【 TiDB 使用环境】生产环境
【 TiDB 版本】
Cluster version: v5.4.3
【遇到的问题:问题现象及影响】
最近由于业务变更查询导致tidb节点频繁OOM,内存使用严重。
我不太懂SQL优化,大佬帮们我分析下SQL有没问题吧
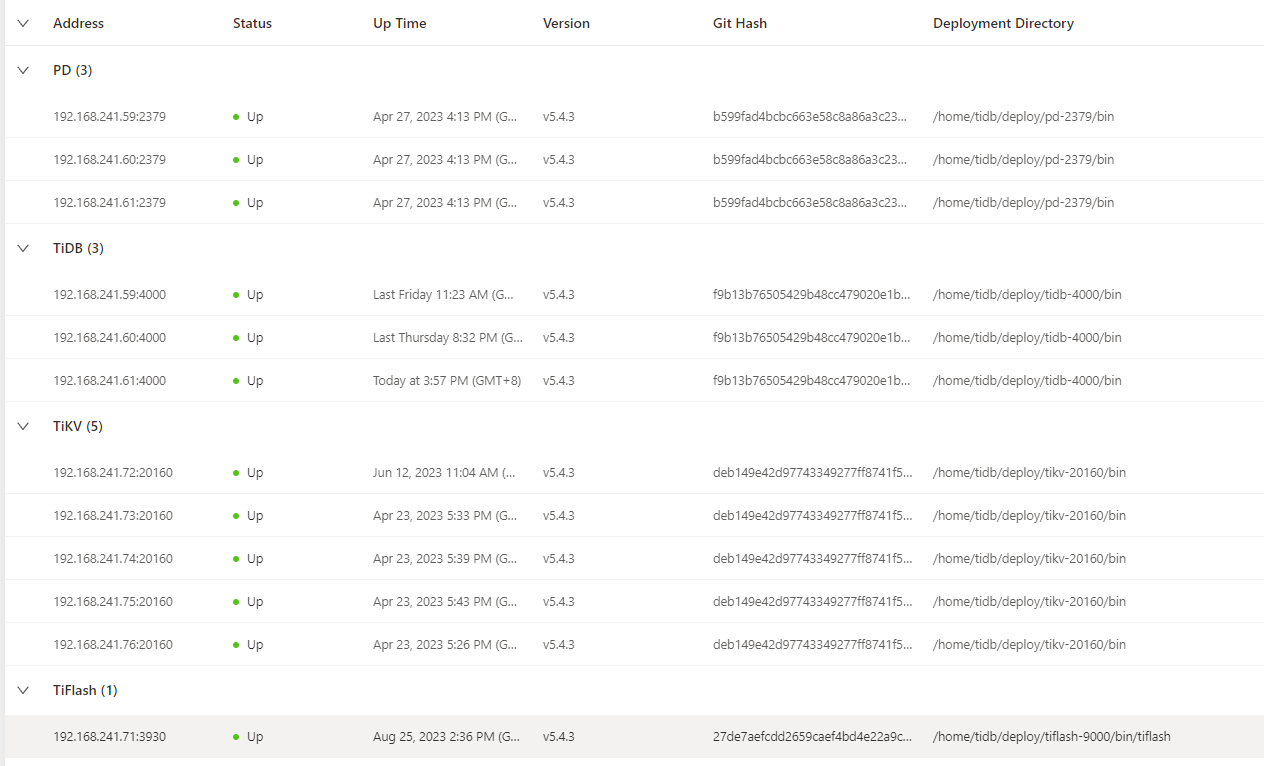
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
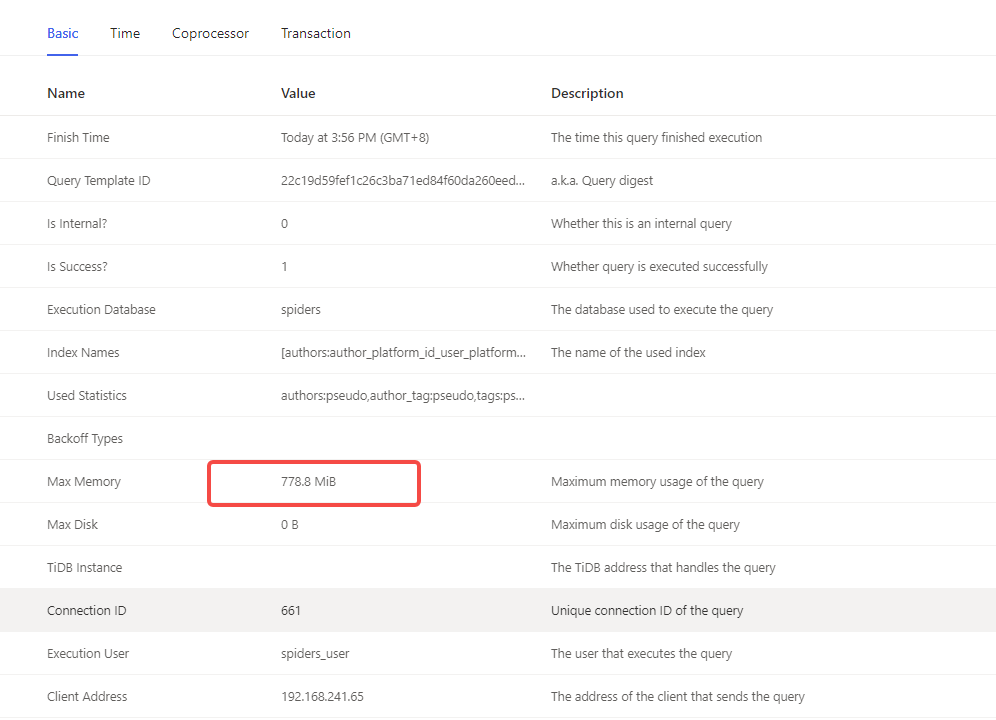
以下是在Tidb Dashboard里找的一个消耗内存较大的SQL,778M这个SQL消耗的内存有问题呀? 是不就是这个SQL导致的内存不足频繁OOM呀?
