可以尝试做个压力测试
https://docs.pingcap.com/zh/tidb/stable/benchmark-tidb-using-sysbench
按上面那哥们该行格式试试
好的,我先试试看,有结果我及时同步,谢谢大佬


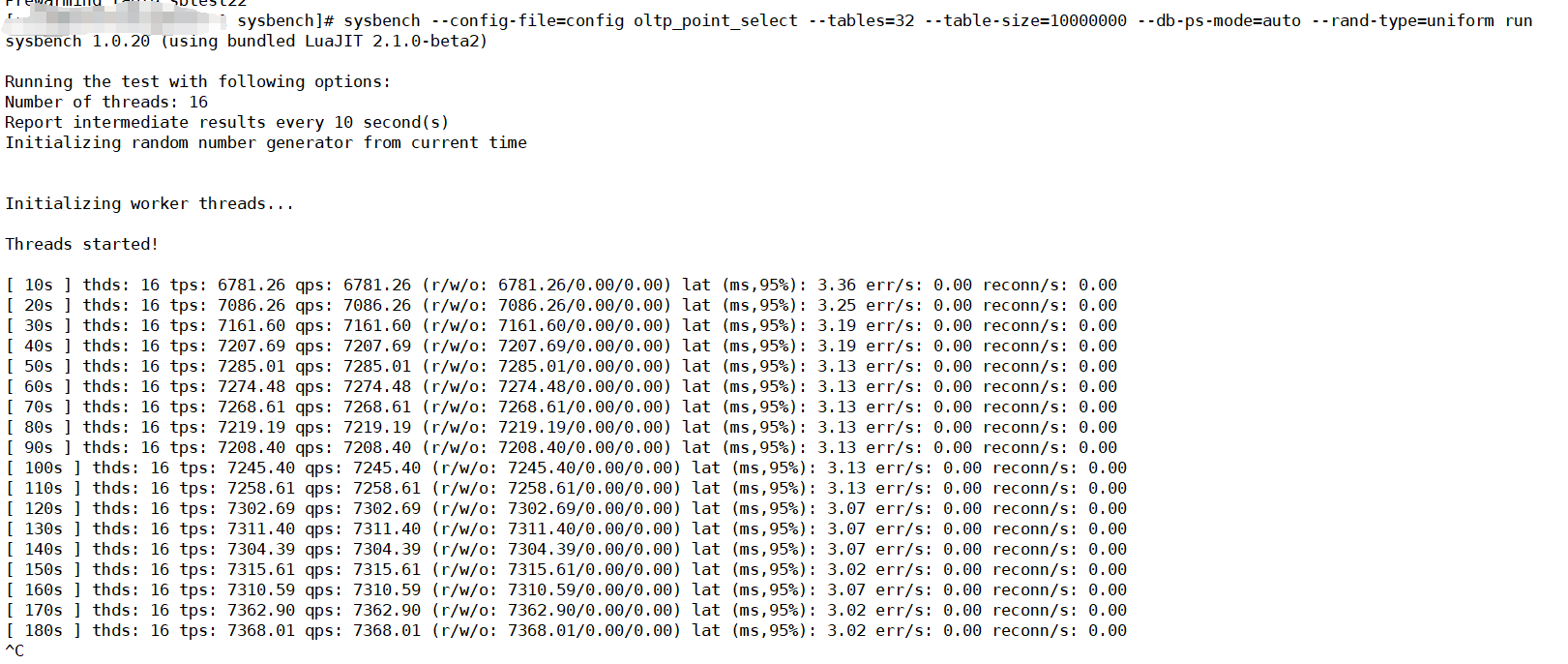
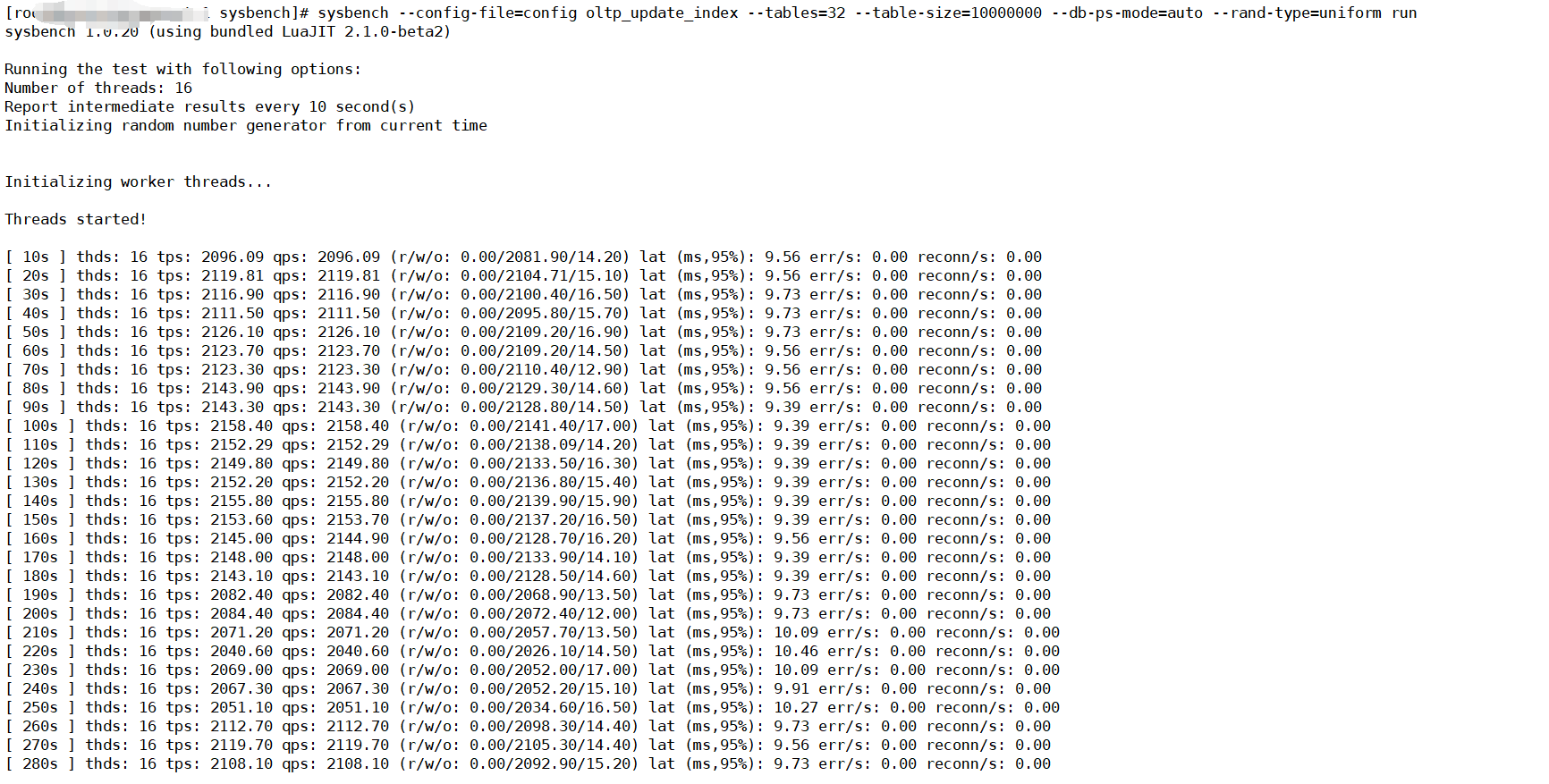
我按照文档,做了压测。先导入了数据然后做了数据预热,因为涉及同步数据的话,更多的是delete和insert ,所以此处我测试了select。