【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】

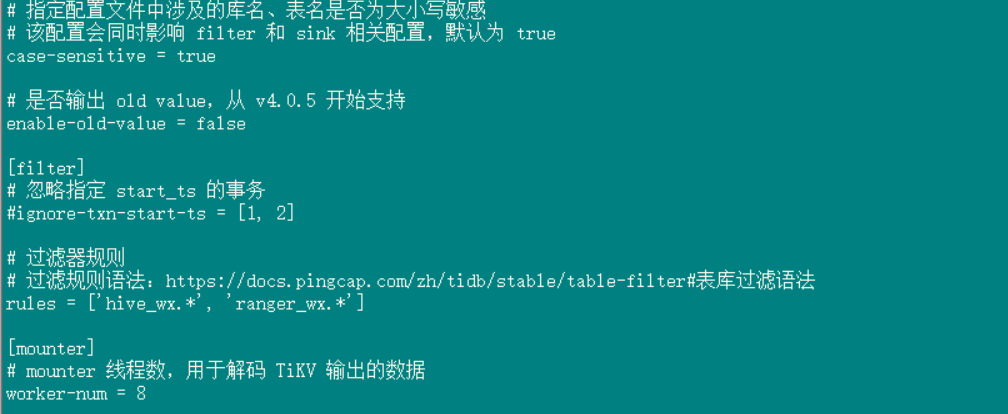
cdc是同步rules = [‘hive_wx.', 'ranger_wx.’] ,br restore :hive 也不是同一个
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
这个好像是BUG,我们经常遇到(状态显示正常,业务上已经停止了,无报警),建议你在业务端做监控,比如下游数据端监测
那我如何才能restore,求助
您把 cdc 同步的内容发下 ,和状态
这个任务报什么错
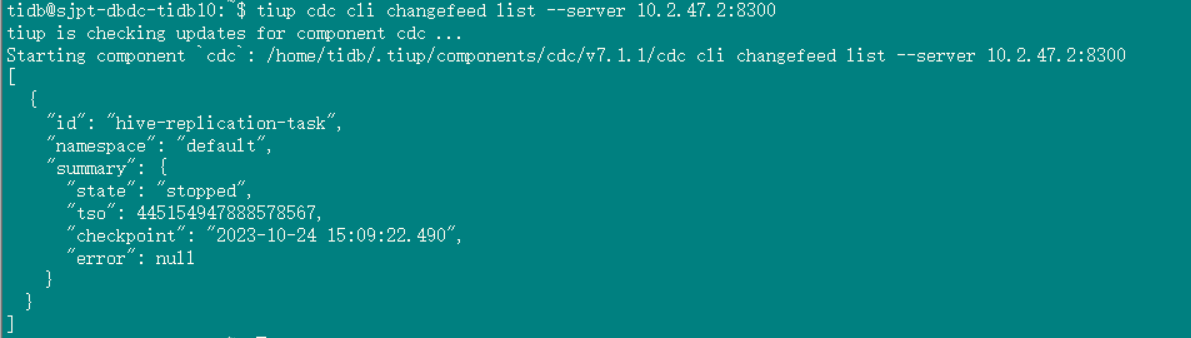
cdc正常stop,br 的restore起不来
![]()
这个日志发出来看下
[2023/10/24 15:15:25.418 +08:00] [INFO] [info.go:49] [“Welcome to Backup & Restore (BR)”] [release-version=v7.1.1] [git-hash=cf441574864be63938524e7dfcf7cc659edc3dd8] [git-branch=heads/refs/tags/v7.1.1] [go-version=go1.20.6] [utc-build-time=“2023-07-19 10:08:48”] [race-enabled=false]
[2023/10/24 15:15:25.418 +08:00] [INFO] [common.go:723] [arguments] [__command=“br restore db”] [db=hive] [pd=“[10.2.47.2:2379]”] [ratelimit=128] [storage=s3://cairui-bigdata-temp/hive/]
[2023/10/24 15:15:25.421 +08:00] [INFO] [common.go:169] [“trying to connect to etcd”] [addr=“[10.2.47.2:2379]”]
[2023/10/24 15:15:25.424 +08:00] [ERROR] [restore.go:64] [“failed to restore”] [error=“failed to check task exists: found CDC changefeed(s): cluster/namespace: backup/0/tidb/cdc changefeed(s): [hive-replication-task], cluster/namespace: default/default changefeed(s): [hive-replication-task], please stop changefeed(s) before restore”] [errorVerbose=“found CDC changefeed(s): cluster/namespace: backup/0/tidb/cdc changefeed(s): [hive-replication-task], cluster/namespace: default/default changefeed(s): [hive-replication-task], please stop changefeed(s) before restore\ngithub.com/pingcap/tidb/br/pkg/task.checkTaskExists\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/task/stream.go:1082\ngithub.com/pingcap/tidb/br/pkg/task.RunRestore\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/task/restore.go:576\nmain.runRestoreCommand\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/restore.go:63\nmain.newDBRestoreCommand.func1\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/restore.go:183\ngithub.com/spf13/cobra.(*Command).execute\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:916\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:1044\ngithub.com/spf13/cobra.(*Command).Execute\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:968\nmain.main\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/main.go:58\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250\nruntime.goexit\n\t/usr/local/go/src/runtime/asm_amd64.s:1598\nfailed to check task exists”] [stack=“main.runRestoreCommand\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/restore.go:64\nmain.newDBRestoreCommand.func1\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/restore.go:183\ngithub.com/spf13/cobra.(*Command).execute\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:916\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:1044\ngithub.com/spf13/cobra.(*Command).Execute\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:968\nmain.main\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/main.go:58\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250”]
