
目前的集群,为啥我analyze table test表,需要13分钟? 关键目前这个test表还是一个空表,表结构如下:
CREATE TABLE test (
id int(11) NOT NULL,
PRIMARY KEY (id) /*T![clustered_index] NONCLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
这个表是新建的吗?以前灌过测试数据么?
新建立的表,没有往里面插入过一条数据的
上集群的配置信息,cpu,内存,磁盘类型等等
2、3、4、5、11 tidb-server 配置:CPU:24 内存:64G,磁盘NVME
pd:3、4、5
tikv-12,13,14,CPU:24 内存:64G,磁盘NVME
tiflash:2,11 CPU:24 内存:64G,磁盘NVME
另外我问一下,你们线上统计信息是自动收集的吗?为什么我的统计信息控制在00点到06点之间收集,但是白天dashboard里面却能查询到自动的统计信息?
空表13分钟。。。。看下集群拓扑和资源利用率吧
为了性能是不是可以考虑把这个空表drop掉呢
analyze 可以自己配置是否自动,自动收集是单线程的,优先级很低,手动处理是多线程的,高优先级
后面迭代的版本,会考虑优化这个收集模式,尽量不占用更多资源的情况下,加速收集
drop 重建再跑下试试呢?
另外可以show table XXX regions看看有多少空间占用
看看他的执行详情,和其他正常的analyze对比一下,有啥区别
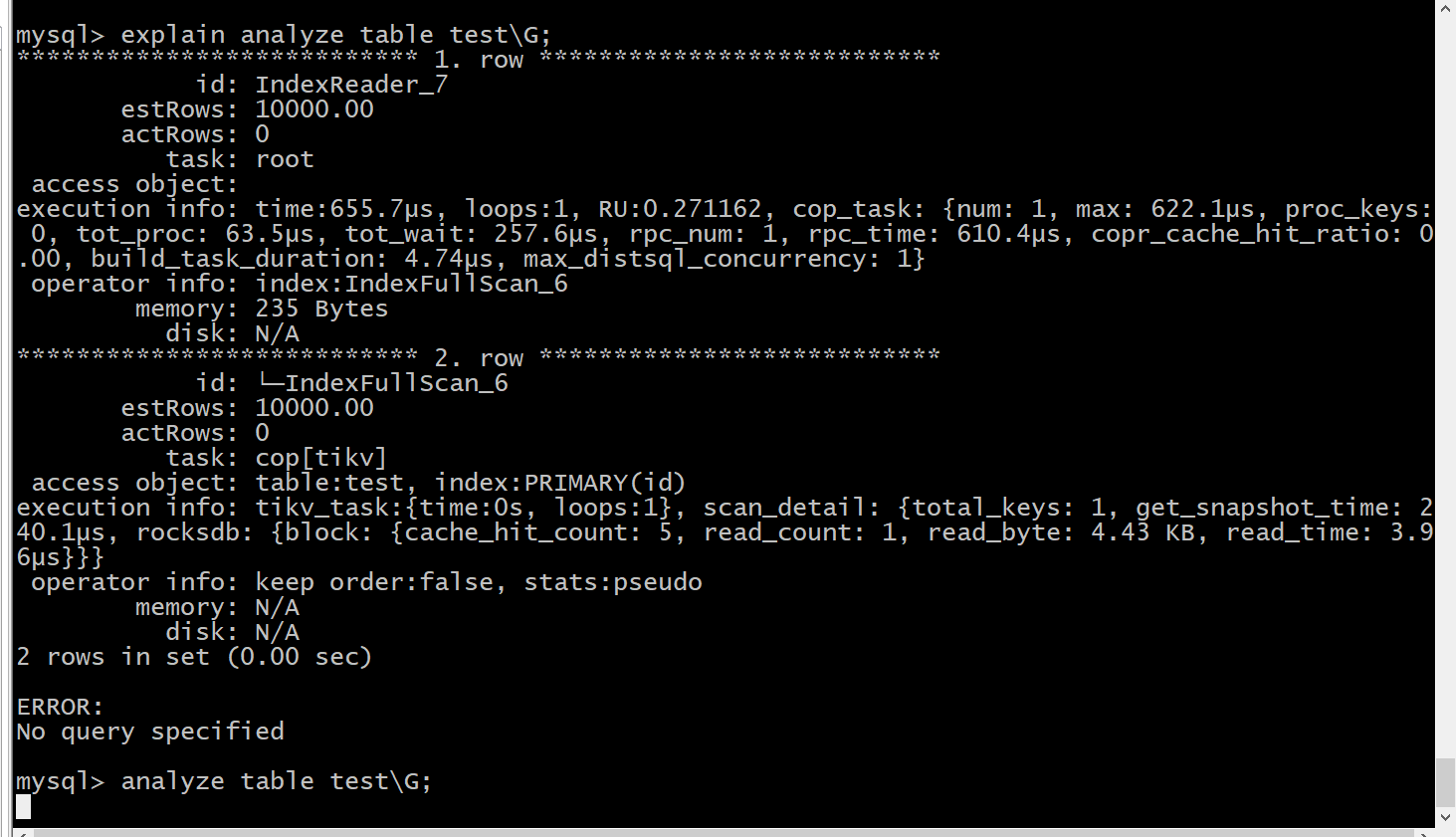
用EXPLAIN ANALYZE看一下时间花费在哪里了
tidb dishboard 里面有执行详情,看看那个,时间都花费到了哪里
\G 和 ; 的作用是一样的, 要么用\G不加分号,要么直接用“;”号,不要用 “\G;” 要不就会报 ERROR: No query specified,不过这个不影响,你这表确实没数据,走的还是主键索引,看着没啥问题啊
磁盘io正常吗?
重启集群服务看下情况,以及通过dashboard监控看下服务器的内存和cpu资源使用率