和update的测试,结果如下
select的结果
update 的结果
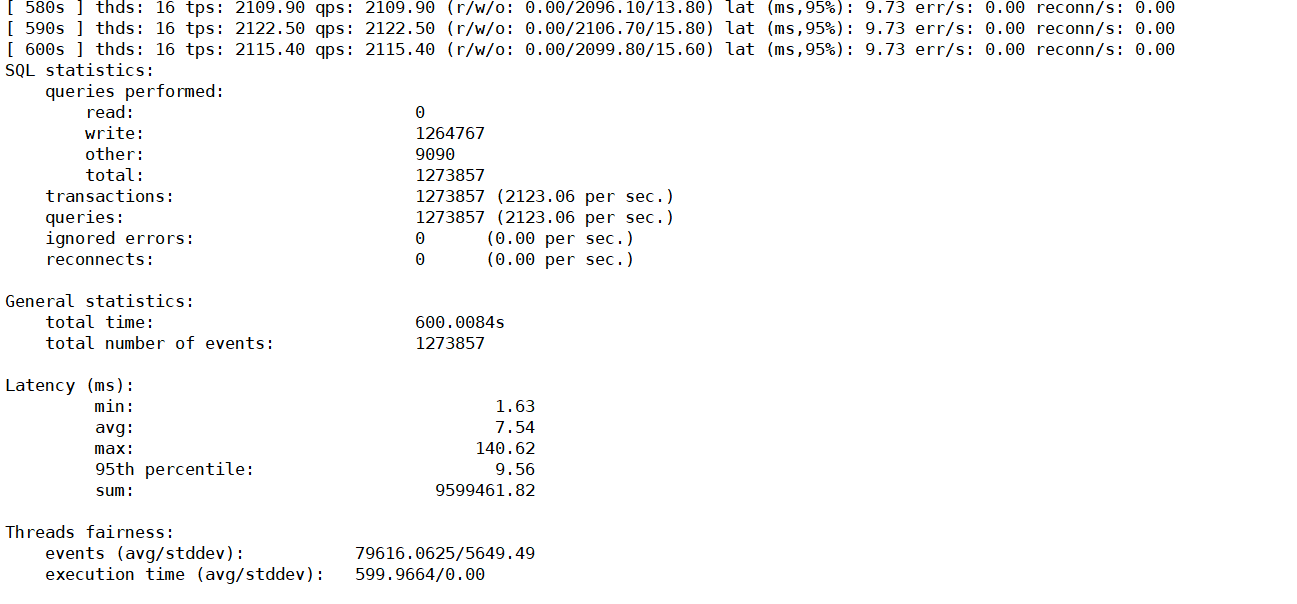
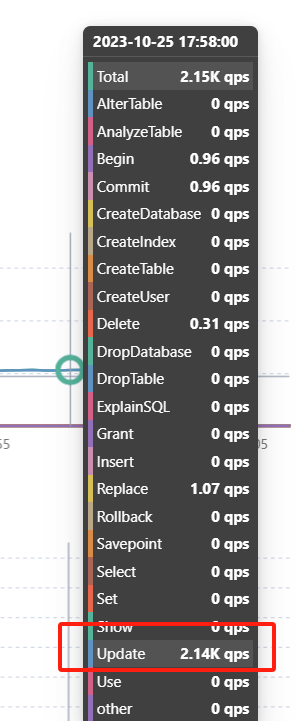
看压测结果,update这个qps在2120左右浮动,在cdc同步时,qps也在2k左右,但是cdc同步的更多操作是delete和replace,如下图是cdc同步大表数据时的qps监控
