【 TiDB 使用环境】Poc
【 TiDB 版本】6.5.3
【复现路径】 tiflash 执行了scale-in --force 的操作
然后执行了 scale-out的操作发现 tiflasha的表不同步.
【遇到的问题:问题现象及影响】scale-in 的节点在tiup display 里面不显示, 但是pd-ctl store 里面显示为offline的状态
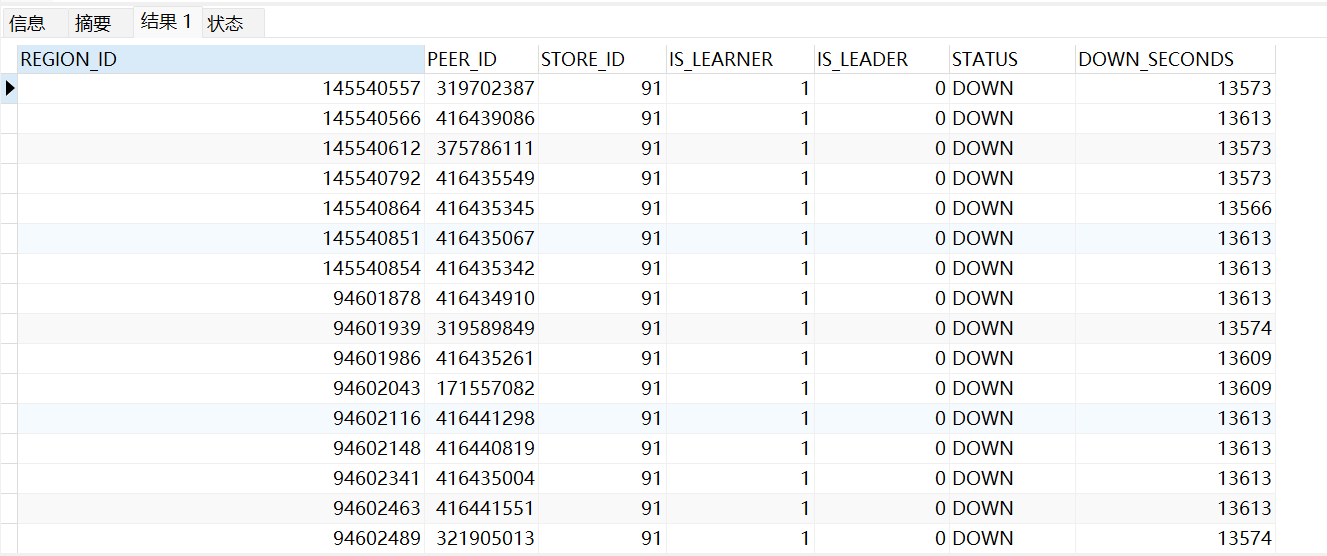
regions 里面很多处于down的状态
【资源配置】4* 96c鲲鹏 512G内存 nvme SSD
【附件:截图/日志/监控】
集群情况:
Starting component cluster: /root/.tiup/components/cluster/v1.12.4/tiup-cluster display erptidb
Cluster type: tidb
Cluster name: erptidb
Cluster version: v6.5.3
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://192.168.255.119:2379/dashboard
Grafana URL: http://192.168.255.121:3000
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
192.168.255.121:9093 alertmanager 192.168.255.121 9093/9094 linux/aarch64 Up /nvme00/tidb/alertmanager-9093 /deploy/tidb/alertmanager-9093
192.168.255.121:3000 grafana 192.168.255.121 3000 linux/aarch64 Up - /deploy/tidb/grafana-3000
192.168.255.119:2379 pd 192.168.255.119 2379/2380 linux/aarch64 Up|L|UI /nvme00/tidb/pd-2379 /deploy/tidb/pd-2379
192.168.255.121:2379 pd 192.168.255.121 2379/2380 linux/aarch64 Up /nvme00/tidb/pd-2379 /deploy/tidb/pd-2379
192.168.255.121:9090 prometheus 192.168.255.121 9090/12020 linux/aarch64 Up /nvme00/tidb/prometheus-9090 /deploy/tidb/prometheus-9090
192.168.255.119:4000 tidb 192.168.255.119 4000/10080 linux/aarch64 Up - /deploy/tidb/tidb-4000
192.168.255.120:4000 tidb 192.168.255.120 4000/10080 linux/aarch64 Up - /deploy/tidb-4000
192.168.255.120:4001 tidb 192.168.255.120 4001/10081 linux/aarch64 Up - /deploy/tidb-4001
192.168.255.121:4000 tidb 192.168.255.121 4000/10080 linux/aarch64 Up - /deploy/tidb/tidb-4000
192.168.255.121:9003 tiflash 192.168.255.121 9003/8125/3932/20172/20294/8236 linux/aarch64 Up /nvme02/tiflash/data/tiflash-9003 /deploy/tidb/tiflash-9003
192.168.255.119:20160 tikv 192.168.255.119 20160/20180 linux/aarch64 Up /nvme00/tidb/tikv/data/tikv-20160 /deploy/tidb/tikv-20160
192.168.255.119:20161 tikv 192.168.255.119 20161/20181 linux/aarch64 Up /nvme01/tidb/data/tikv-20161 /deploy/tidb/tikv-20161
192.168.255.119:50160 tikv 192.168.255.119 50160/50180 linux/aarch64 Up /nvme03/tidb/data/tikv-50160 /deploy/tidb/tikv-50160
192.168.255.120:20160 tikv 192.168.255.120 20160/20180 linux/aarch64 Up /nvme00/tidb/data/tikv-20160 /deploy/tidb/tikv-20160
192.168.255.120:20161 tikv 192.168.255.120 20161/20181 linux/aarch64 Up /nvme01/tidb/data/tikv-20161 /deploy/tidb/tikv-20161
192.168.255.120:40160 tikv 192.168.255.120 40160/40180 linux/aarch64 Up /nvme00/tidb/data/tikv-40161 /deploy/tidb/tikv-40160
192.168.255.120:40161 tikv 192.168.255.120 40161/40181 linux/aarch64 Up /nvme01/tidb/data/tikv-40162 /deploy/tidb/tikv-40161
192.168.255.121:20160 tikv 192.168.255.121 20160/20180 linux/aarch64 Up /nvme00/tidb/tikv/data/tikv-20160 /deploy/tidb/tikv-20160
