【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.1.7
【遇到的问题:问题现象及影响】 PDSERVER保存着整体TIKV中REGION的拓扑信息,如果集群规模非常大,例如100TB的规模,那相应的REGION个数会几百万以上,这里我有两个问题需要咨询一下、
1、PDSERVER中保存REGION的元信息拓扑是如何实现的【REGION在STORE中的保存策略】
2、REGION个数百万以上后PDSERVER是否会遇到性能瓶颈,或者是否可以优化参数解决性能问题
pd有数据库etcd,在etcd里保存 了每个 REGION 的位置、副本数以及与其他 REGION 之间的关系。它提供了以下信息:
- REGION ID:每个 REGION 的唯一标识符。
- 存储信息:描述 REGION 存储的物理位置和副本的分布情况。
- 父级 REGION ID:指定当前 REGION 的父级 REGION。
- 子级 REGION ID 列表:指定当前 REGION 的所有子级 REGION。
- 副本信息:描述每个 REGION 的副本状态和同步情况。
PD 将 Region Meta 信息存在本地的 LevelDB 中,并通过其他机制同步 PD 节点间的信息。
LevelDB是一个C++语言编写的高效键-值嵌入式数据库,目前对亿级的数据也有着非常好的读写性能。
进来学习一下
REGION过百万了,不会有性能问题么
LEVELDB在哪里
pd本地文件里能找到

看来PD自身还真有个数据库,这个数据库还是KV格式存储的,那看来region信息的保存确实是这样存储的
对于region个数500万+的量级,不知道PD这块的调度会不会有性能问题
数据量太大会有性能问题,可以调整regions大小减少数量
500万的数据量对msql来说都没问题,这种kv数据库毫无压力
我说的是单副本REGION=500万哦,哈哈
对了,近期我这边测试V6.1.7版本的时候,统计信息中表的健康度变化非常频繁【其实线上写入量只小于1000,而且只有INSERT+DELETE】,跑一宿发现从99–>49了 ![]() ,看来表的健康度这块的源码得开始分析一下了
,看来表的健康度这块的源码得开始分析一下了
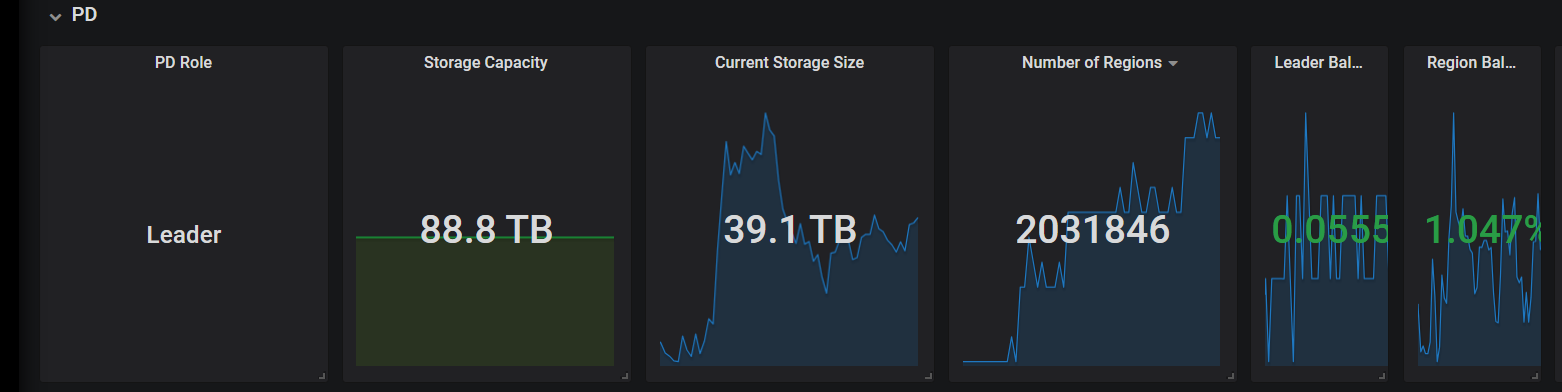
我这Current Storeage Size 接近100TB了
这么大数据量了么 有没有可能从业务上归档下历史数据呢
我们其实想测试TIDB的容量上限,确定集群规模到XXTB后触碰了性能拐点
之前看过一篇关于region的调度的文章,不知道对你有没有用