[2023/10/24 15:15:25.425 +08:00] [ERROR] [main.go:60] [“br failed”] [error=“failed to check task exists: found CDC changefeed(s): cluster/namespace: backup/0/tidb/cdc changefeed(s): [hive-replication-task], cluster/namespace: default/default changefeed(s): [hive-replication-task], please stop changefeed(s) before restore”] [errorVerbose=“found CDC changefeed(s): cluster/namespace: backup/0/tidb/cdc changefeed(s): [hive-replication-task], cluster/namespace: default/default changefeed(s): [hive-replication-task], please stop changefeed(s) before restore\ngithub.com/pingcap/tidb/br/pkg/task.checkTaskExists\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/task/stream.go:1082\ngithub.com/pingcap/tidb/br/pkg/task.RunRestore\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/pkg/task/restore.go:576\nmain.runRestoreCommand\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/restore.go:63\nmain.newDBRestoreCommand.func1\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/restore.go:183\ngithub.com/spf13/cobra.(*Command).execute\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:916\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:1044\ngithub.com/spf13/cobra.(*Command).Execute\n\t/go/pkg/mod/github.com/spf13/cobra@v1.6.1/command.go:968\nmain.main\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/main.go:58\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250\nruntime.goexit\n\t/usr/local/go/src/runtime/asm_amd64.s:1598\nfailed to check task exists”] [stack=“main.main\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/br/br/cmd/br/main.go:60\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:250”]
[
{
“id”: “b66c73db-9736-419e-8dac-4adab35c8263”,
“is-owner”: false,
“address”: “10.2.47.2:8300”,
“cluster-id”: “default”
},
{
“id”: “e5c3cdd9-7639-4db8-90fb-01efba95e3fb”,
“is-owner”: true,
“address”: “10.2.47.152:8300”,
“cluster-id”: “default”
}
]
之前remove了也不行

直接把cdc的服务停掉试过没 ??
“upstream_id”: 7090447822685072046,
“namespace”: “default”,
“id”: “hive-replication-task”,
“sink_uri”: “mysql://wolfman:xxxxx@172.18.20.241:8398/”,
“config”: {
“memory_quota”: 1073741824,
“case_sensitive”: true,
“enable_old_value”: false,
“force_replicate”: false,
“ignore_ineligible_table”: false,
“check_gc_safe_point”: true,
“enable_sync_point”: false,
“bdr_mode”: false,
“sync_point_interval”: 600000000000,
“sync_point_retention”: 86400000000000,
“filter”: {
“rules”: [
“hive_wx.",
"ranger_wx.”
],
“event_filters”: null
},
“mounter”: {
“worker_num”: 8
},
“sink”: {
“protocol”: “”,
“schema_registry”: “”,
“csv”: {
“delimiter”: “,”,
“quote”: “"”,
“null”: “\N”,
“include_commit_ts”: false,
“binary_encoding_method”: “base64”
},
“column_selectors”: null,
“transaction_atomicity”: “”,
“encoder_concurrency”: 16,
“terminator”: “\r\n”,
“date_separator”: “day”,
“enable_partition_separator”: true,
“file_index_digit”: 0,
“enable_kafka_sink_v2”: false,
“only_output_updated_columns”: null
},
“consistent”: {
“level”: “none”,
“max_log_size”: 64,
“flush_interval”: 2000,
“storage”: “”,
“use_file_backend”: false
},
“scheduler”: {
“enable_table_across_nodes”: false,
“region_threshold”: 100000,
“write_key_threshold”: 0
},
“integrity”: {
“integrity_check_level”: “none”,
“corruption_handle_level”: “warn”
}
},
“create_time”: “2023-10-24 14:59:17.955”,
“start_ts”: 445154421495037958,
“resolved_ts”: 0,
“target_ts”: 0,
“checkpoint_tso”: 445154947888578567,
“checkpoint_time”: “2023-10-24 15:09:22.490”,
“state”: “stopped”,
“error”: null,
“error_history”: null,
“creator_version”: “v7.1.1”
}
有服务器的话,新版本再测试下,可能是bug吧。
那我这个还有啥办法不,把cdc缩容了?
缩容了都不行,怎么刷新pd的数据