我再跟一跟这个问题看看
leader转移了。
所以你请求的store对应的region变成follower。而这个raft组里面的leader在另一个store上。
假如开了follow 读 是不是就没有这个报错了
好想法。
https://github.com/tikv/client-java/pull/96
java client好像是实现了 follower read.可以在 TiConfiguration.java 里面设置。
这确实是个值得尝试的点。
1 个赞
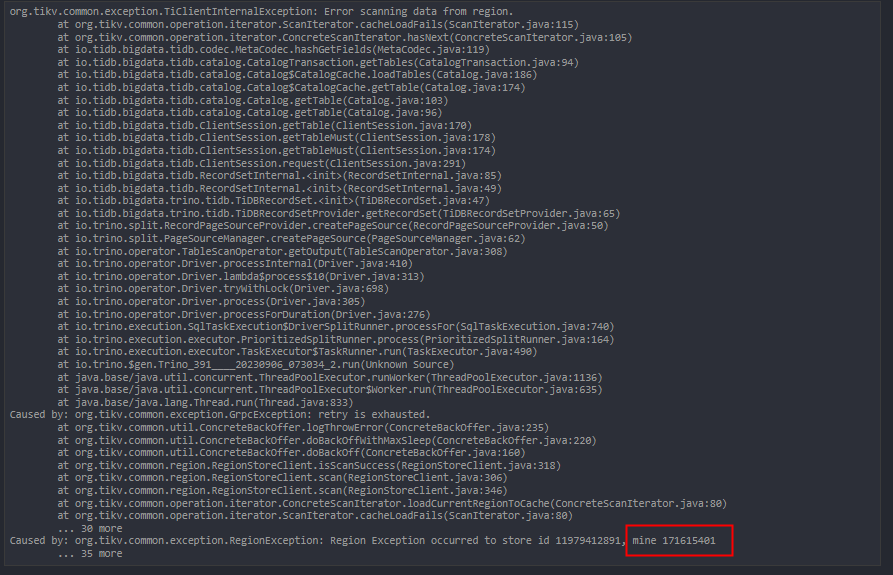
