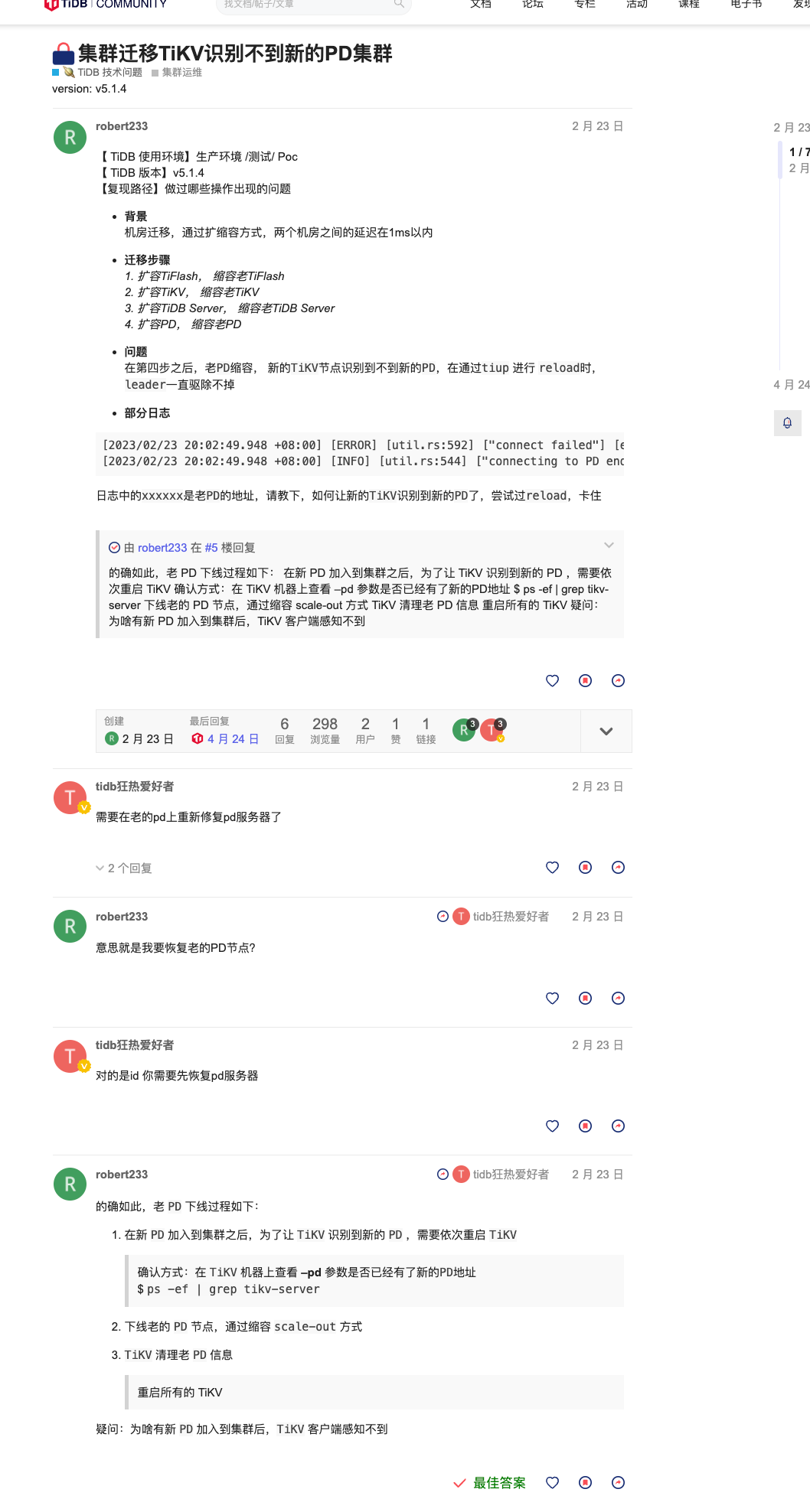
【 TiDB 使用环境】生产环境
【 TiDB 版本】
v6.1.0
【复现路径】做过哪些操作出现的问题
原有 10.29.0.158:20160、10.29.0.20:20160 、10.29.0.21:20160三个节点,后来因为 10.29.0.20 的磁盘需要更换,就把集群的 max-replicas 设置为了 2
tiup ctl:v6.1.0 pd -i -u http://10.29.0.20:2379
config set max-replicas 2
tiup cluster scale-in cluster_name --node 10.29.0.20:20160
tiup cluster scale-in cluster_name --node 10.29.0.20:2379
tiup cluster scale-in cluster_name --node 10.29.0.20:9093