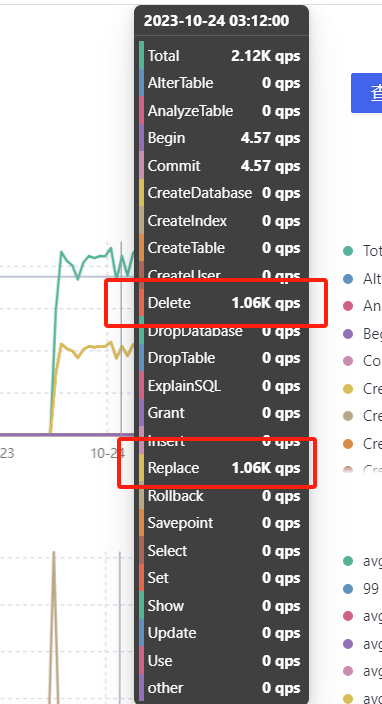
下边图是压测是update的qps的监控
查看了tikv的监控,磁盘基本处于io满载的状态了,如下监控所示。

我还有个疑问,我们主库的qps最高也才一百多,,照理来说,同步完全没问题啊

可以在从库的dashboard中看下topsql和sql语句分析中看下sql的分布
我之前竟然没开启 ![]() ,,看来明天得在到一波数据了
,,看来明天得在到一波数据了 ![]()