排查的话 你应该去看oom时间点的topsql 哪几个sql占用资源较多
为了防止oom系统不可用就要限制每个查询的最大内存
统计信息过旧,可以先收集看下,执行计划往后拉,可以看到actrows真实的
1 个赞
有猫万事足
4
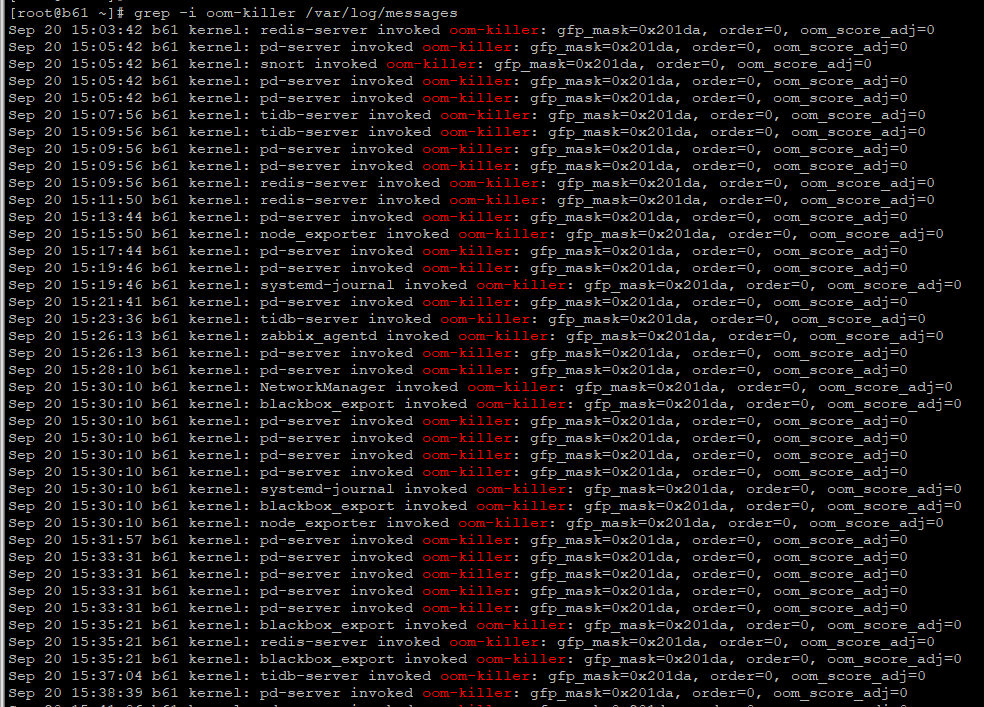
为什么你的pd被oom-killer 选中的次数比tidb还多啊。
最离谱的是 zabbix_agentd都被选中过。
这个zabbix进程我记得占用内存不超过100M。想不通怎么会被oom-killer选中的。
感觉可能是内存不够了,各个进程争抢内存,然后有的进程就触发了oom killer 
有猫万事足
11
真的不应该。
tidb 的oom_score
[root@tidb1 ~]# cat /proc/20428/oom_score
559
pd 的oom-score
[root@tidb1 ~]# cat /proc/17744/oom_score