tiup cluster scale-in cluster_name --node 10.29.0.20:3000
tiup cluster scale-in cluster_name --node 10.29.0.20:9090
过了 2 分钟,机器磁盘更换为之后
就把这些进程又加回来了
tiup cluster scale-out cluster_name --node 10.29.0.20:20160
tiup cluster scale-out cluster_name --node 10.29.0.20:2379
tiup cluster scale-out cluster_name --node 10.29.0.20:9093
tiup cluster scale-out cluster_name --node 10.29.0.20:3000
tiup cluster scale-out cluster_name --node 10.29.0.20:9090
tiup ctl:v6.1.0 pd -i -u http://10.29.0.20:2379
config set max-replicas 3
副本改为了 3
但是不管我怎么操作 10.29.0.20:20160 ,一直都是 offline, scale-in -force 也还是报错。
于是加了一个实例 10.29.0.20:20161 来组成三副本。

期间把三个 10.29.0.20:2379、10.29.0.21:2379、10.29.0.158:2379 都 scale-in 和 scale-out 一遍,但是还不行。
后来参考到有网友说需要重启 tikv,但是我命令重启,也失败了
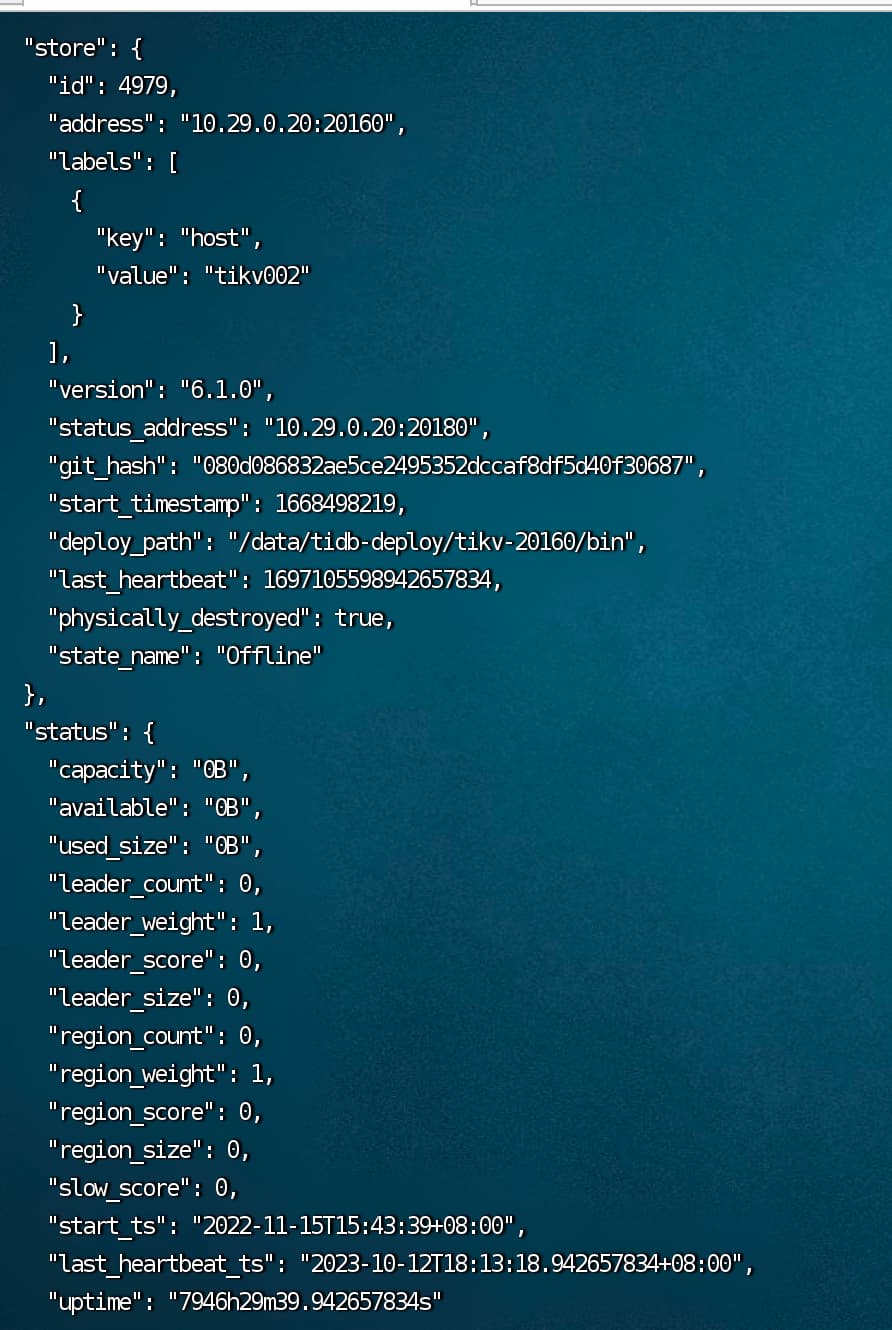
tiup cluster reload cluster_name --node 10.29.0.158:20160
