【 TiDB 使用环境】生产环境
【 TiDB 版本】v7.1.1
【复现路径】
- 通过br backup db 备份指定数据库到存储,再恢复至下游tidb库(版本相同)
- 新增changefeed,指定start-ts,向下游同步增量数据
【遇到的问题:问题现象及影响】
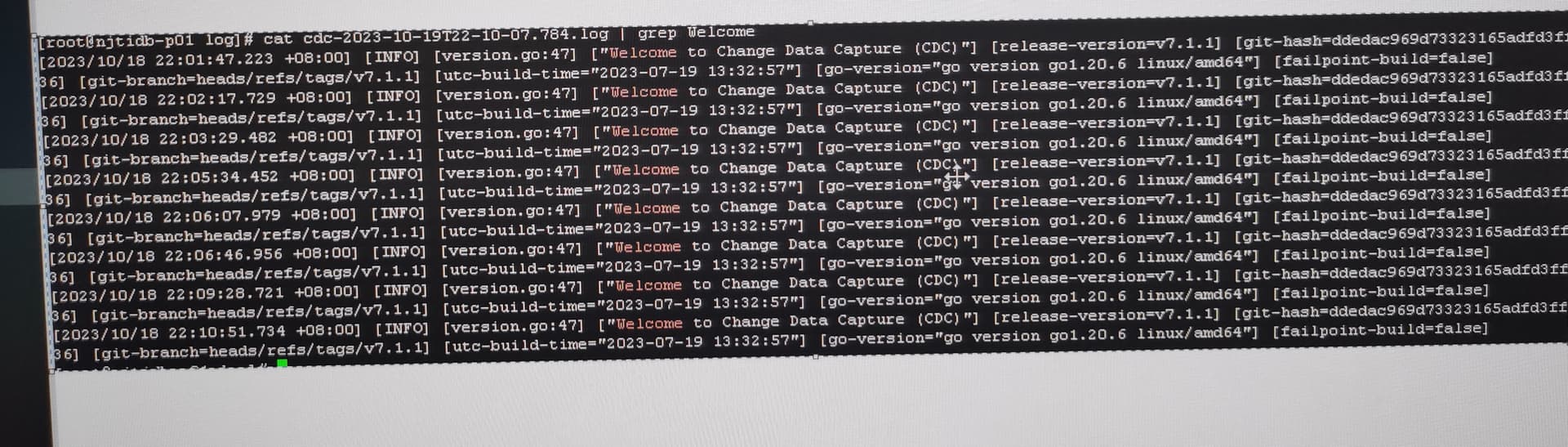
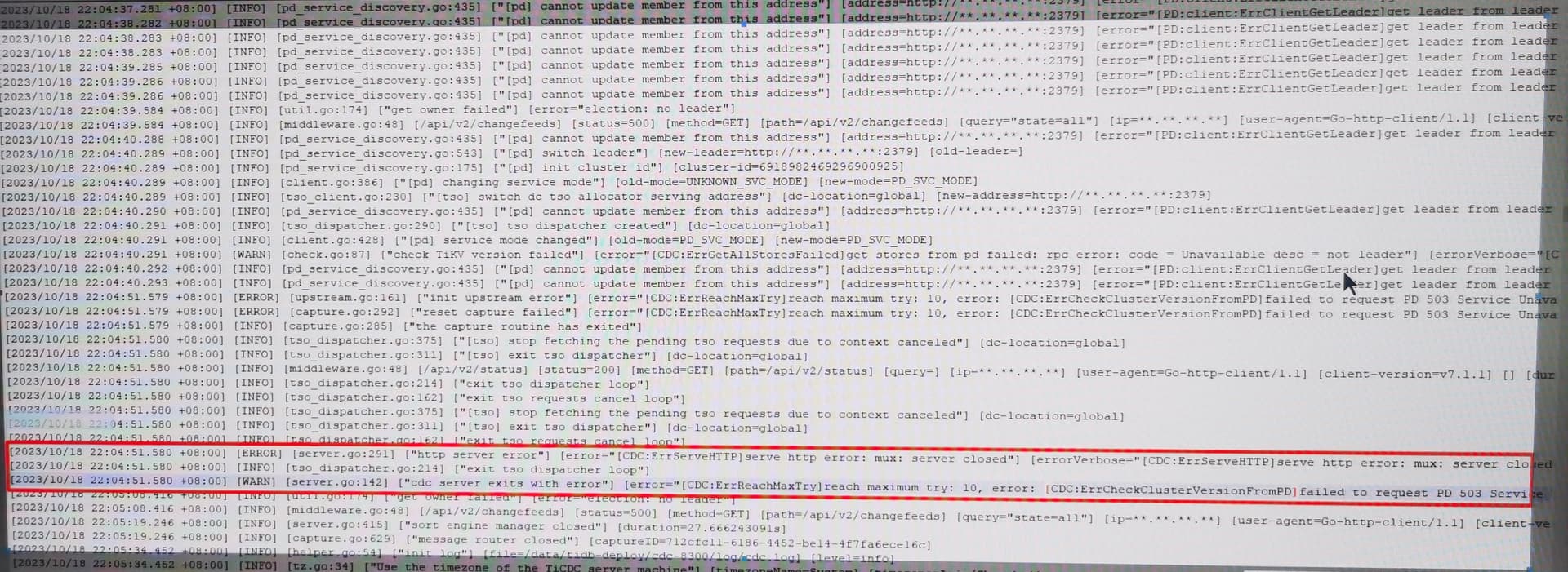
TICDC不断重启,中间偶尔出现类似 resolved ts should not less than checkpoint ts 的错误,然后过一会又自动恢复。
PS: 原来存在推送kafka的changefeed,新增changefeed会导致原来的changefeed也卡住,并导致cdc不断重启,现在还有一批表没有加进去,也不敢加了,怕把原来的changefeed也卡住并且无法恢复。
开始以为是一次性加载的表太多(700张左右),后来将这700张表分批接入,还是会出现以上问题。
cdc.log.rar (1.6 MB)
路在何chu
(Ti D Ber Ass Gn Qs R)
2
cdc changefeed query -s 查一下任务有啥报错
期间唯一的报错就是这个:resolved ts should not less than checkpoint ts,状态是error,但是过一会又恢复,然后cdc不断重启
tso都是严格按照br backup生成的backupts 设置的,这个可以肯定没有错。
新的changefeed创建之后,tso不推进,中间偶尔出现上面错误,然后就是不断重启,重启了N次之后,突然就好了, 如果tso设置问题,应该是过不去的。
目前看来能不能正常全靠运气, 我中间把表不断的拆分,然后才勉强跑起来