52
我也是tidb和pd放在一个服务器的,正常来说,pd的分数远低于tidb。不应该如此频繁的被oom-killer选中。
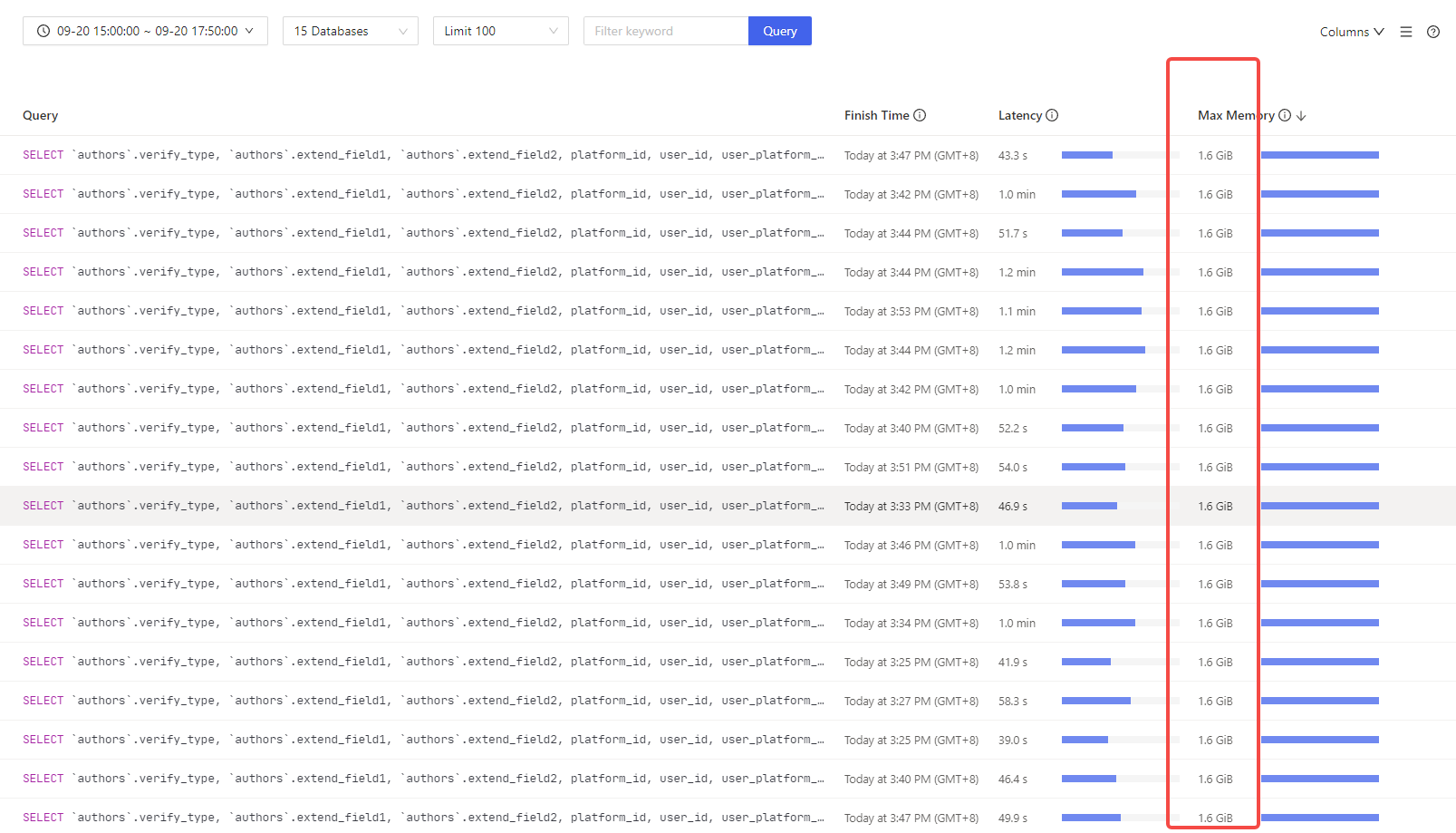
查了下,都是这个SQL,非常多查询占用了 1.6 GiB ,比我上面说的778M大
1 个赞
这个限制单条SQL占用内存我之前就改成了3G,我怕再改小会影响正常的业务~
一个SQL 1.6G ,多少内存也不够用啊
所以还是要优化SQL, 我上面的这个SQL语句,还有优化空间吗? 可以占用更小的内存?
1 个赞
1个SQL 1.6G,太多请求了,这个优先级就没啥意义了吧,全杀,上面还有个单点的redis也杀了~
有猫万事足
19
我现在想到是,可以尝试把这个sql转给tiflash执行一下看看。
占用内存高的主要原因是聚合发生在tidb上了,最好是能让这个聚合下推。放在tiflash上做,tidb直接收结果。