【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.5.3
【复现路径】
生产环境报错 pd server timeout
已经通过black_exporter查看,ping无延迟
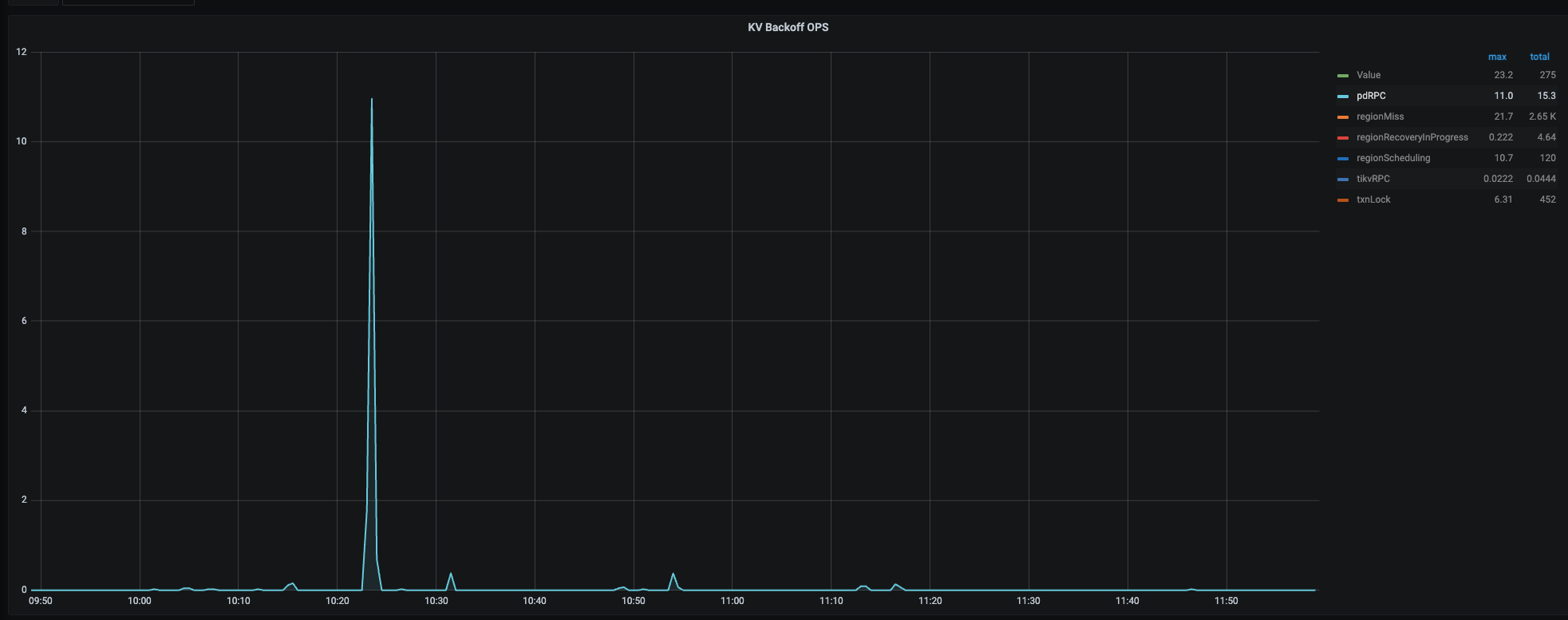
通过监控查看除了tidb监控界面有个pdrpc为10左右,没发现有其他的什么异常
【遇到的问题:问题现象及影响】
报业务select语句报错,pd server timeout
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
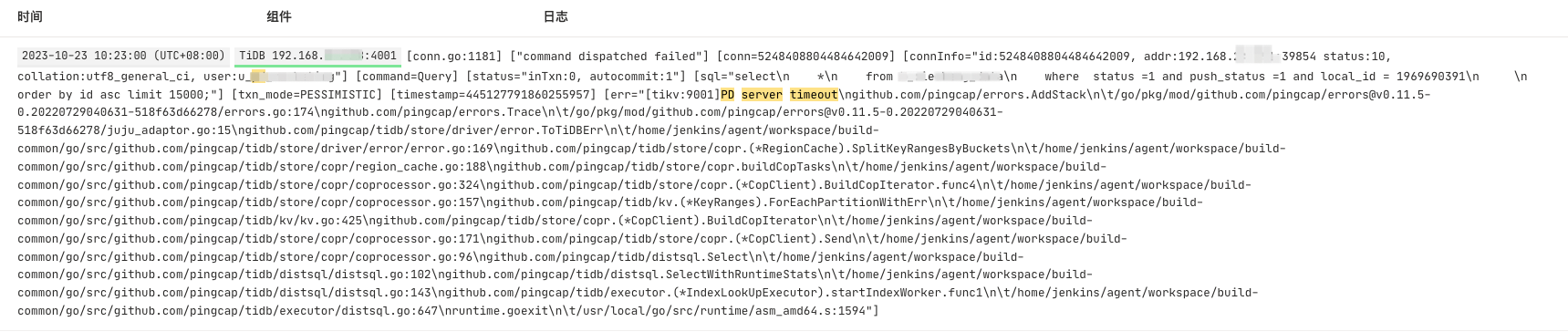