路在何chu
(Ti D Ber Ass Gn Qs R)
6
tiup ctl:v4.0.13 pd -i -u http://10.xx:2379,可以登进去查出对应的tso时间,然后看看是不是gc已经清理了
在操作之前,gc都是关掉的,离我备份的tso至少提前3个小时
路在何chu
(Ti D Ber Ass Gn Qs R)
8
但是你恢复如果太久,会被清理,我之前恢复了超过24个小时,然后建任务就是这个保错,gc已经清理了
你把这个任务从新创建一下,使用当前默认时间,看是否正常呢
根本原因可能是解析的ts和检查点ts是在不同的线程中计算的,这会导致检查点ts可能大于解析的ts。
从后面他能够自动恢复,确实有可能是这个问题, 这种可以理解为概率偶发现象。 但是cdc不断重启的原因是什么呢?
ticdc的日志
pd的日志
感觉上是因为TS时间不同步,导致TICDC在更新数据时,找不到etcd的元数据吧,个人理解哈!
TiCDC 使用 PD 内部的 etcd 来存储元数据并定期更新。因为 etcd 的多版本并发控制 (MVCC) 以及 PD 默认的 compaction 间隔是 1 小时,TiCDC 占用的 PD 存储空间与 1 小时内元数据的版本数量成正比
https://docs.pingcap.com/zh/tidb/stable/ticdc-changefeed-config
-
--start-ts:指定 changefeed 的开始 TSO。TiCDC 集群将从这个 TSO 开始拉取数据。默认为当前时间。
-
--target-ts:指定 changefeed 的目标 TSO。TiCDC 集群拉取数据直到这个 TSO 停止。默认为空,即 TiCDC 不会自动停止。
–start-ts都是指定了的, 而且小批量表备份还原,中间的间隔时间都很短,不超过1个小时