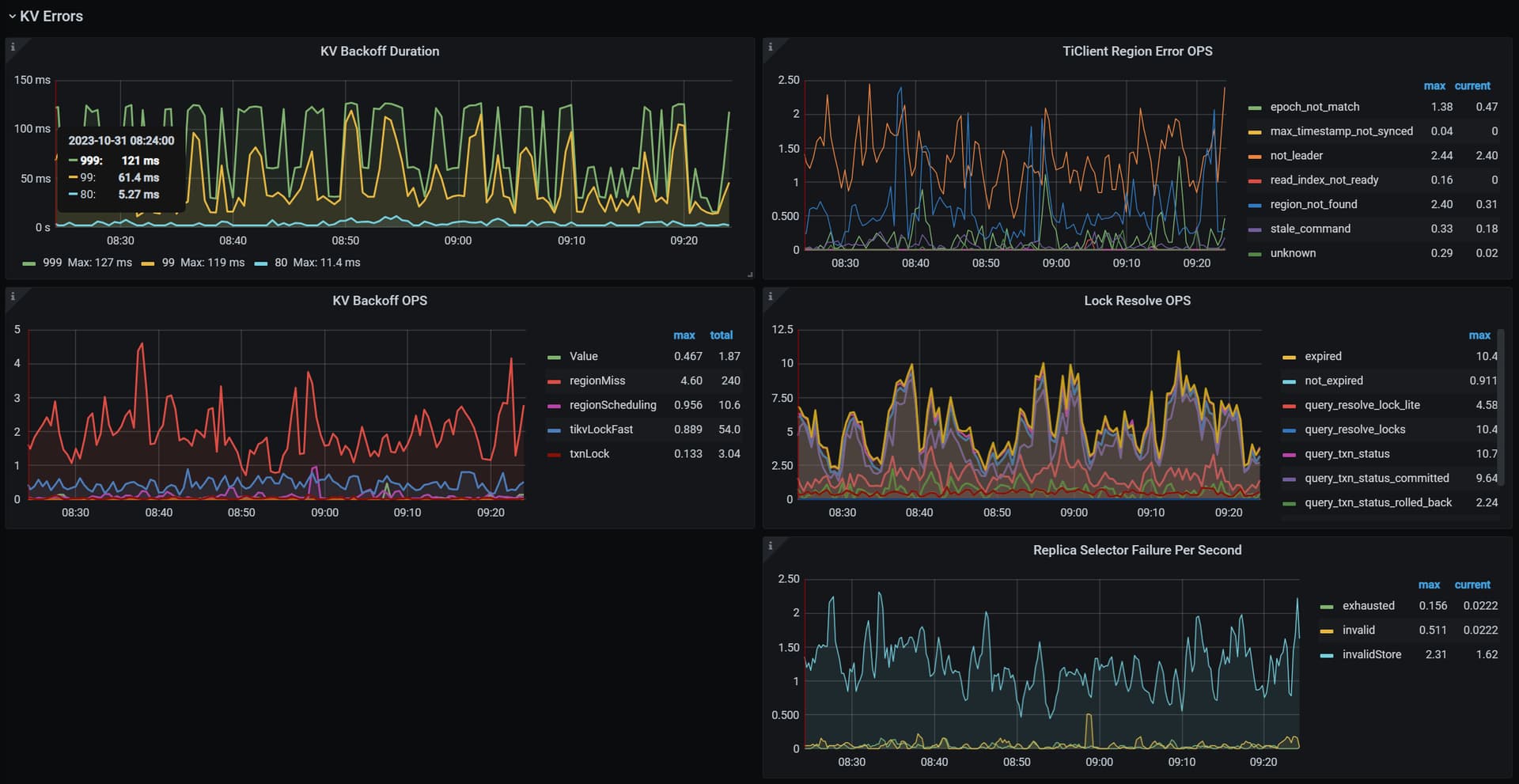
检查下监控 cluster_tidb → kv errors的有lock或者backoff么?
dba-kit
(张天师)
11
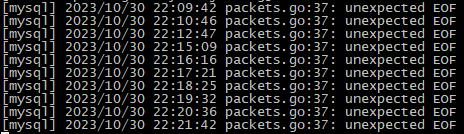
这个报错是golang driver报的,如果是全量同步的dump阶段报错,就看上游MySQL的wait_timeout是多少。如果增量同步报错,就看下游TiDB的wait_timeout参数是多少?
“invalid connection和bad connection都是dm里连接正常,被服务端(MySQL/TiDB)单方面中断的,从可能中断连接的参数排查吧。
dba-kit
(张天师)
13
如果是同步阶段报的错,大概率这个表更新没那么频繁,在大于wait_timeout的时间内都一直没有数据写入,突然有写入就发现连接已经被下游给杀掉了。
你这txnLock锁一直这么高么?检查一下是否PD日志里有调度?
就是看一下在DM运行期间,是否有 “leader changed”
[2023/10/31 09:36:14.589 +08:00] [INFO] [region.go:708] [“leader changed”] [region-id=919505783] [from=885548005] [to=885547999]
有,leader 节点一直再刷,但是 leader 是没有切换到其他节点的,这个会有什么影响
transfer-hot-read-leader如果PD节点因为其他因素的热点读或热点写而频繁leader changed,PD出现leader调度,就会产生backoff,你的DM任务就会被阻塞甚至断掉啊
至于锁的原因,要去看具体sql了,同一时间段内还有什么其他的操作,或者是否有死锁的SQL产生
information_schema.deadlocks
mysql> select * from information_schema.deadlocks limit 1;
Empty set (0.00 sec)
死锁看了下倒是没有