【 TiDB 使用环境】生产环境 /测试/ Poc进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面 BR备份报错cannot pass gc safe point check
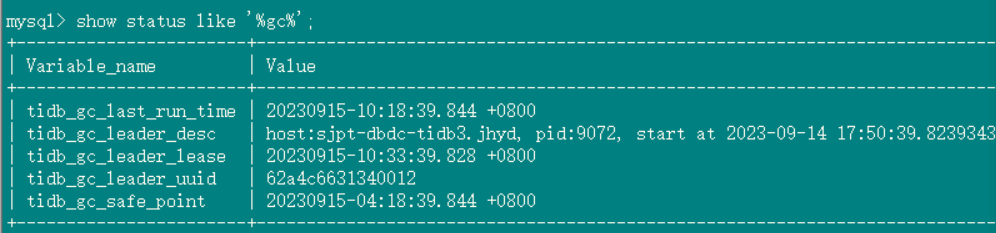
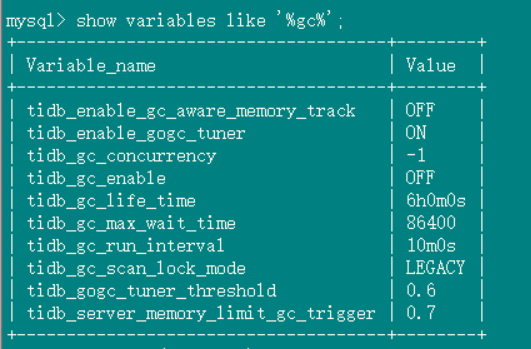
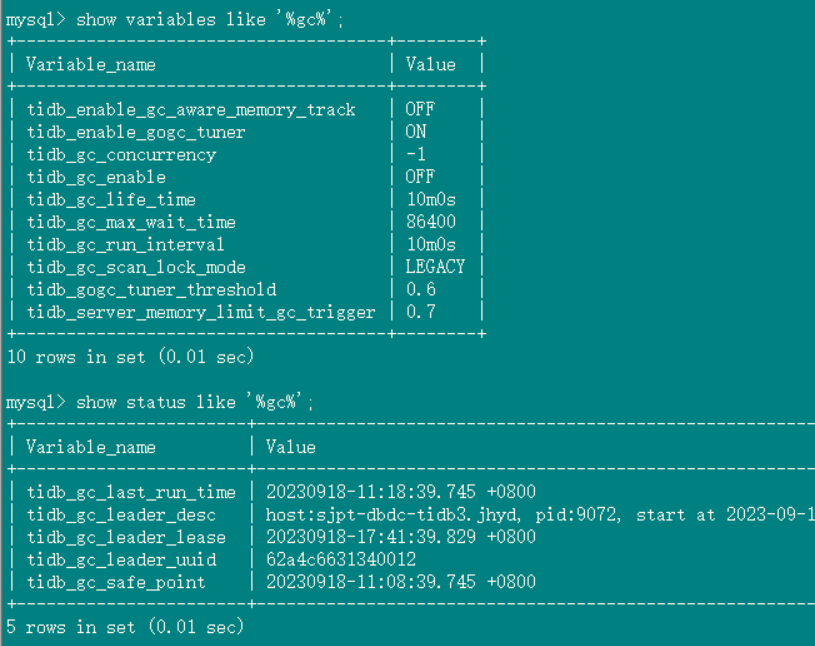
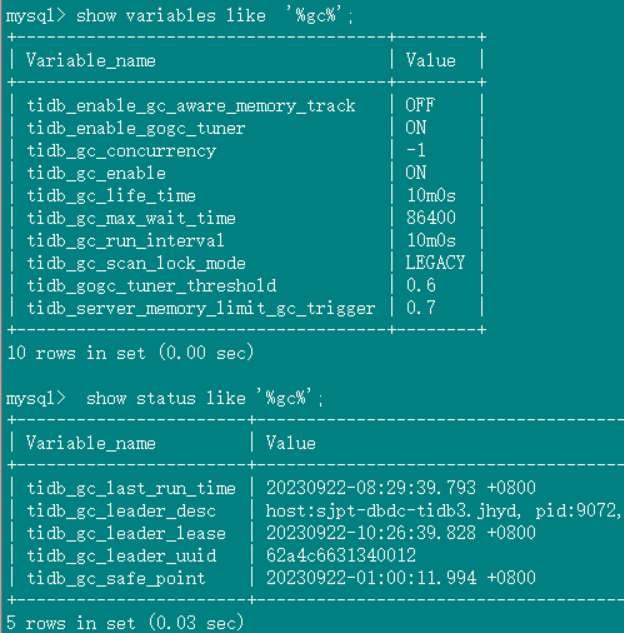
gc 设置:
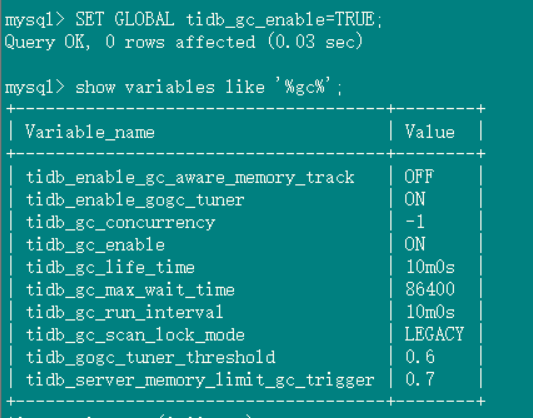
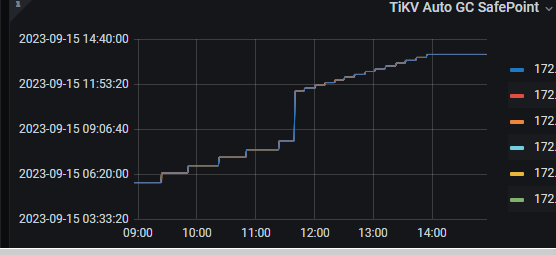
2、tidb_gc_life_time=10m0s , tidb_gc_run_interval =10m0s 打开gc,grafana上面的safepoint和tidb里面查到的很快就一致了
数据库中gc status:
gc 设置:
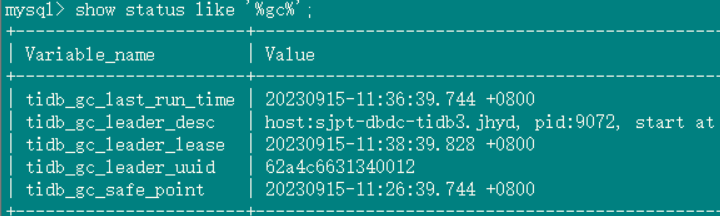
3、关闭gc, grafana上面的safepoint和tidb里面查到的一致,并且safepoint确实停止了
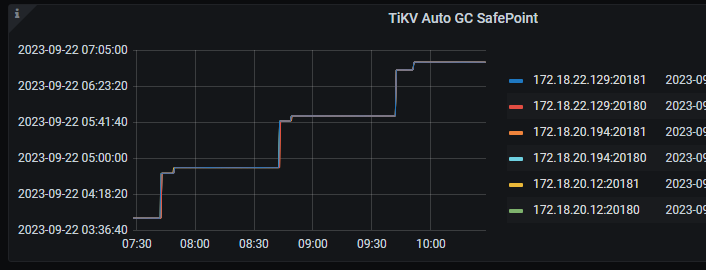
三个阶段的grafana gc safepoint
你的意思7.1.1上关闭tidb_gc_enable参数之后,tidb客户端查看safepoint已经不推进了,但是grafana上还在推进?
对的,tidb里面看起来是和配置的6小时相对的,但是grafana的一直在推进
