如果需要更具体地案例分析,可能你需要提供更多地细节哟~
刚提了个建议
我尝试一下,辛苦了
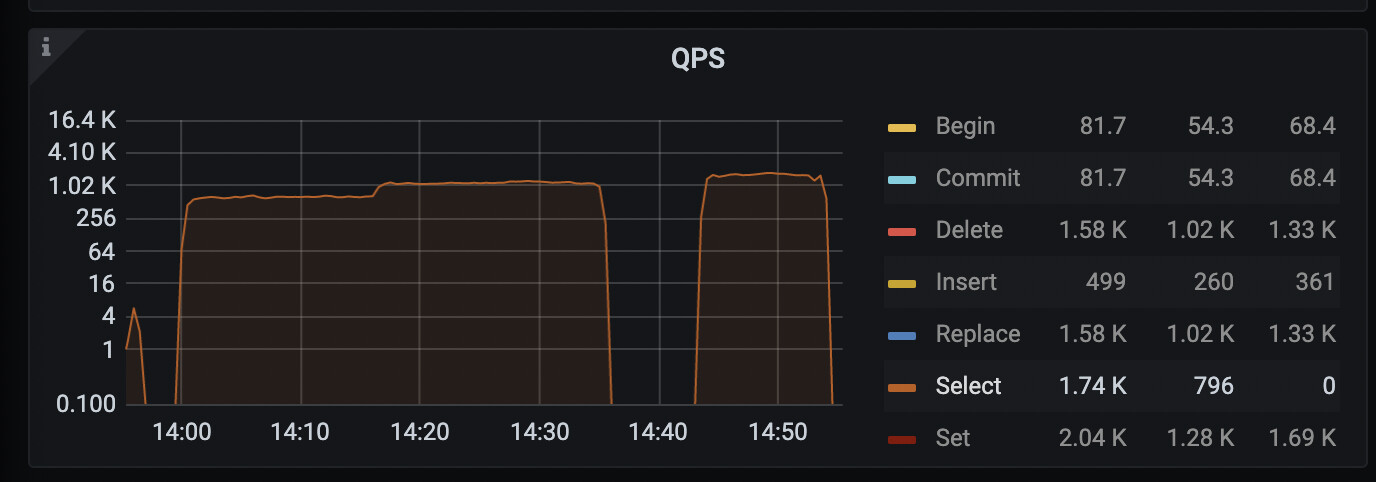
我把读写都停掉了,状态如下图
tidbserver内存占用:

根据您提供的方式执行结果:

从top 10的结果看,这里有两个问题:
1、48.8g的内存中还有50%内存没找到去向?
2、github.com/pingcap/tidb/util/chunk.(*Column).AppendBytes 这个任务是干什么的,作用是什么?
prof文件上传下看看
涉及到一些敏感数据,所以上传不了 ![]() ,从top 10里面的各个线程内存指标,算是有异常么
,从top 10里面的各个线程内存指标,算是有异常么
Dashboard 慢查询排序,就看排名靠前的语句就差不多了
线上读写都停了
QPS图就是分类的,不分类的QPS在CPS图里面,CPS里面的query-ok就是正确执行的query 总和。
有接口,或者系统试图能查到么? 我看有个库是matric_schema,里面有很多表,那里也会有记录吧
1,这个dump的是 heap,即堆内存。
2,这个应该是和写入相关的。你的这个内存占用不像是没有业务,反而像是有很多写入。
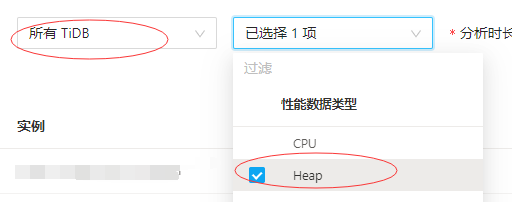
Dashbroad里面对tidb的heap分析是直接支持的。
找高级调试-》手动分析,选所有tidb实例,heap
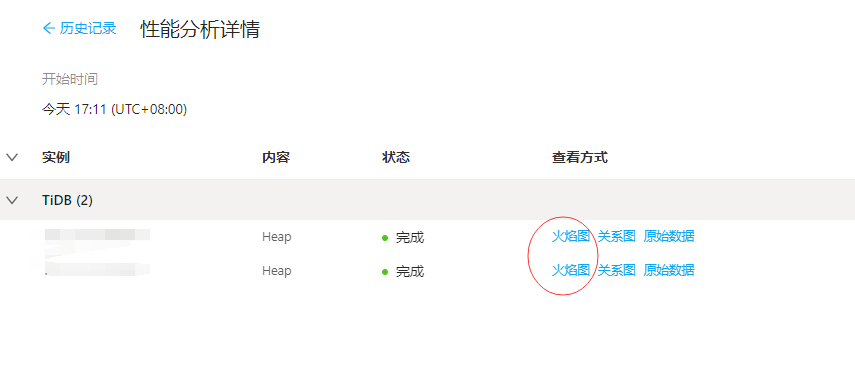
从结果里面找火焰图看看。
这个图会有类似下面这样的调用层。

