只能说提供一个方向吧。
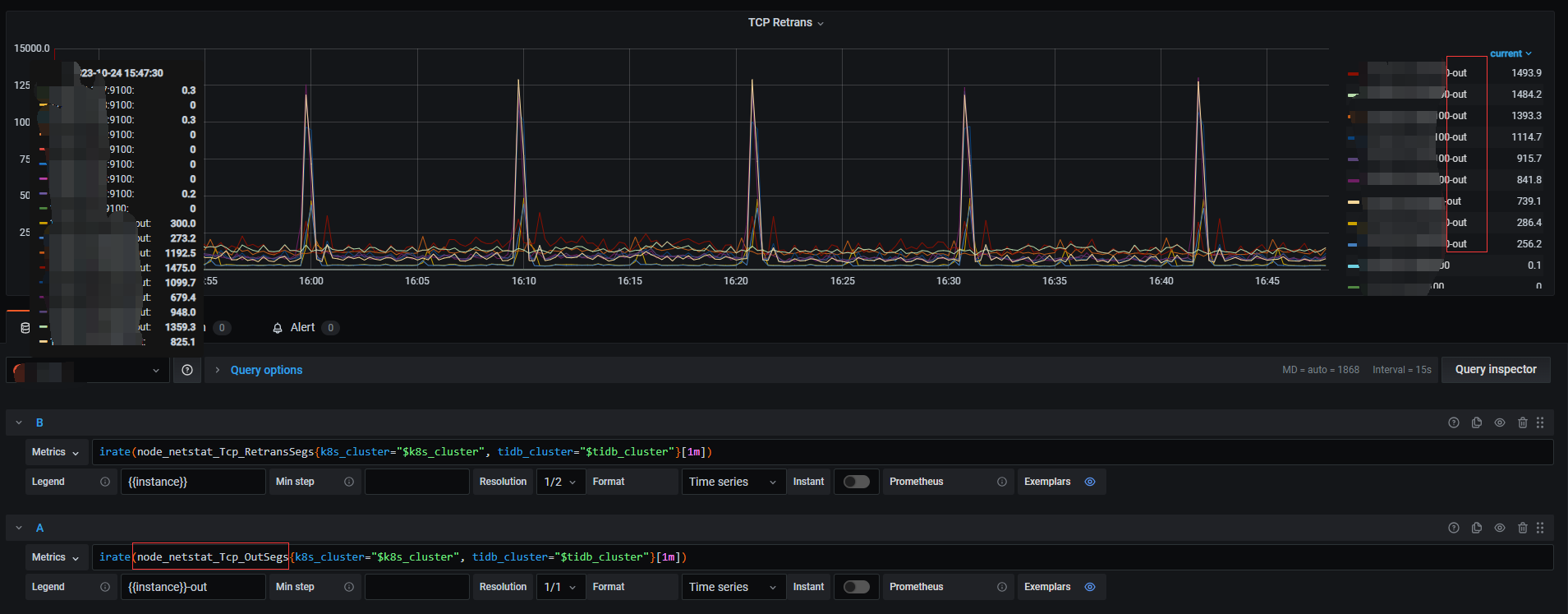
tcp retrans这个图的监控内容我跟踪了一下。
是从prometheus下的node_exporter组件里面取的值node_netstat_Tcp_RetransSegs。
实现在这里:
https://github.com/prometheus/node_exporter/blob/master/collector/netstat_linux.go#L39C323-L39C334
大致和
netstat -s | grep 'segments retransmited' | awk '{print $1}'
是等效的。
而segments retransmited看下来,解释都是说
|RetransSegs|所有重传出去的TCP包|tcp_v4_rtx_synack()和tcp_v6_rtx_synack()中
统计重传的SYNACK包,
tcp_retransmit_skb()中统计其他重传包|
| --- | --- |
https://perthcharles.github.io/2015/11/09/wiki-rfc2012-snmp-proc/
这个值单独是不能判断网络是否存在异常,搜索的结果大多赞同使用
netstat -s | grep ‘segments send out’ | awk ‘{print $1}’
算一个比值。这个值的高低才是一个客观的网络情况。
这个out segment 在node_exporter里面是有采集的。看能不能在这个图上调出来。
原始指标名称是node_netstat_Tcp_OutSegs。算算看这个值是否超过1%。
tcp和ping是不同的协议,ping值很低,但tcp重传很高的话,也很难说网络没有问题。不过定位的难度确实很大,就不清楚是什么问题造成的。
往下走我也没有什么思路了。看看其他大神是否有更好的办法。