可以再建一个任务试试,把数据分为两份,做过滤复制,看看
可以先看看有没有帮助 我这是有个别任务偶尔会出现这个情况, 所以还好。
cdc三台机器的配置都是8c16g的,cdc资源是够用的。如果要是硬件差距,唯一可想的就是从集群的db和kv都是8c16 .主集群是16c32g的。
数据分为两份是指?我现在需要同步三个库,一个库比较大160G多。另外两个小,每个5G多的数据。是每个库都单独写一个同步的cdc 任务么?
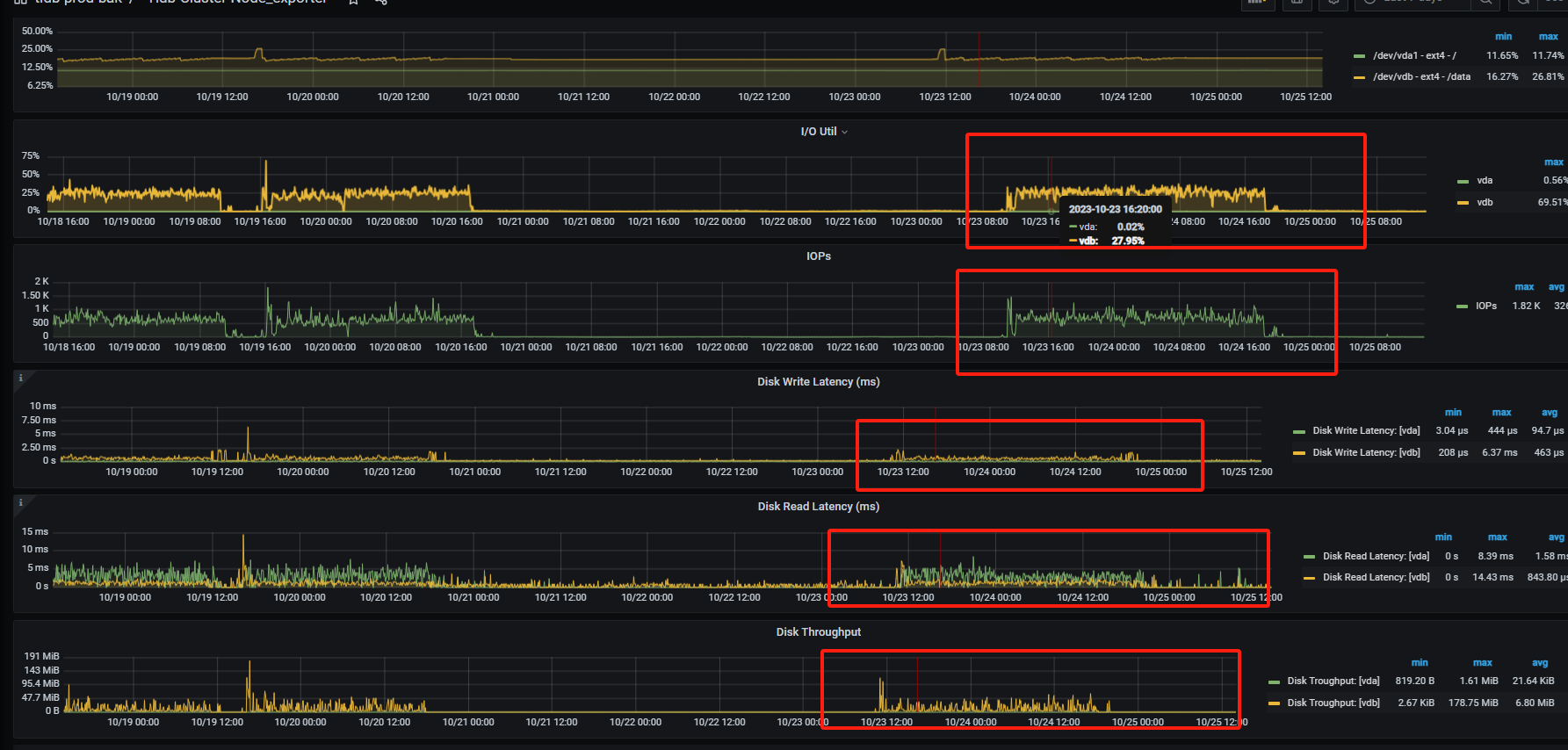
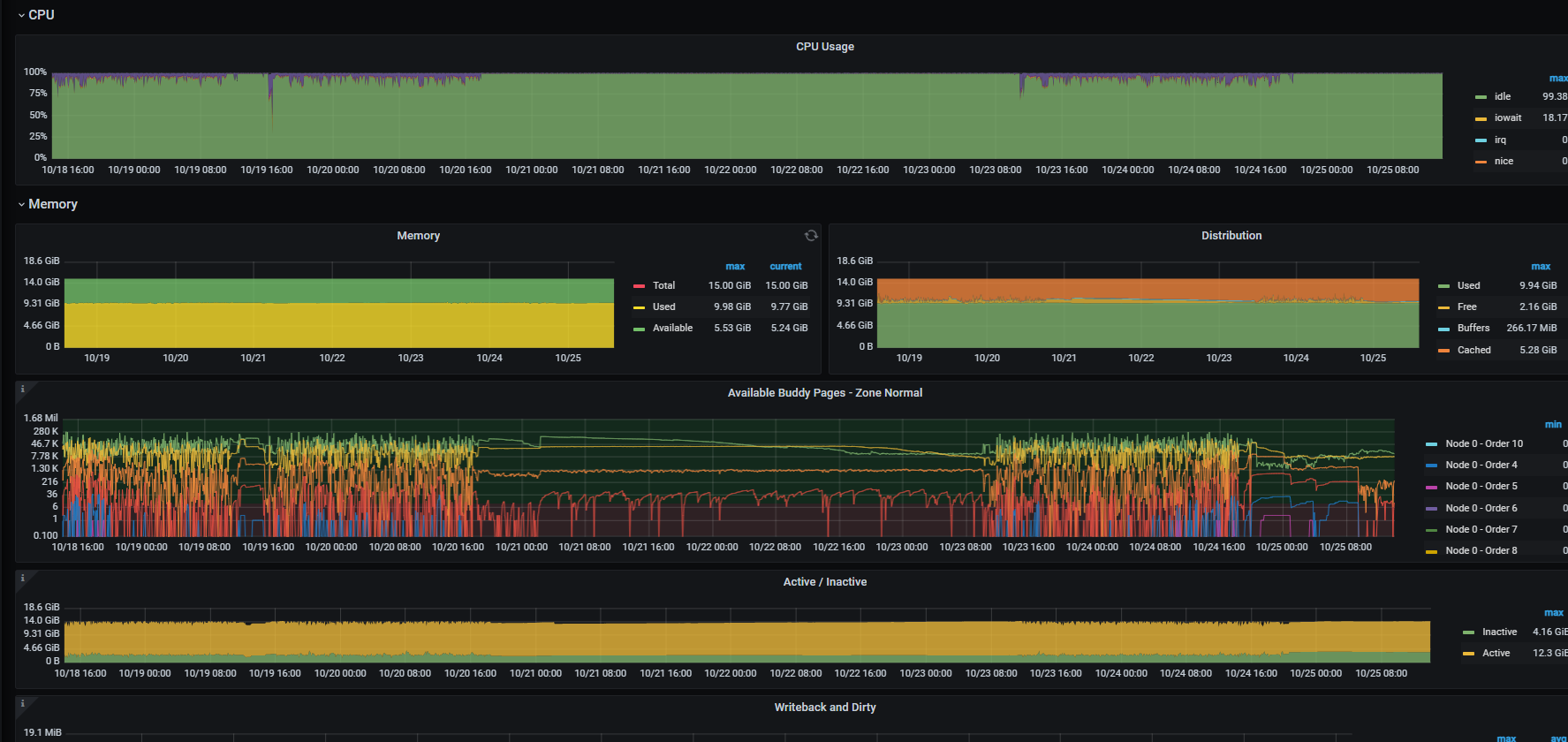
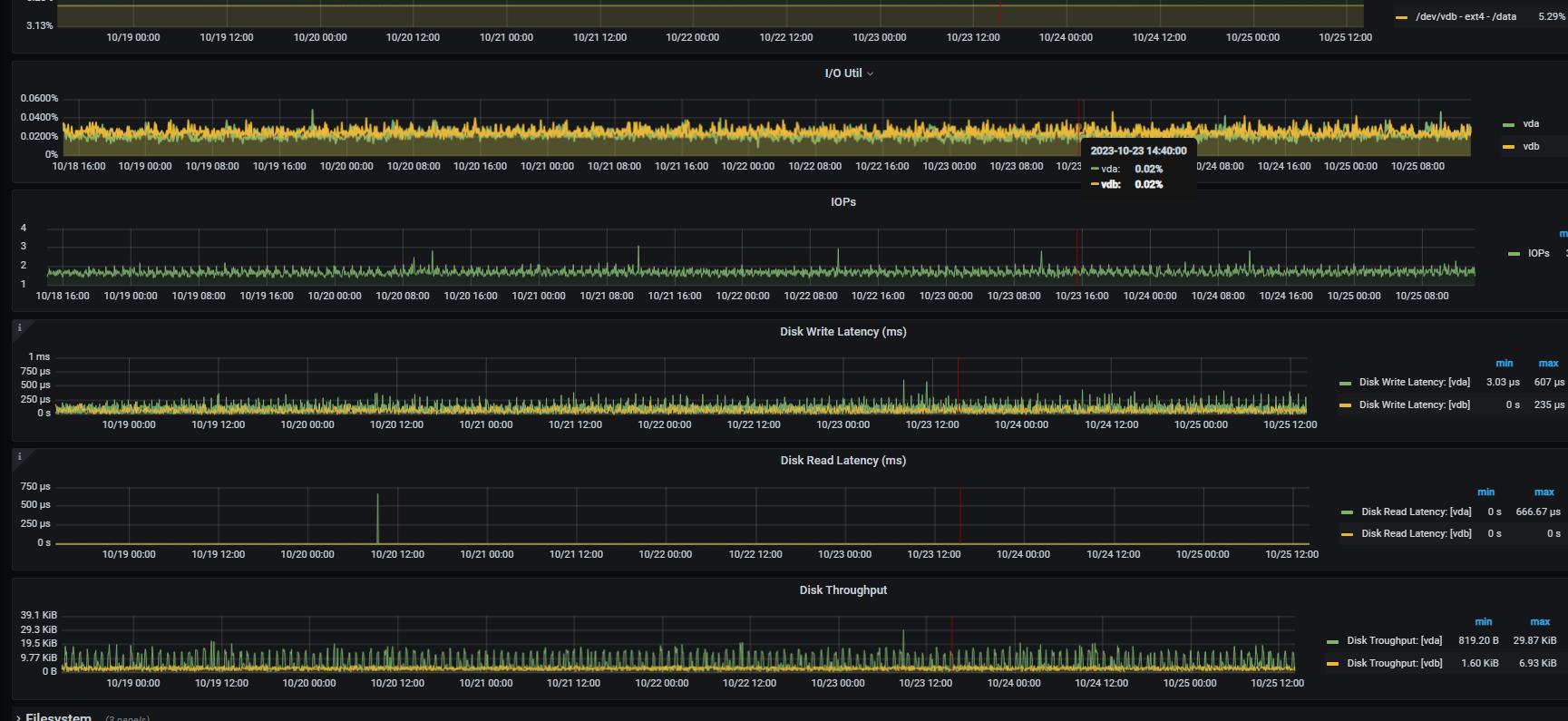
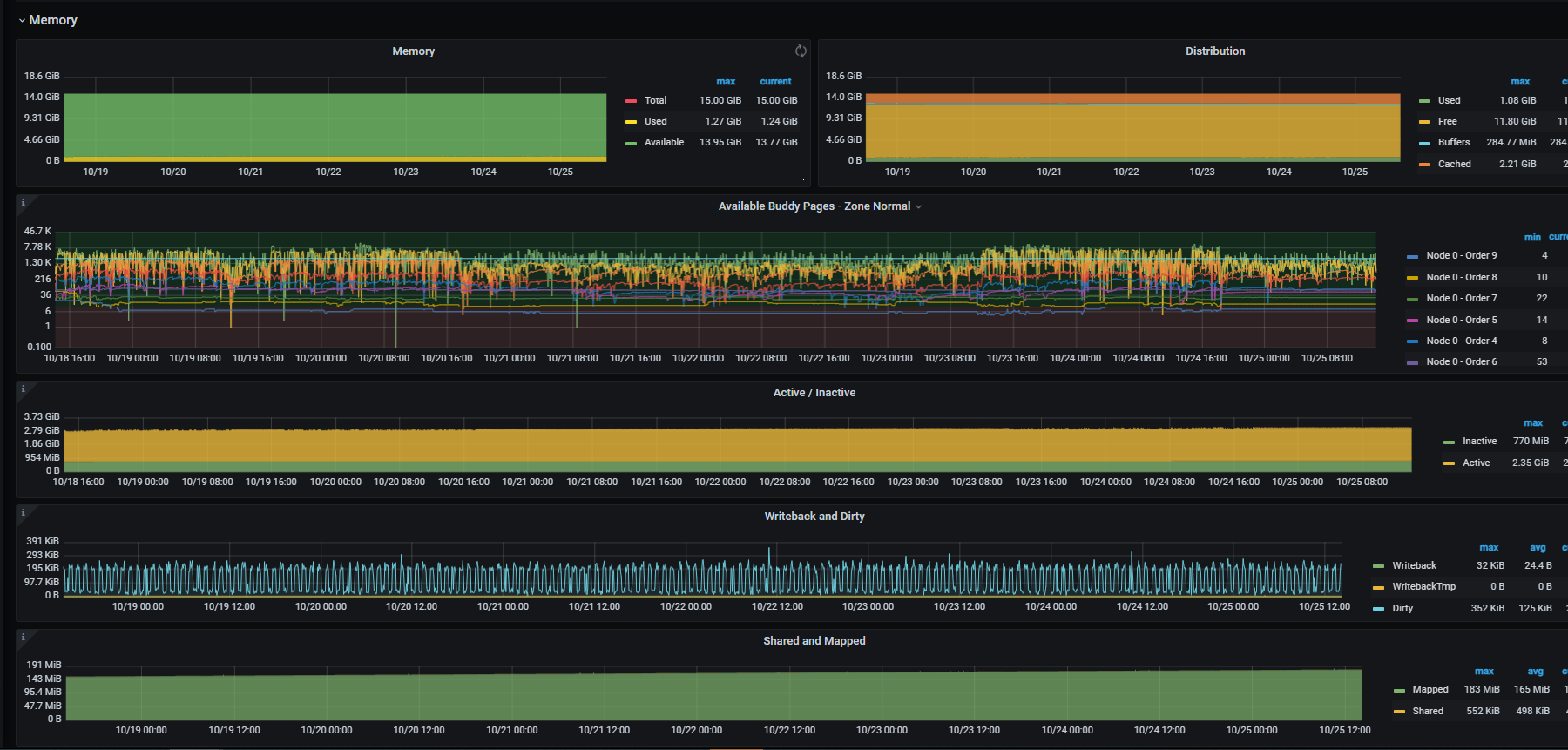