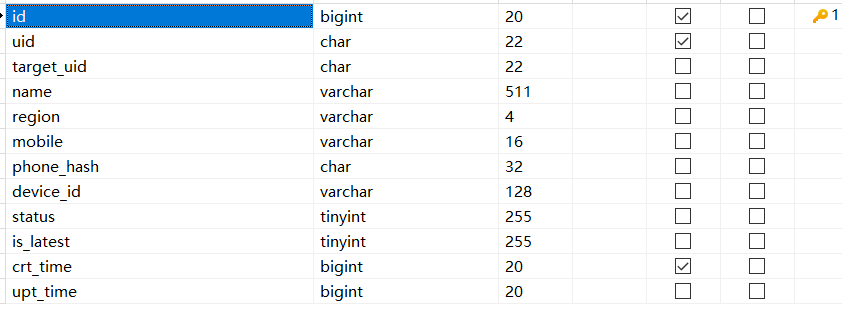
这几个慢的 table 表结构看看。
重新从主库导出数据导入从库。然后重新配置的cdc数据同步。昨天下午两点多搞完的,到现在5.5亿+ 数据的单表同步任务延迟又已经增加到了 7 小时。昨天配置完延迟是3小时。 看了下tidb的 dashboard监控。qps在3k左右如下图
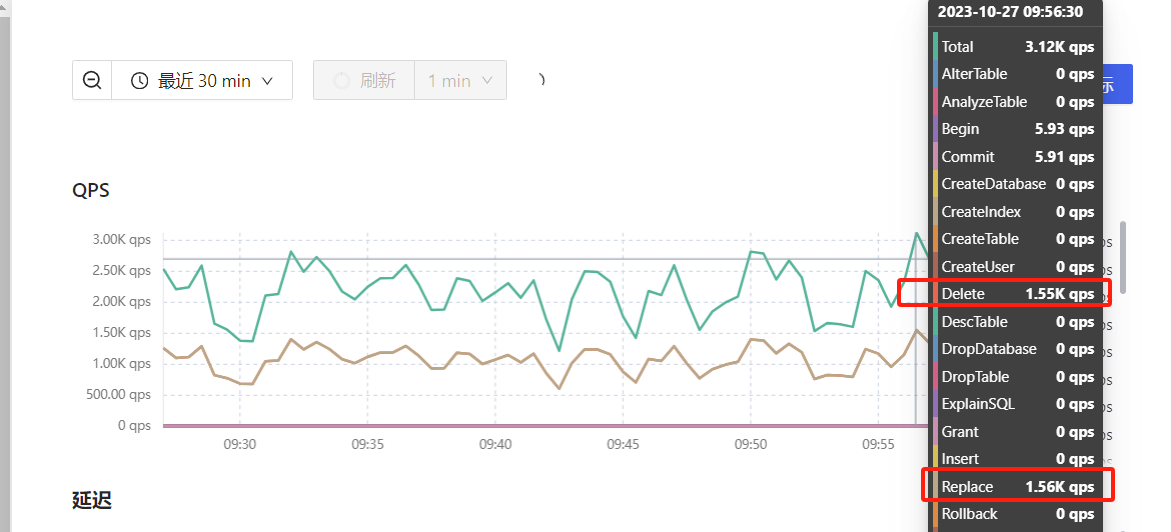
查看topsql 最高的是delete 和replace 如下图