tiup cluster reload cluster_name --node 10.29.0.21:20160
reload cluster_name --node 10.29.0.158:20160 错误

详细 debug 日志
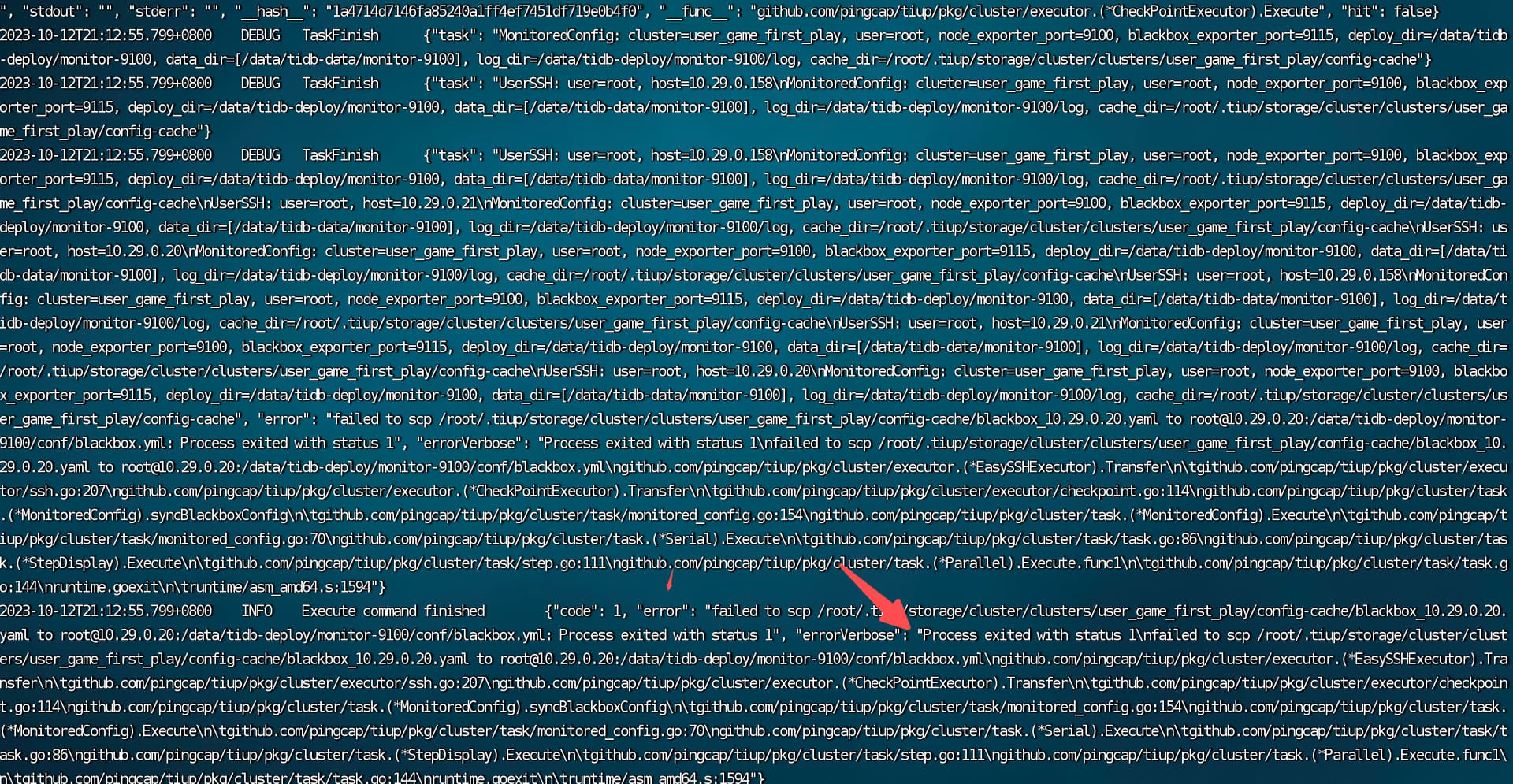
查看 10.29.0.21:20160 进程情况,发现它的 pd 还是非常旧的,和这个有关吗
ps -ef | grep tikv-server
--pd 10.29.0.19:2379,10.29.0.158:2379
接下来我要怎么办呢
【遇到的问题:问题现象及影响】
tikv-rust 客户端错误
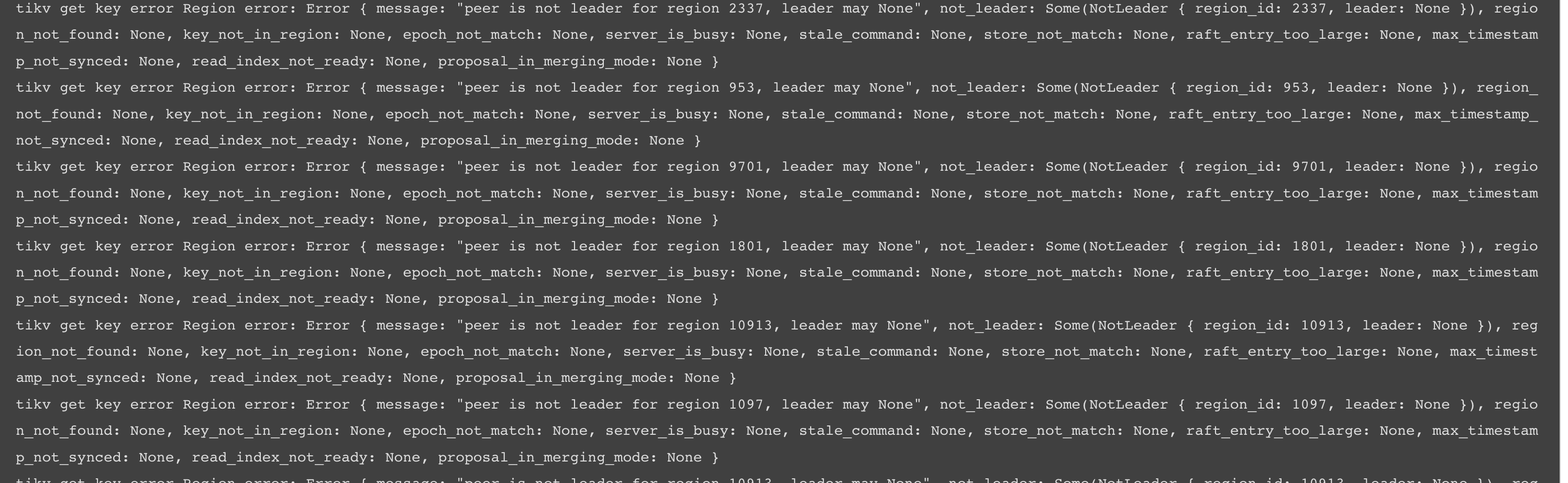
10.29.0.21:20160 进程报错日志
10.29.0.20:20160 进程报错日志

【资源配置】
【附件:截图/日志/监控】