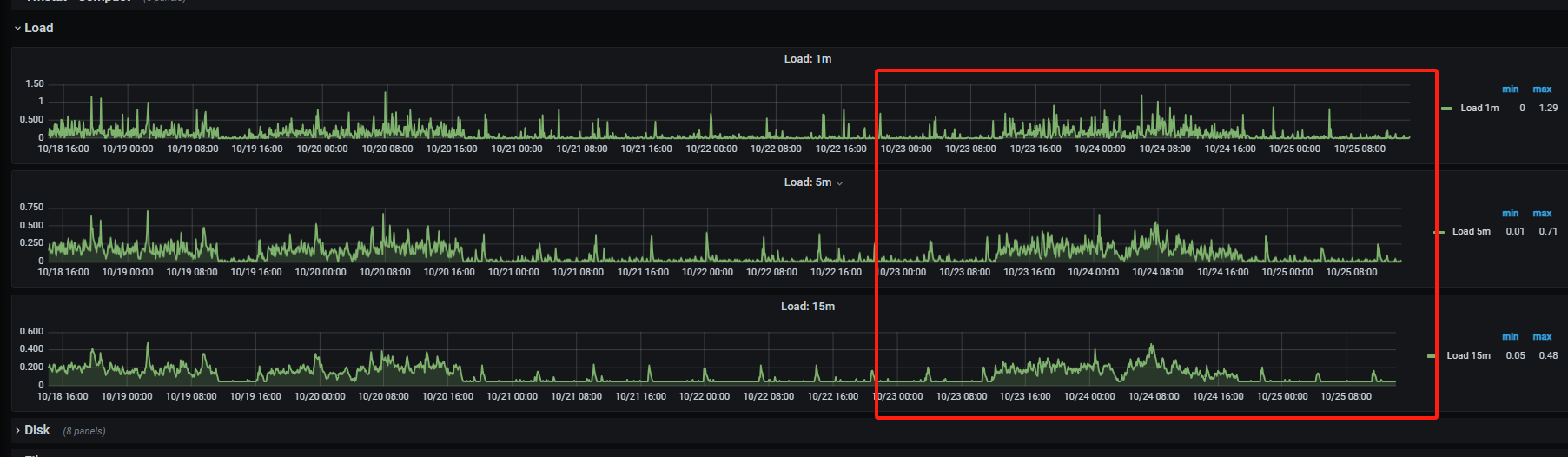
主机负载是否存在异常,检查主机IO
检查表结构的行格式和表排序规则
我同步了三个库,数据量分别是170G,5G,100M 。 我现在把5G的和100M的放在了同一个cdc的任务中。另外170G数据的用一个单独cdc任务。然后发现170G的这个同步任务从启动时指定start-ts (备份时的那个tso,延迟一个小时20分钟),就一直有延迟,然后过一晚上延迟增加到了10个小时。cdc日志中没报错。 另外的5G数据和100M数据的公用的一个cdc任务就正常,同步数据没用问题。
现在猜测,有没有可能是数据库表结构也会影响?在cdc中看到error的日志,如下所示

可以这样,我们就是这样搞得
你那个有延时的任务,是不是有某一个表在跑啥大事务,你统计一下主库sql执行情况
从上图的开始报错时间开始,同步库中的所有的表都报了此对应的错误。
https://asktug.com/uploads/default/original/4X/8/1/5/8158aaa00d2432f323e265fc7f01cc7c669777e4.png
还有个问题,如果单表数据量5.5亿+ ,并且频繁的新增数据,这个会有影响么?