这种看的比较清楚。好比上图这个,就cop cache占用高,其他基本都没什么占用。
正常CPS和QPS就是挨着的。
dashbroad和grafana里面都是如此。
grafana里是有,但是我们不用这个平台,集群规模比较大,所以要统一收集监控信息,整合到一个自建的平台上
你这个集群整体存储数据量有多少呢?
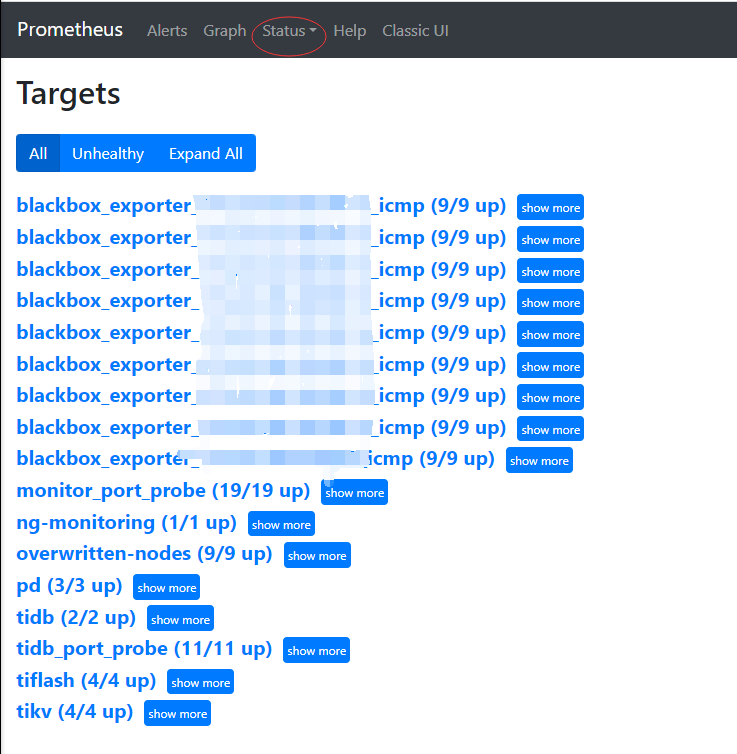
prometheus用吗?
我看下来整个tidb的监控是,pd tikv tidb都提供http的指标接口,然后prometheus调用这些接口让后存在一个时序数据库tsdb里面。然后dashbroad和grafana都是从这个库里面取的。
tidb里面即便有这些指标,感觉读取也挺慢的。你在这些库上做监控的集成,感觉本身也对tidb造成一些压力。
有prometheus的话,访问对应的9090端口,有如下这个界面,可以看到prometheus调用的其他http接口的地址和调用时间等参数。
这些信息应该对你有点帮助。
非常少,小本经营。
而且整体偏分析业务,tp的就纯上游写入。偶尔断一阵,都可以接受。 ![]()
具体可以看我专栏里面的实践。
这些可能是你需要的,多搜搜看,社区有很多这方面的实践。
好的,辛苦 ![]()