还有一个问题,根据日志,我查询的这张表store_id本应该为11979412891,但是我实际请求的store_id为171615401,但是171615401与我查询的这张表并没有什么联系。
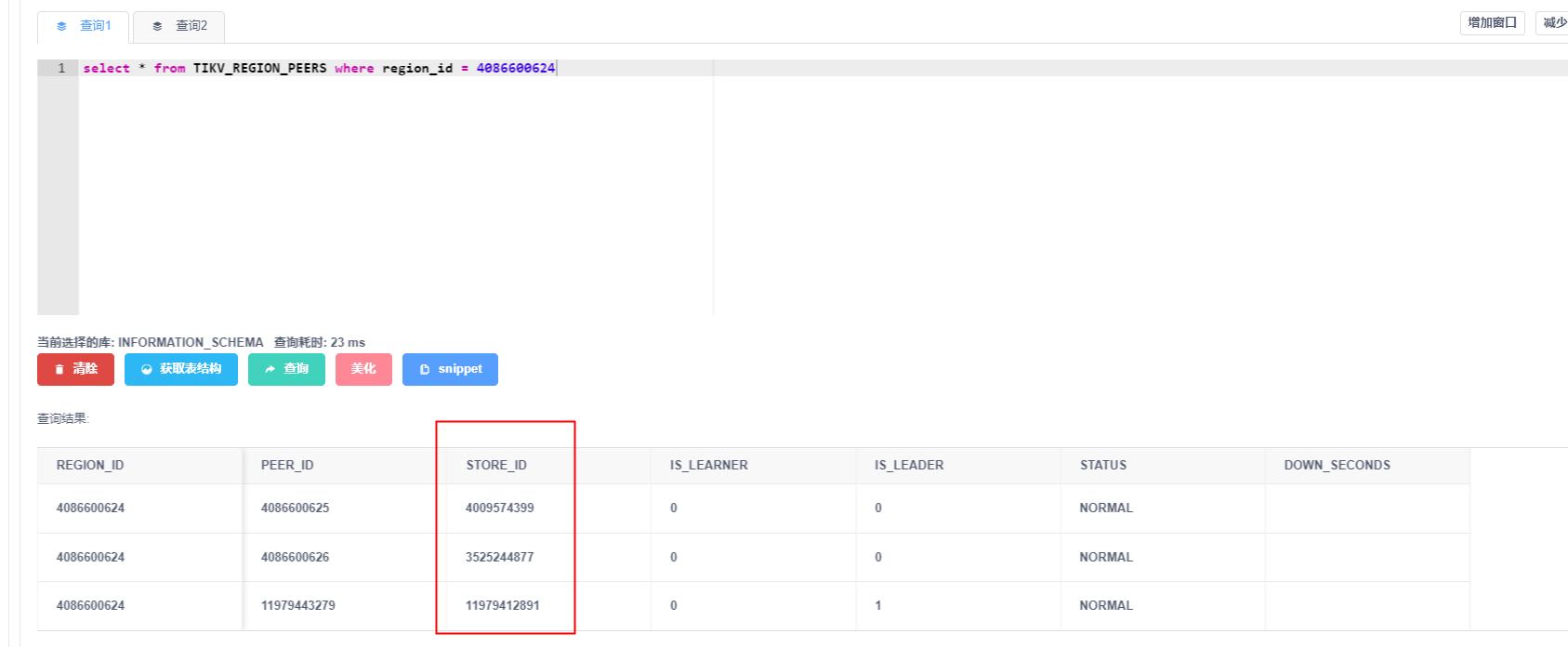
我查询的这张表region分布的store_id没有包含171615401
my_store_id是当前tikv的store_id,这里有一个不能理解的地方,为什么会在171615401这个tikv执行查询,就算发生了leader切换,那么也应该在peer列表中选择一个tikv节点执行吧,但是实际上171615401根本不存在于peer列表中
应该是 java 获取到了旧的信息了
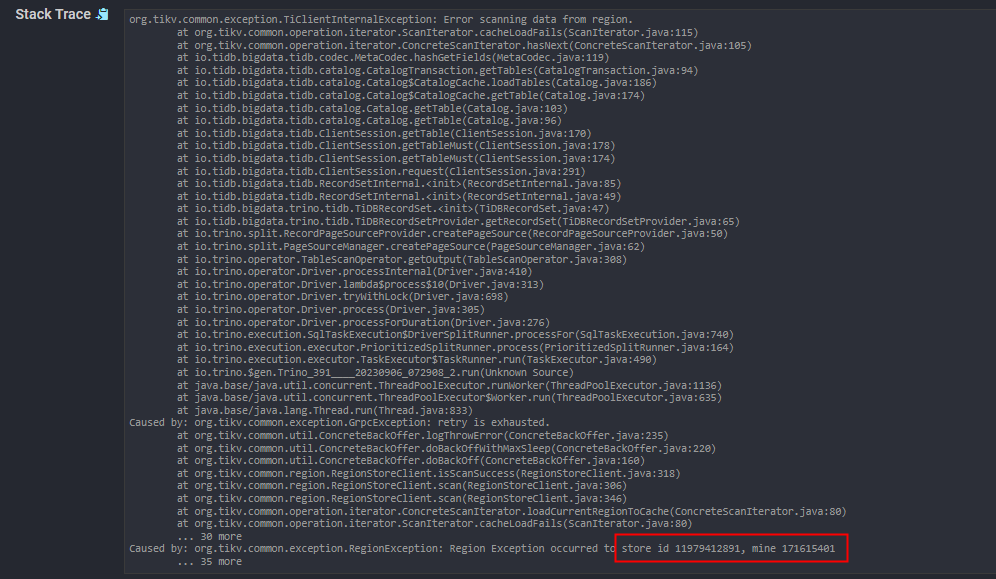