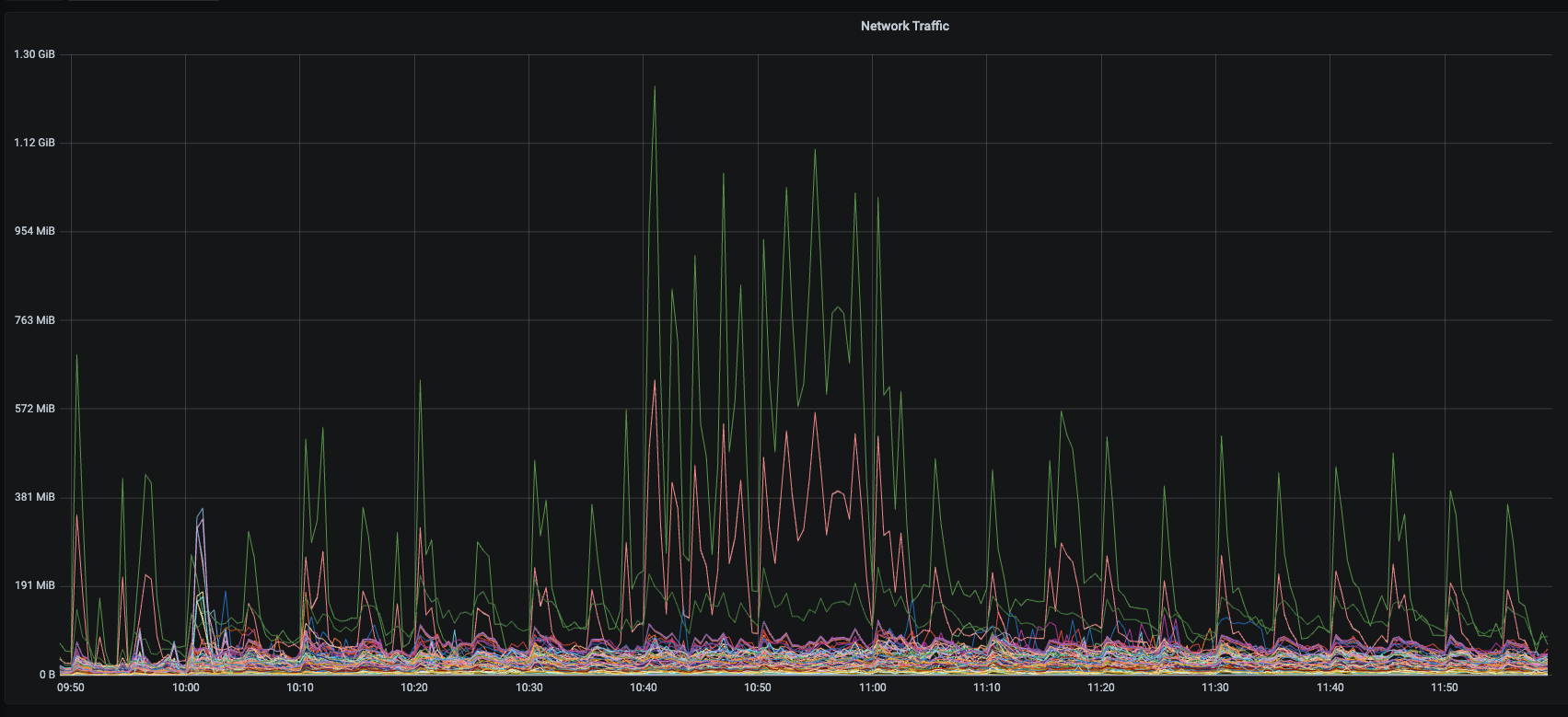
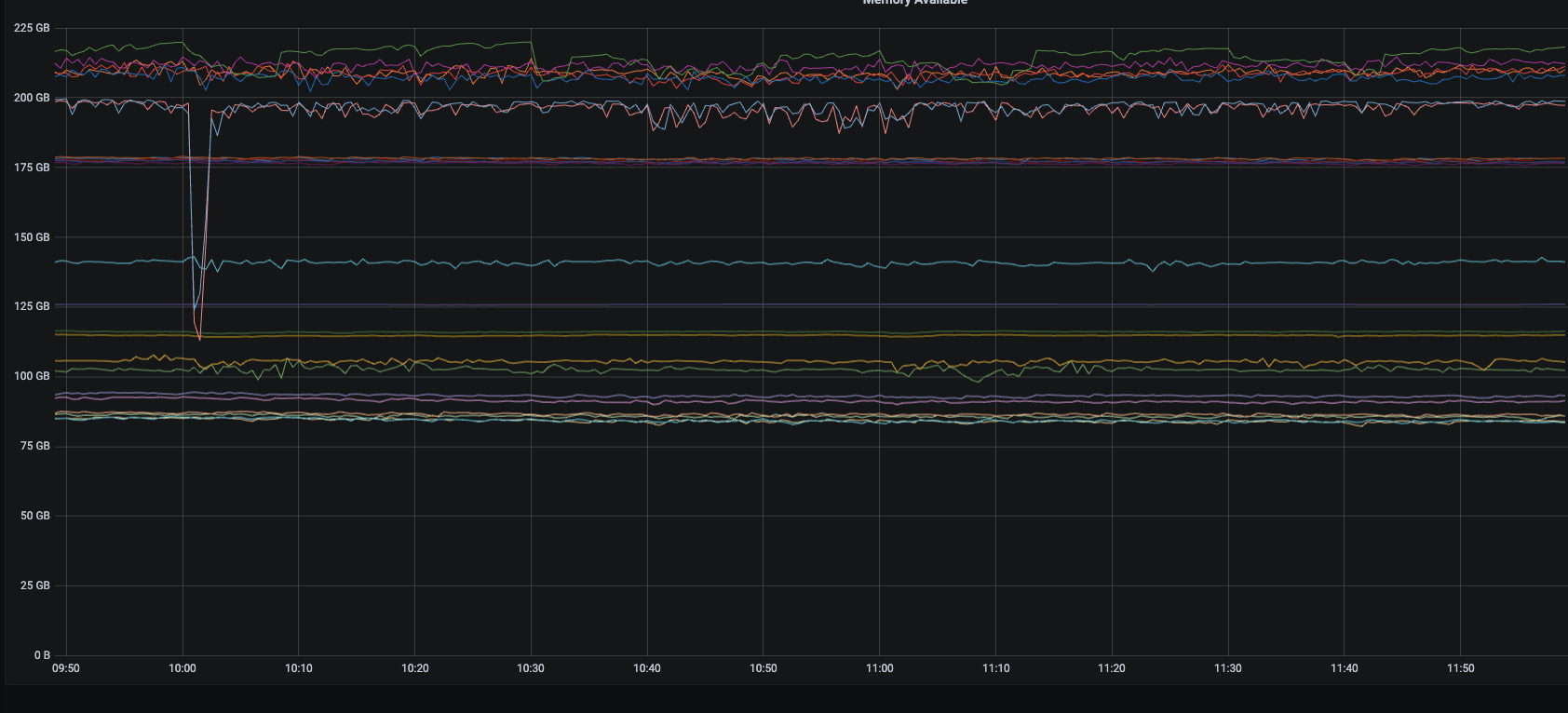
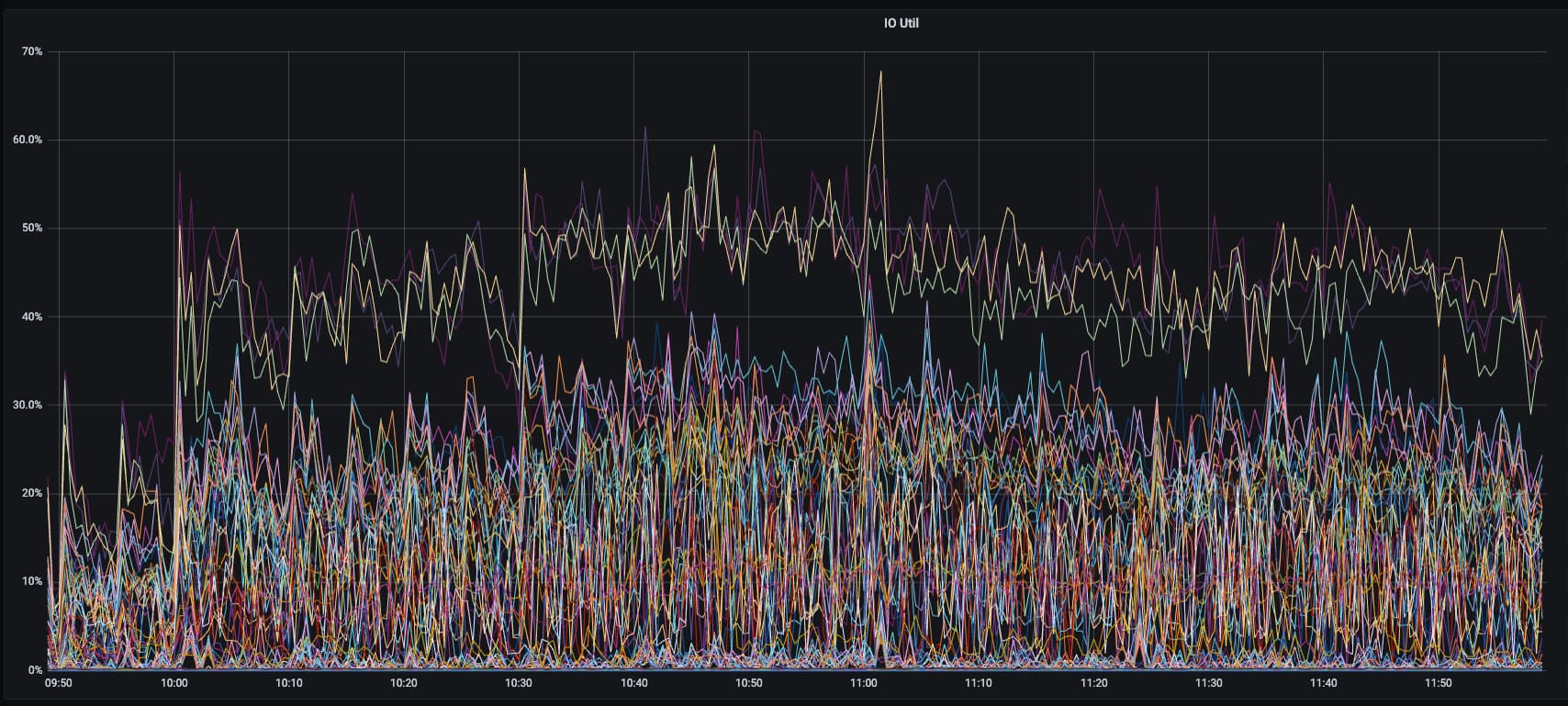
10点23这个时间点,cpu,io,网络,内存指标都正常的
在10点22分52秒有region分裂,region batch split,这个出现的很少,其他就是balance region有很多
看下PD有没有切换,
再看下网络问题,排查网络相关情况。通过监控 grafana → blackbox_exporter → ping latency 确定 TiDB 到 PD leader 的网络是否正常
嗯,已经看了,ping是正常的,pd没有切换过,leader还在那台服务器上,所以才比较困惑,怎么会莫名其妙的报了个pd server timeout
