林夕一指
(林夕一指)
1
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】V6.5
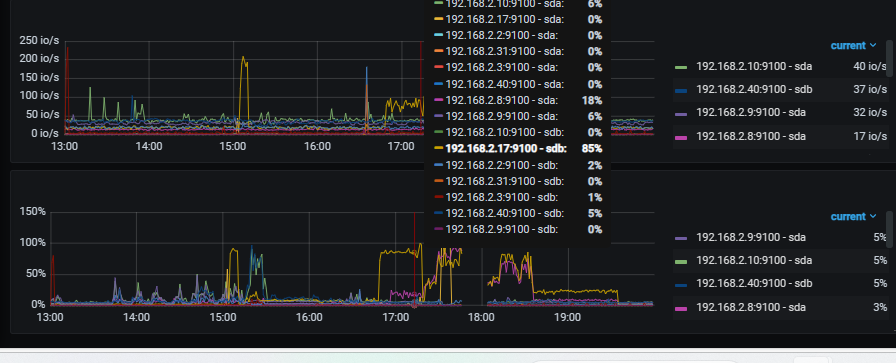
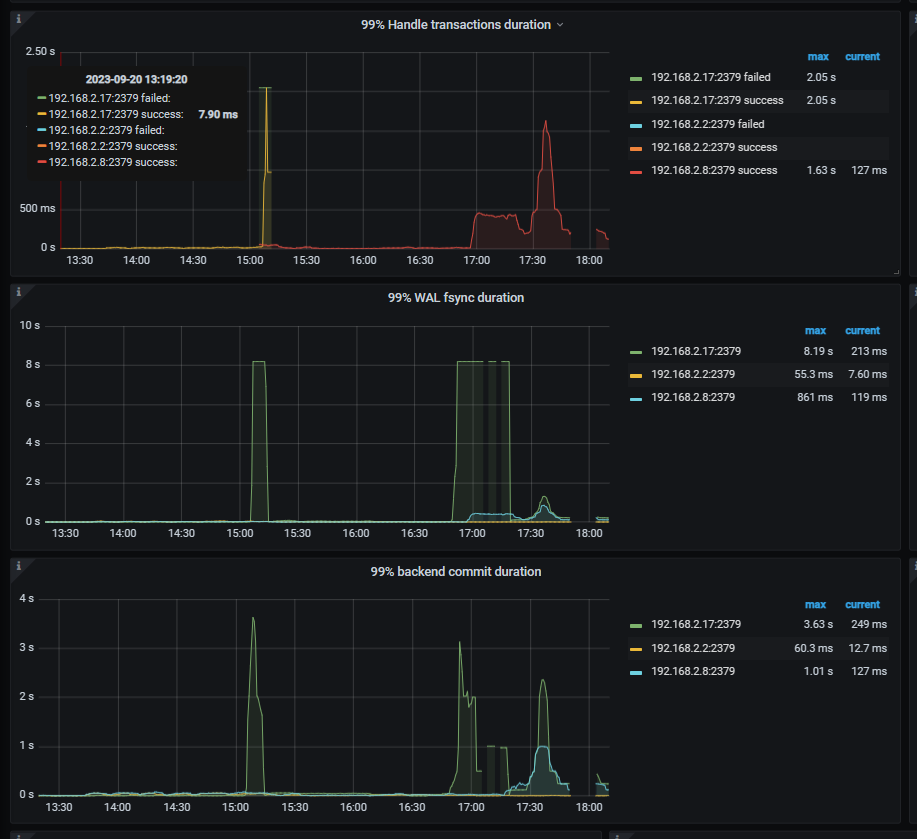
【复现路径】tidb 集群首先采用VM创建虚拟服务器进行部署,在pd leader 节点所处物理磁盘的进行磁盘io压测,导致pd leader 服务器监控IO 使用率接近100%,不就tiup cluster display 先是pd组件全体down,数据库服务不可用
【遇到的问题:问题现象及影响】 pd组件down,tidb无法访问
【资源配置】
【附件:截图/日志/监控】
pd面板下etcd
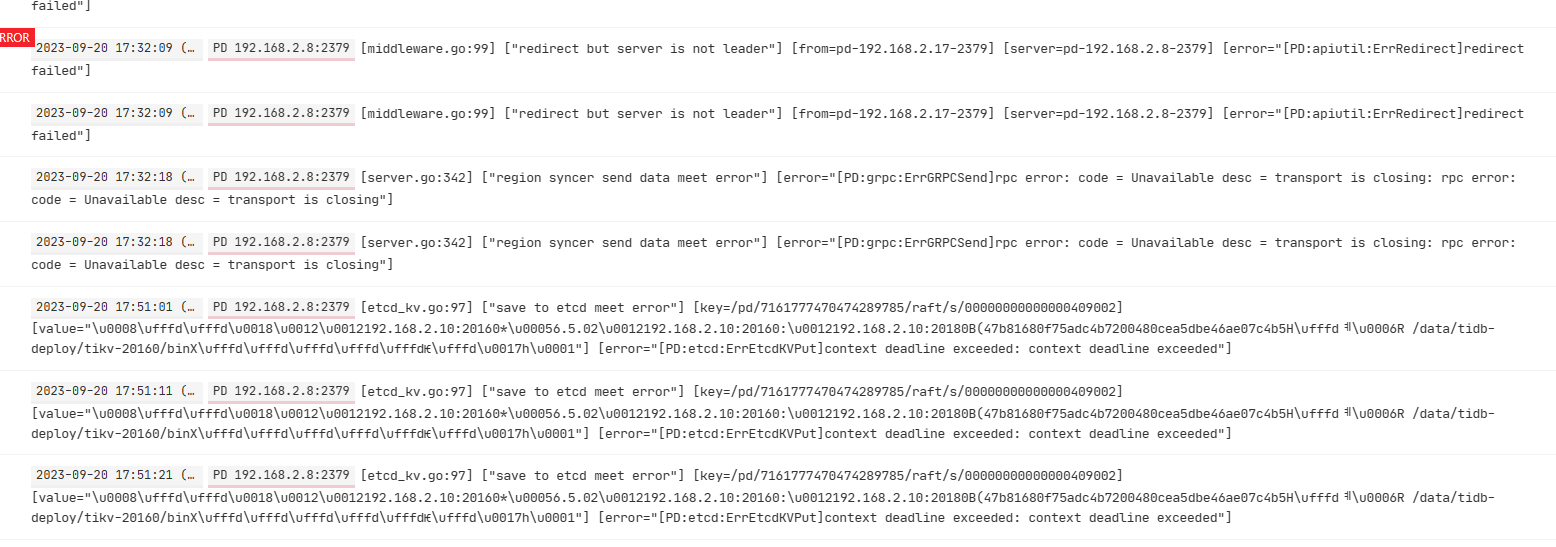
pd.log 压力初期会有大量的redirect but server is not leader 错误信息,好奇请教下这个是错误是否代表pd leader 选举出现问题
Denis
3
当发往 PD leader 的请求被接收,但发现其已经降级为 follower 时,通常会出现‘redirect but server is not leader’的情况。
不是,你对pd leader所在机器进行io测试,如果有问题了,pd不应该切换leader节点到其他服务器吗?所有的pd节点都用的同一个物理磁盘啊?
我猜你的pd服务都部署在同一台物理机的不通虚拟机里面,io压测吧这台物理机搞崩了,tiup display看看所有pd都down了吗?
林夕一指
(林夕一指)
7
vm 虚拟化的,里面就一个vsan ,说实在的我自己也不知道它使用的是哪个磁盘
你是vm虚拟机 如果虚拟机在同一台服务器上那就是共享磁盘的,你在一台虚拟服务器上压测,那整个物理服务器都会有压力,要死一起死。
这种其实你的3pd就没啥用了,一个跨其他的都跨了,也切换不了,集群肯定就无法对外提供服务了。
1 个赞