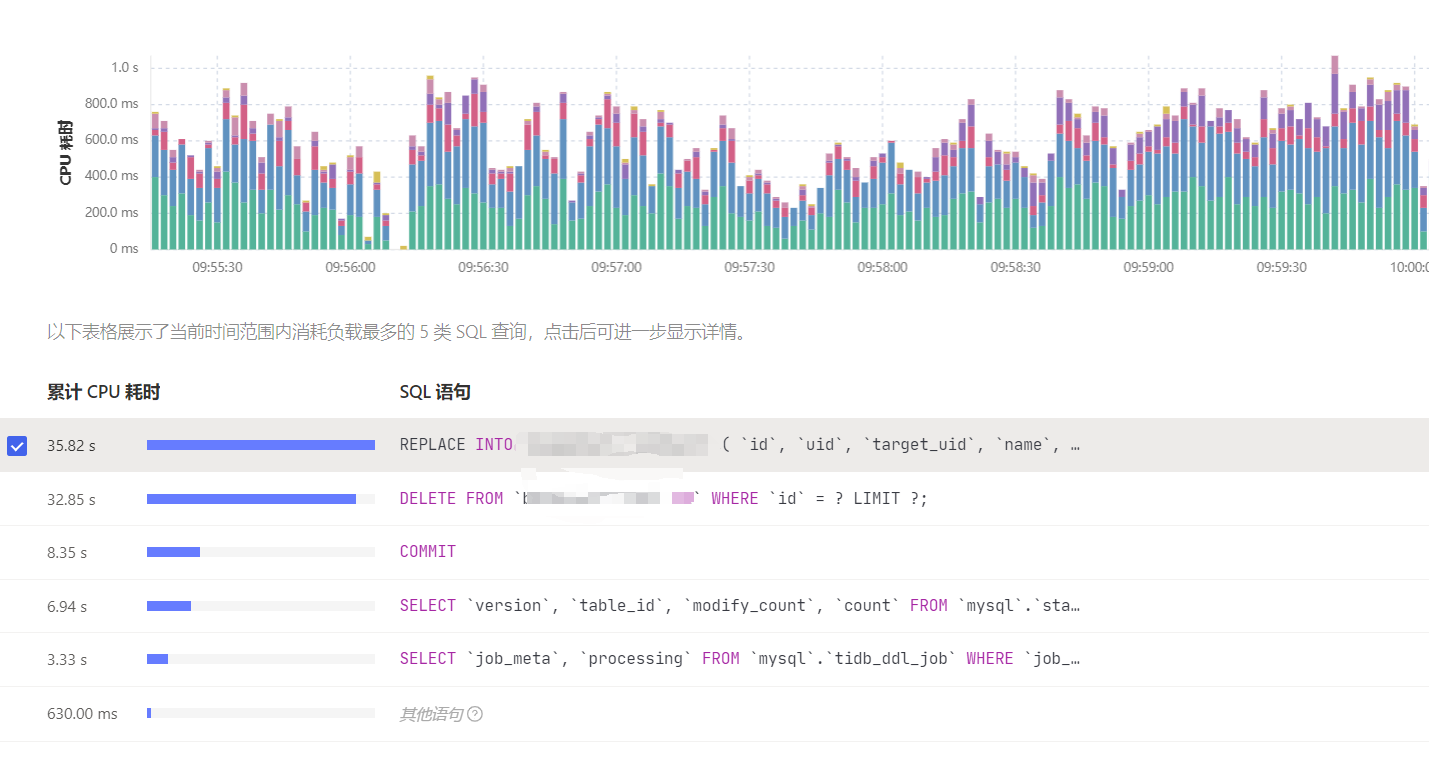
在sql语句分析中, sql的主要分布也是delete和replace如下图所示

你这从库大部分资源都消耗在delete上了,业务上优化下,不然就要加资源了,你这不会是机械盘吧?
不是机械盘,是阿里云的云主机,挂载的ssd类型磁盘,iops在7800左右。
另外,主库的qps在150左右,从库虽然同步数据qps最高在3000左右,但是delete和replace是ticdc的行为,业务上多是update的操作。