【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.7
【遇到的问题:问题现象及影响】 tikv多个实例上出现unified read pool占用几十核CPU资源
【附件:截图/日志/监控】
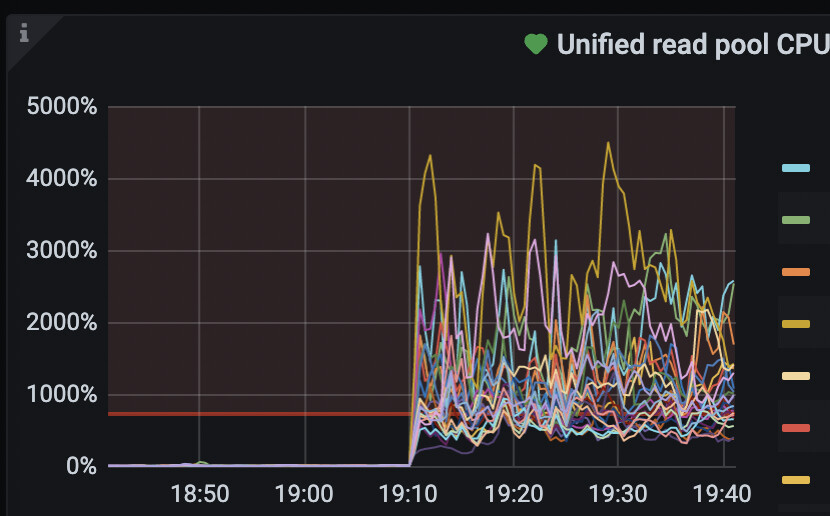
默认情况下,Unified read pool的大小是机器CPU数的80%
一台机器多实例的话,那你要修改下,实例加起来,别超过80%就好

一台TIKV机器四个TIKV实例,机器总共核数96核,当前看系统配置的是76
这个建议看过了,包括TIKV线程池优化,调整后目前看没什么效果
一共96核,80% 就是 76核,
四个实例,每个 就是 76/4=19核
目前调整到15核了,再观察中,正常来说这个readpool不应该是瓶颈,我这压测的QPS读才不到4000QPS
恩呢,读取请求的负载较大,就会高一些
不知道6.5,7.1针对这个参数是否有过优化
看官档,好像木有
numa绑核,cpu可能存在争用的情况,也需要看下topsql情况
如何查看是否做到NUMA绑核了呢
看到了,lscpu看到NUMA绑过核了
数据库的负载和资源利用率怎么样呢
有大佬写过专栏可以看看
1 个赞
在请教你个问题,你在使用TIDB前做个性能极限压测么? 结合业务场景的,例如:读请求按照并发10,30,50,100…压测TIDB,然后观察各项监控指标,我昨天压测的时候发现readpool的线程负载特别高导致TIKV的物理机器CPU都基本被榨干了,调整线程后TIKV的CPU降低了,但是SQL耗时确涨上来了
tidb非常吃硬盘,首先需要测试磁盘的性能,我这有个文档测试磁盘性能
磁盘性能测试标准.docx (18.3 KB)
然后是集群的测试,官方有提供 Sysbench工具做压测,通过监控就能看到你集群的极限和瓶颈
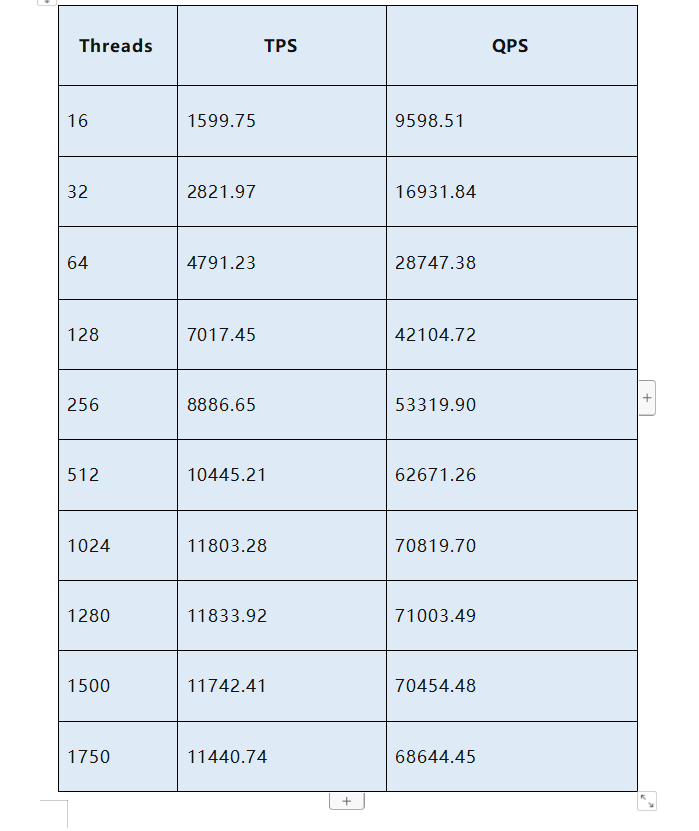
sql耗时变长可以在dashboard的慢查询查看是慢在哪里了,不断发现瓶颈做出相应优化。
你说的是TIKV模块吃硬盘吧