192.168.255.121:20161 tikv 192.168.255.121 20161/20181 linux/aarch64 Up /nvme01/tidb/data/tikv-20161 /deploy/tidb/tikv-20161
192.168.255.122:30160 tikv 192.168.255.122 30160/30180 linux/aarch64 Up /nvme00/tidb/data/tikv-30161 /deploy/tidb/tikv-30160
192.168.255.122:30161 tikv 192.168.255.122 30161/30181 linux/aarch64 Up /nvme01/tidb/data/tikv-30162 /deploy/tidb/tikv-30161
192.168.255.122:30162 tikv 192.168.255.122 30162/30182 linux/aarch64 Up /nvme02/tidb/data/tikv-30162 /deploy/tidb/tikv-30162
192.168.255.122:40160 tikv 192.168.255.122 40160/40180 linux/aarch64 Up /nvme00/tidb/data/tikv-40161 /deploy/tidb/tikv-40160
192.168.255.122:40161 tikv 192.168.255.122 40161/40181 linux/aarch64 Up /nvme01/tidb/data/tikv-40162 /deploy/tidb/tikv-40161
192.168.255.122:40162 tikv 192.168.255.122 40162/40182 linux/aarch64 Up /nvme02/tidb/data/tikv-40162 /deploy/tidb/tikv-40162
-
pd-ctl的情况
{
“count”: 19,
“stores”: [
{
“store”: {
“id”: 91,
“address”: “192.168.255.119:3931”,
“labels”: [
{
“key”: “engine”,
“value”: “tiflash”
}
],
“version”: “v6.5.3”,
“peer_address”: “192.168.255.119:20171”,
“status_address”: “192.168.255.119:20293”,
“git_hash”: “e63e24991079fff1e5afe03e859f743cbb6cf4a7”,
“start_timestamp”: 1694990902,
“deploy_path”: “/deploy/tidb/tiflash-9001/bin/tiflash”,
“last_heartbeat”: 1695016186000543038,
“state_name”: “Offline”
},
“status”: {
“capacity”: “1.718TiB”,
“available”: “1.07TiB”,
“used_size”: “55.47GiB”,
“leader_count”: 0,
“leader_weight”: 1,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 5088,
“region_weight”: 1,
“region_score”: 1402721.0927894693,
“region_size”: 1152681,
“learner_count”: 5088,
“slow_score”: 1,
“start_ts”: “2023-09-18T06:48:22+08:00”,
“last_heartbeat_ts”: “2023-09-18T13:49:46.000543038+08:00”,
“uptime”: “7h1m24.000543038s”
}
},
{
“store”: {
“id”: 92,
“address”: “192.168.255.121:3931”,
“labels”: [
{
“key”: “engine”,
“value”: “tiflash”
}
],
“version”: “v6.5.3”,
“peer_address”: “192.168.255.121:20171”,
“status_address”: “192.168.255.121:20293”,
“git_hash”: “e63e24991079fff1e5afe03e859f743cbb6cf4a7”,
“start_timestamp”: 1694990955,
“deploy_path”: “/deploy/tidb/tiflash-9001/bin/tiflash”,
“last_heartbeat”: 1695016328659292069,
“state_name”: “Offline”
},
“status”: {
“capacity”: “1.718TiB”,
“available”: “821.3GiB”,
“used_size”: “50.54GiB”,
“leader_count”: 0,
“leader_weight”: 1,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 4361,
“region_weight”: 1,
“region_score”: 1402379.9771483315,
“region_size”: 1111245,
“learner_count”: 4361,
“slow_score”: 1,
“start_ts”: “2023-09-18T06:49:15+08:00”,
“last_heartbeat_ts”: “2023-09-18T13:52:08.659292069+08:00”,
“uptime”: “7h2m53.659292069s”
} -
tikv_regions_peers 的情况
tiflash_error.log (1.9 KB)
tiflash_stderr.log (574 字节)