【 TiDB 使用环境】生产环境
【 TiDB 版本】5.2.4
【遇到的问题:问题现象及影响】
dumpling导出csv文件怎么输出到一个csv文件,不是导出好多csv小文件;
-F 选项用于指定单个文件的最大大小,单位为 MiB ,可接受类似 5GiB 或 8KB 的输入。如果你想使用 TiDB Lightning 将该文件加载到 TiDB 实例中
2 个赞
-
-F选项用于指定单个文件的最大大小,单位为MiB,可接受类似5GiB或8KB的输入。如果你想使用 TiDB Lightning 将该文件加载到 TiDB 实例中,建议将-F选项的值保持在 256 MiB 或以下。
如果你要写入一个文件直接把这个参数调大,但是这样写入性能会变差。
2 个赞
-F 指定了256M,但是输出的都是100来k的
把-r 10000去掉 -t 写1试试看
-t 是导出线程数 导出并发数和导出的小文件有关系吗
./dumpling -h 10.10.10.16 -P 4000 -u root -p ****** -o test --filetype csv -t 32 -r 200000 -F 256MiB --sql ‘select * from sbtest.sbtest1 where id < 1000’
我导出的就是1个文件啊。。。

2 个赞
文件行数和文件大小设置大一些
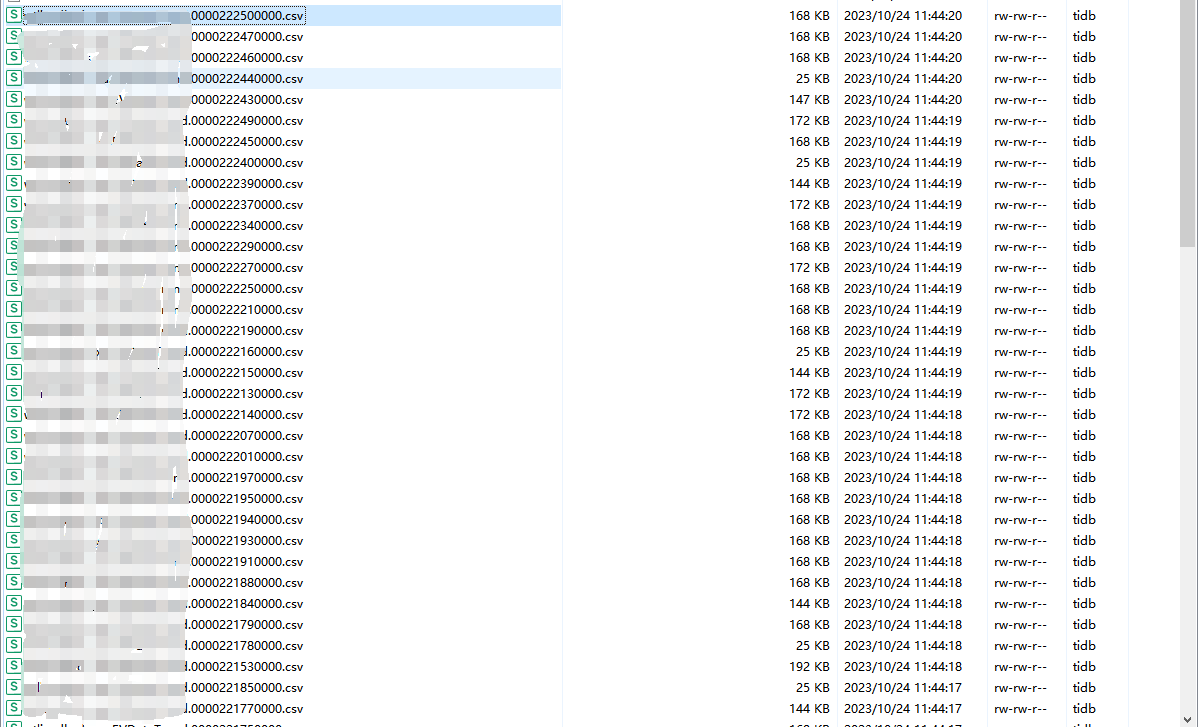
测试了下 导出参数不变 筛选不同目标 有的导出是一个大文件 有的导出就是几十个小文件
小表应该是单独一个文件的,不可能和其他表混一起导出的
我导出的是同一个表
把-F设置的很大,把-r去掉,或者设置为0.
你要开启表内并发,导出的时候肯定要写多个文件的吧。-r值越大,应该分的小文件越多。不然写一个文件,这不好并发的吧。
* -r用于开启表内并发加速导出。默认值是0,表示不开启。取值大于 0 表示开启,取值是 INT 类型。当数据源为 TiDB 时,设置 -r 参数大于 0 表示使用 TiDB region 信息划分区间,同时减少内存使用。具体取值不影响划分算法。对数据源为 MySQL 且表的主键是 INT 的场景,该参数也有表内并发效果。
https://docs.pingcap.com/zh/tidb/stable/dumpling-overview#导出为-sql-文件
1 个赞

上面是我去掉-r参数 把-F设置为2G 导出的情况
还是提高并发吧,反正这种文本最后导出来,大概率就是zip/tar。 ![]()
导入的时候多个文件,也可以提高并发。
导出csv给产品用 他们想1个文件结束 看样子有的可以 有的还是小文件 不研究了 导出后自己操作下
1 个赞
可以加大导出的行数,分文件可以快速导入
主要还是-r参数,如果你的表本身对应的region很多,会根据region分布情况来分成多个文件