你可以复现之前的关闭gc 然后granafa还有safepoint推进的场景吗?http://kvip:20180/metrics 这个监控数据中有个tikv_gcworker_autogc_safe_point ,看下这个时间是否在推进,如果tidb_gc_safe_point 不变而监控中的tikv_gcworker_autogc_safe_point 持续推进,那这个就是个bug。
但是我测试了一下,并没有复现,关闭tidb_gc_enable之后,两边savapoint都不推进了啊,
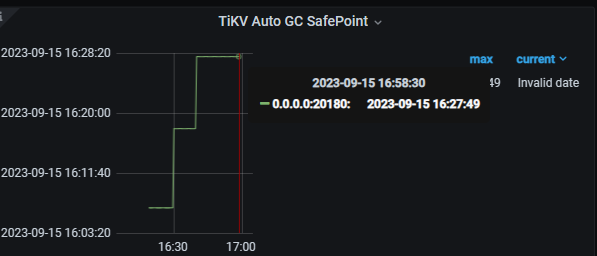
现在确实无法复现了,但是你看我上面grafana的截图,确实有这个情况,还有我上一个帖子,我是从6.1.0有这个问题升级过来的,早上又发现这个问题,最后修改了tidb_gc_life_time之后回归正常
复现了,
12:00之前就关闭了gc
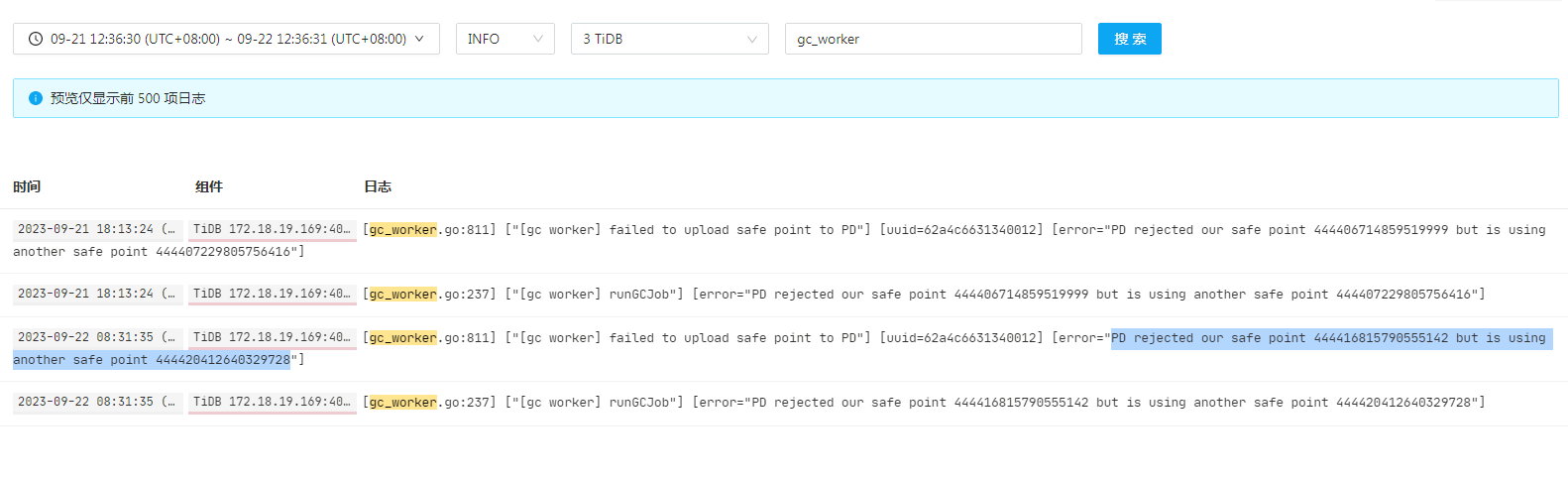
[2023/09/18 14:17:49.813 +08:00]执行的BR,感觉BR会启动gc,而且这个启动不与tidb同步,br过程又因为safepoint终止了
br命令:tiup br backup full --pd “172.18.19.xxx:2379” --storage “s3://xx-bigdata-temp?access-key=xx-bigdata-temp&secret-access-key=xxxx&endpoint=
http://xxxx:8333 &force-path-style=true” --ratelimit 128
不知道其他的小伙伴能否复现,如果你是 6.1 的时候就有这个问题,那么有可能是因为这个问题影响的 7.1.1 也会!
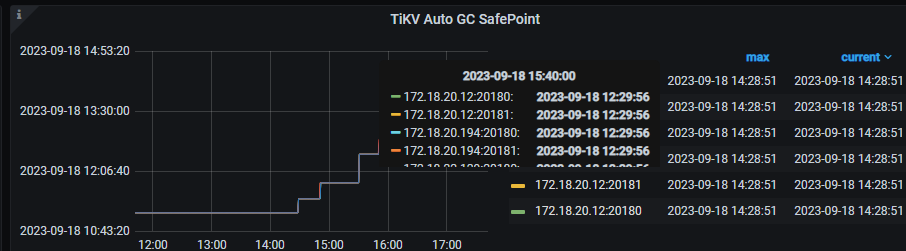
两个safepoint会持续不一致,打开gc,持续观察两个safepoint都在推进但是持续不一致,重新设置tidb_gc_life_time为其他值,再改回来,继续观察发现grafana的频率也是10分钟了,而且数值也和tidb的一致,但是时间上有延迟(grafana的稍慢)