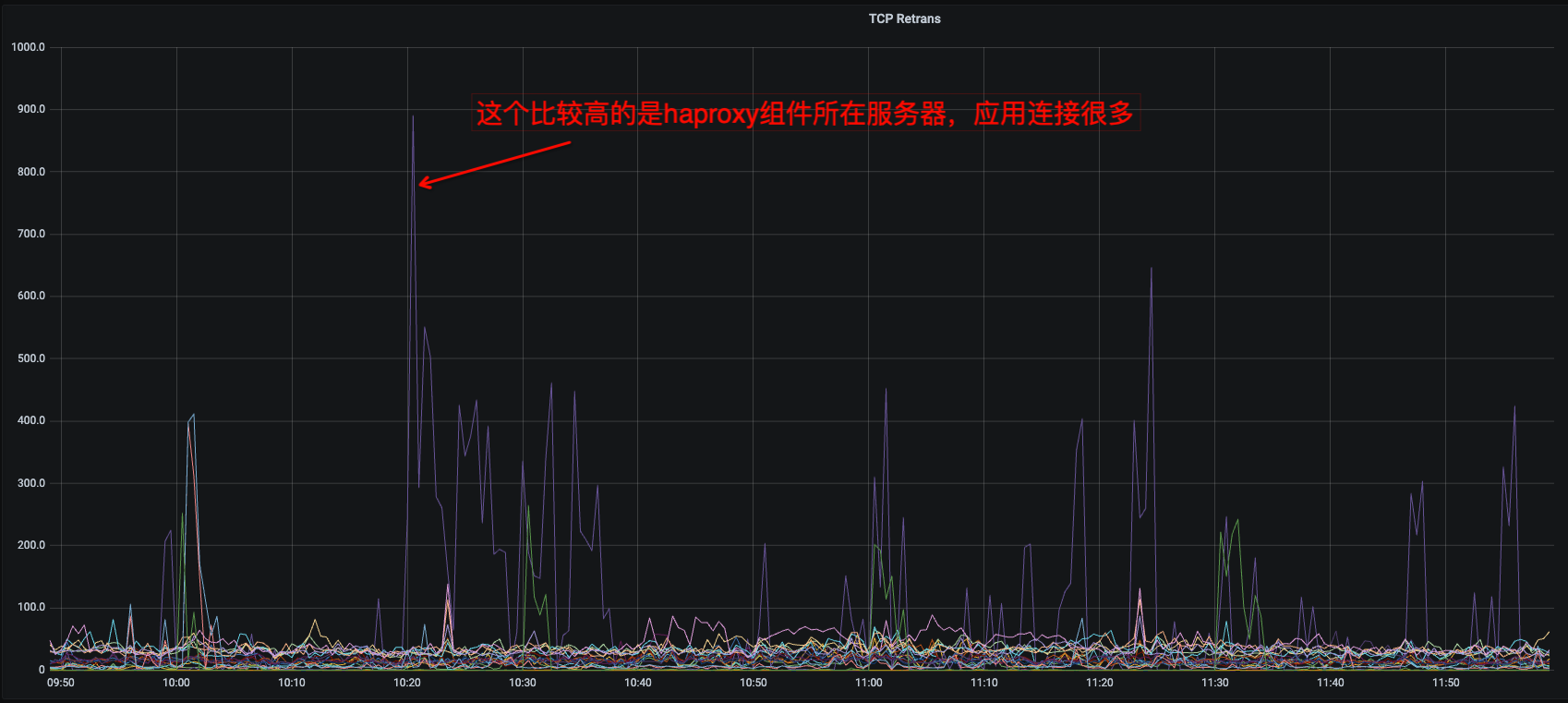
我是推测是不是因为有一台pd follower与haproxy混合部署在一台服务器的,haproxy请求量很多导致的,记得在哪看到6.5版本,请求tso可以在pd follower获取,昨天找了一会还没找到相关的文章
Jolyne
12
tidb_tso_client_batch_max_wait_time 从 v5.3.0 版本开始引入
- 作用域:GLOBAL
- 是否持久化到集群:是
- 类型:浮点数
- 默认值:
0
- 范围:
[0, 10]
- 单位:毫秒
- 这个变量用来设置 TiDB 向 PD 请求 TSO 时进行一次攒批操作的最大等待时长。默认值为
