【 TiDB 使用环境】生产环境
select * from t1 where id in (select id from t1 where id > 432100 order by id asc limit 4000);
批量sql如上,研发代码中每次将查询的结果存放到内存中,然后取最后一条数据的id值作为最大值,给下一批次使用;
在没有升级前是5.4.3是正常的,最后一个值就是最大值,升级到6.5.3后,批量压测出现问题,经过排查发现最后一个值不是最大值了,最后导致整个业务出现重复数据;
用6.5.5这个版本去测试,发现问题不再出现,也就是说在6.5.5问题修复了;
请问6.5.3是否有什么参数可以控制这个排序?
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
select * from t1 where id in (select id from t1 where id > 432100 order by id asc limit 4000);
这跟版本没关系吧,select * from t1 where id in (select id from t1 where id > 432100 order by t1_id asc limit 4000);你这个sql后面是不是应该再排下序就行了。select * from t1 where id in (select id from t1 where id > 432100 order by t1_id asc limit 4000) order by id asc;
是的,这样改是可以解决问题的,但是这个是批量,修改一次就要发版,压测,不知道有没有参数可以控制,之前在5.4.3还是没问题的
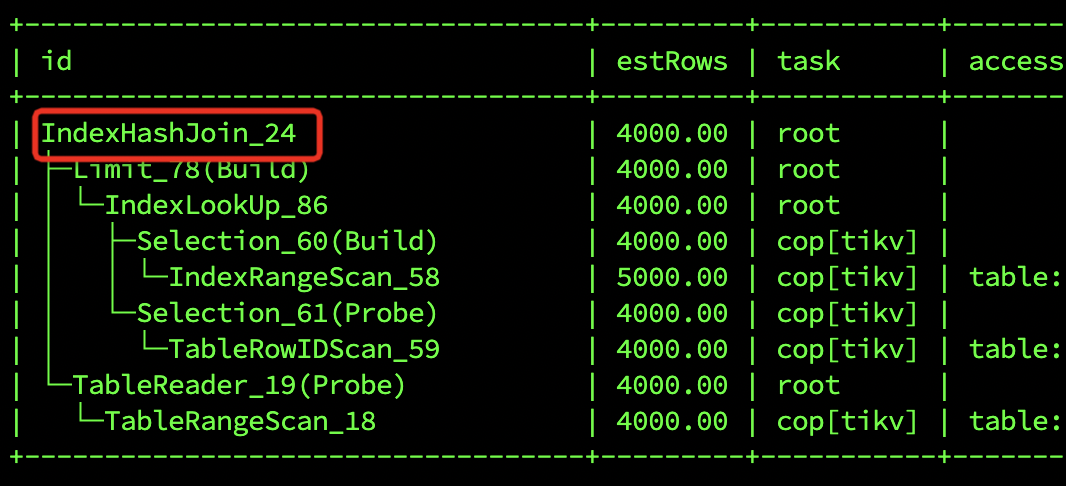
explain 对比一下执行计划,如果执行计划一致,那可能是个概率问题。
这个问题不能依赖执行计划保证,比如hashindexjoin不能保证记录顺序,indexjoin应该可以。他说6.5.3有问题,应该走的hashindexjoin。但是这个问题并不是数据库的事情,还是使用的问题,可以用分页函数处理。
来自 @人如其名
人如其名
2023 年10 月 20 日 15:12
8
2 个赞
请问如何能让6.5.3这个版本也强制使用index_join
人如其名
2023 年10 月 23 日 03:46
11
研究下hint,加index_join的hint,不过需要修改语句或者用绑定执行计划方式。没有参数直接关闭index_hash_join。另外一种是修改评估成本来左右优化器的偏好,这样就可以不动程序了,但是这个你应该搞不定,需要对tidb有较深入理解才行。
找到原因了,是代价模型的原因,参数是 tidb_cost_model_version,6.5.3使用的是2,5.4.3是1
https://docs.pingcap.com/zh/tidb/v6.5/cost-model
1 个赞
zhanggame1
2023 年11 月 10 日 02:17
14
写sql的有个原则,除了order by 任何语句都不保证顺序
system
2024 年1 月 9 日 08:23
16
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。