这个没有测试过,不过我直接把一个500G的大表隔离出来单独做了一个任务,这样即使有问题,也不会影响其他表
我按照这个方式在试试看,谢谢
500G的表的单独拎出来做任务同步正常嘛? 我试了有5.5亿条数据的那个表我也单独拿出来做了个单独的任务,但是同步还是有问题 ![]() 我现在有点凌乱
我现在有点凌乱 ![]()
我们这个表12亿条数据,偶尔有延时,大部分情况都正常,延时大部分都是加索引或者有大事务情况
你是哪个同步任务有问题,大表那个,还是其他表的,你要把,最有可能发生问题的表,dml量最大的表,单独建任务,并不多数据量最大的表单独做任务
就是5.5亿多数据的大表单独创建的这个任务有异常,其余的都没问题了。
以下是一些建议来调整和解决这个问题:
-
检查 ticdc 配置:确保 ticdc 的配置参数正确设置。特别是需要确保 ticdc 的capture-session-ttl参数设置得足够大,以避免会话过期导致的数据丢失和延迟增加。
-
检查网络连接和带宽:确保主库和从库之间的网络连接状况良好,并且具有足够的带宽来支持数据的实时同步。网络延迟和带宽不足可能导致同步延迟增加。
-
检查硬件资源:确保从库具有足够的硬件资源来处理数据的实时同步。尤其是 CPU 和内存资源,可以根据实际需求进行调整。
-
检查 tikv 集群的负载和性能:ticdc 同步的性能也受到 tikv 集群的影响。如果 tikv 集群过载或性能不足,可能导致同步延迟增加。可以通过监控 tikv 集群的指标,如 CPU 使用率、磁盘 I/O 等,来评估和优化 tikv 的性能。
-
检查数据量和写入负载:如果主库上的写入负载非常高,可能会导致同步延迟增加。可以考虑优化主库的写入负载,如调整应用程序的写入逻辑、增加主库的硬件资源等。
我按照你发的这几点查了下。
第一点,cdc配置用默认的,使用tiup安装,没做调整。
第二点,阿里云的内网,网络确认没问题
第三点,硬件资源主集群都是16c32g 从集群是8c16g 查看监控负载都不高,处于正常状况
第四点,kv集群的cpu,内存,io等都处于低负载状态
第五点,虽然表数据总量现在5.5亿多条,然后按照高峰时间段每小时三万多条的进度在涨,但是总体量不算太大,主库是三个16c32g的tidb 和五个16c32g的kv集群。从库是两个8c16的tidb以及五个8c16g的kv。
然后 cdc的这个值 capture-session-ttl 默认是10s 有必要调大么? 这个到多少合适?
调整了 capture-session-ttl 默认是10s ,调整到了20s 。还修改了cdc中的配置per-table-memory-quota: 默认是10M,我调整到了500M。
重新配置同步任务后,tso本身相差 3小时,然后配置好后追补数据到了 相差 0.5 小时。然后对比了下数据库中的数据总量相差两千条,。但是隔了一晚上,tso差距又变大了,并且差距又在逐渐增大。到现在更新此贴,tso以相差 11 小时。 ![]()
![]()
![]()
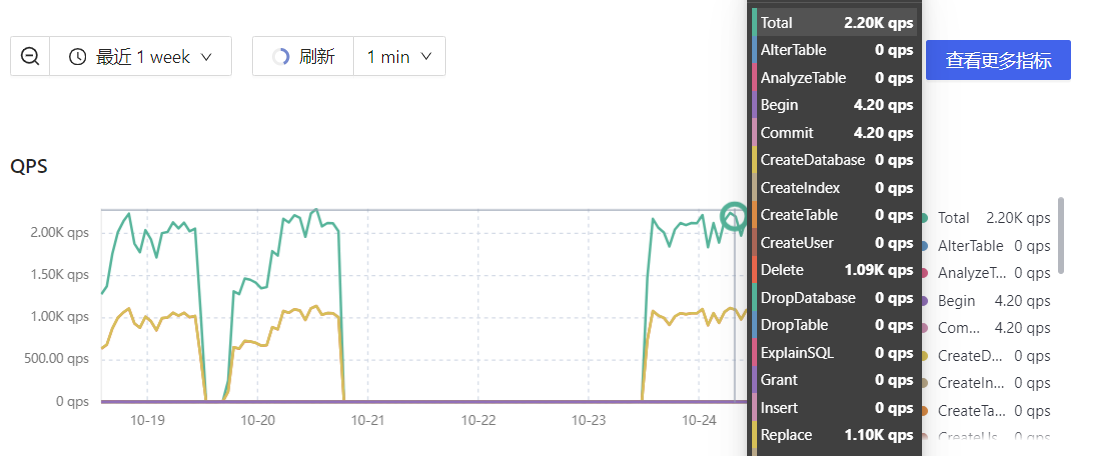
监控下从库的qps 磁盘io情况呢有没有到瓶颈