0,即不进行额外的等待。
- 在向 PD 获取 TSO 请求时,TiDB 使用的 PD Client 会一次尽可能多地收集同一时刻的 TSO 请求,将其攒批合并成一个 RPC 请求后再发送给 PD,从而减轻 PD 的压力。
- 将这个变量值设置为非 0 后,TiDB 会在每一次攒批结束前进行一个最大时长为其值的等待,目的是为了收集到更多的 TSO 请求,从而提高攒批效果。
- 适合调高这个变量值的场景:
- PD leader 因高压力的 TSO 请求而达到 CPU 瓶颈,导致 TSO RPC 请求的延迟较高。
- 集群中 TiDB 实例的数量不多,但每一台 TiDB 实例上的并发量较高。
- 在实际使用中,推荐将该变量尽可能设置为一个较小的值。
注意
如果 PD leader 的 TSO RPC 延迟升高,但其现象并非由 CPU 使用率达到瓶颈而导致(可能存在网络等问题),此时,调高 tidb_tso_client_batch_max_wait_time 可能会导致 TiDB 的语句执行延迟上升,影响集群的 QPS 表现。
好像是,刚看了下,这个是off,那应该不是这个问题
切换leader的时候timeout了一次,1分钟的从4到11,以后重试了以后,切换leader成功?这是网络问题?还是阻塞?
region 切换leader按照以往情况,只是会有重试,并不会超时,网络应该不是问题,black_exporter的ping latency是正常的
被阻塞了,但是不知道被什么阻塞了,集群负载还都挺正常,只有几个select语句报错,其他都正常,整体qps没降低,那个时间点,qps差不多80k/s