Aric
2023 年9 月 21 日 08:48
11
麻烦测试环境测一个稳定复现的 最小复现步骤, 谢谢?
tidb查的gc safepoint不推进了,cdc也卡在tidb相同的gc point,grafana的还在推进,可以怎么解决一下
我现在只要关闭gc,然后使用br备份超过3个小时就能复现(grafana的gc自己就开始推进了,tidb的保持不变,备份失败) tiup br backup full --pd “172.18.19.xxx:2379” --storage “s3://xx-bigdata-temp?access-key=xx-bigdata-temp&secret-access-key=xxxx&endpoint=http://xxxx:8333 &force-path-style=true” --ratelimit 128 --gcttl 54000 (–gcttl 54000 这个加不加效果一样)
前天晚上相同的情况,昨天早上gc就恢复正常了(两个一致),昨天我又分开备份(整体备份总是失败)了一下,结果今早没有恢复,卡在了1点钟
复现路径把执行计划贴一下
别人需要做什么操作,才会出现这个问题,
整体的最小复现路径都贴一下,不用图,用文字把具体的操作写一下。
关闭gc,然后执行br的备份,3个小时20分钟左右之后就会因为safepoint的异常(grafana的gc safepoint刷新了)退出备份
[gc worker] failed to upload safe point to PD"] [uuid=62a4c6631340012] [error="PD rejected our safe point 444416815790555142 but is using another safe point 444420412640329728
找到原因了,是被ticdc的safepoint 卡住了
1 个赞