我重新确认了一下最新的日志
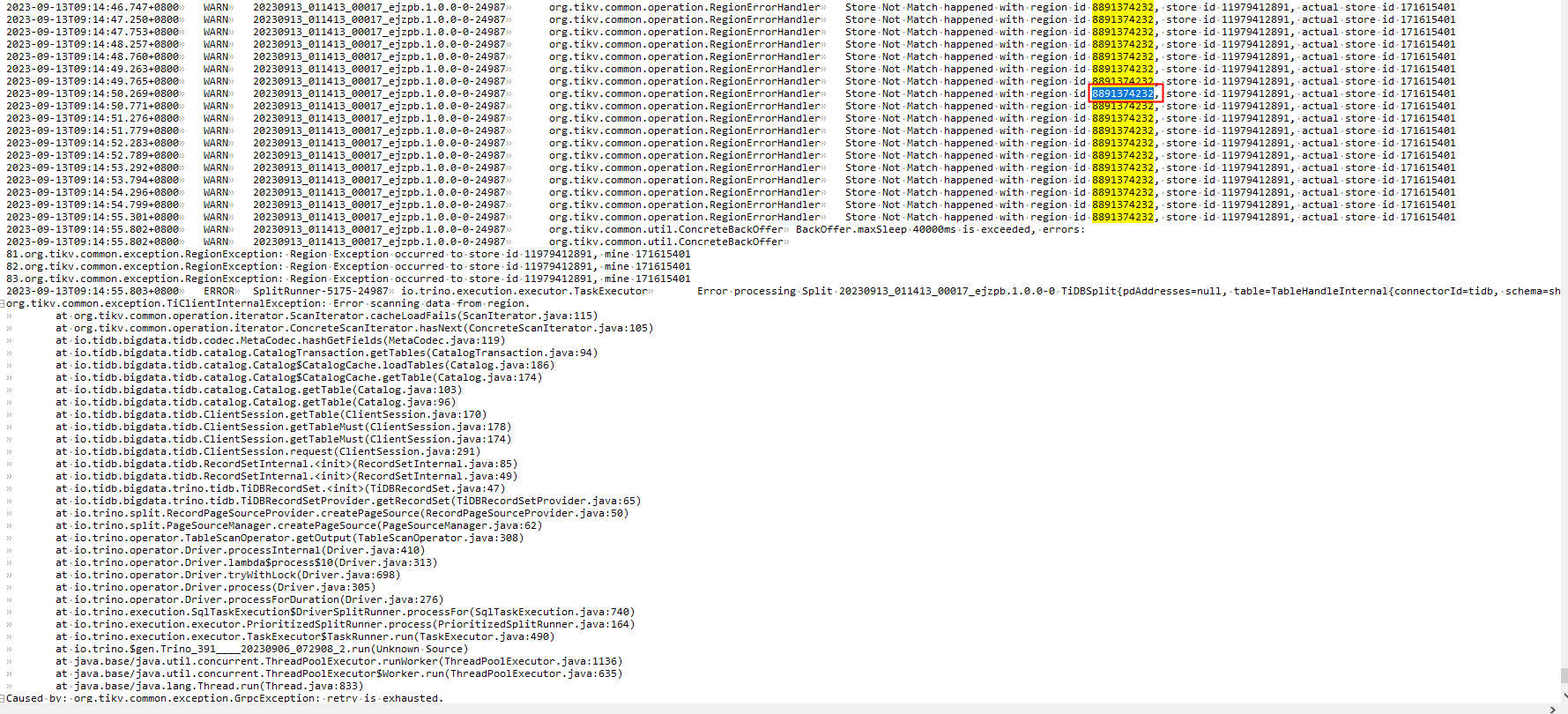
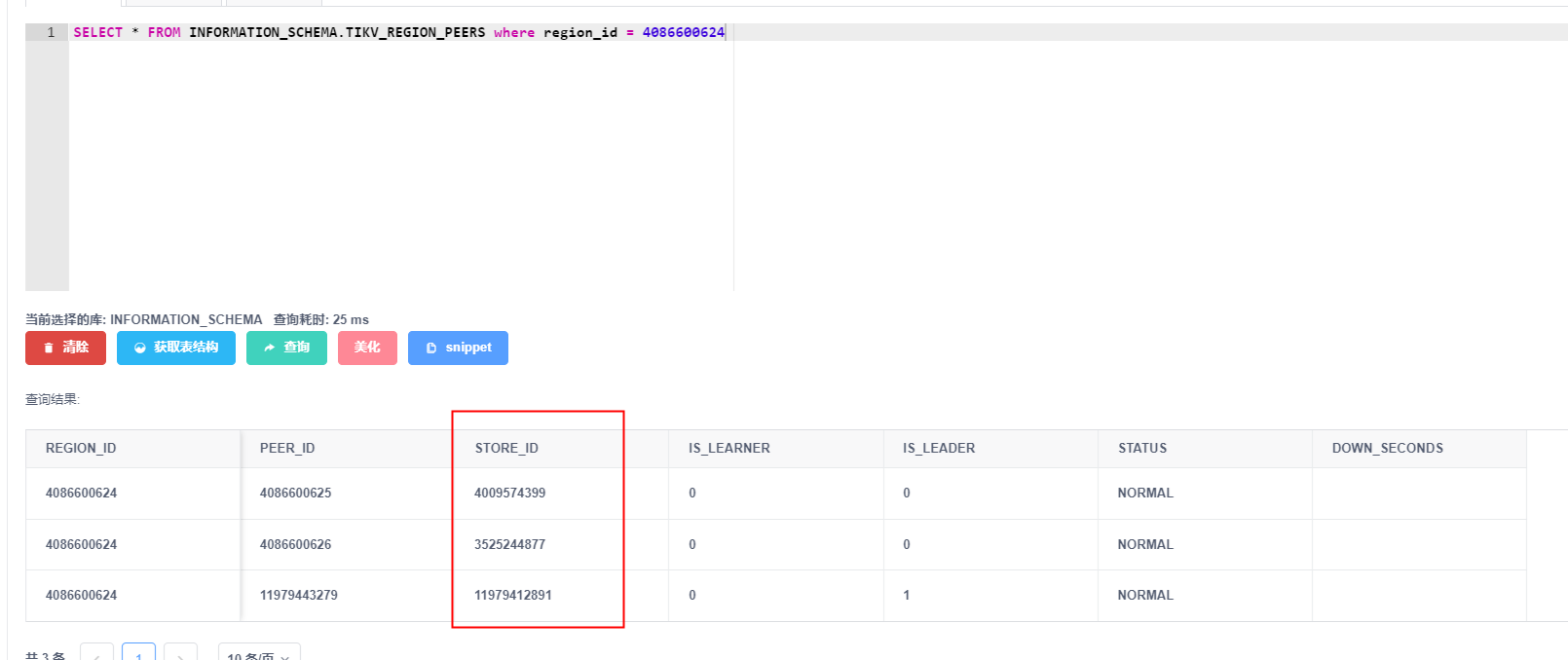
我查询的是a表,但是请求的region_id跟a表一点关系都没有,下图是a表的region_id

我又查了一下请求的region_id信息,发现这个region_id的table_id为空
集群搞过reload 或者重启么?
PD 要不也重启看看?
生产环境,近期是没有重启过的
要不先把PD重启了,看看
tidb 也重启吧 ![]()
昨天看了一整天,代码都翻遍了。目前的推断是pd给我返回的region的store_id有问题
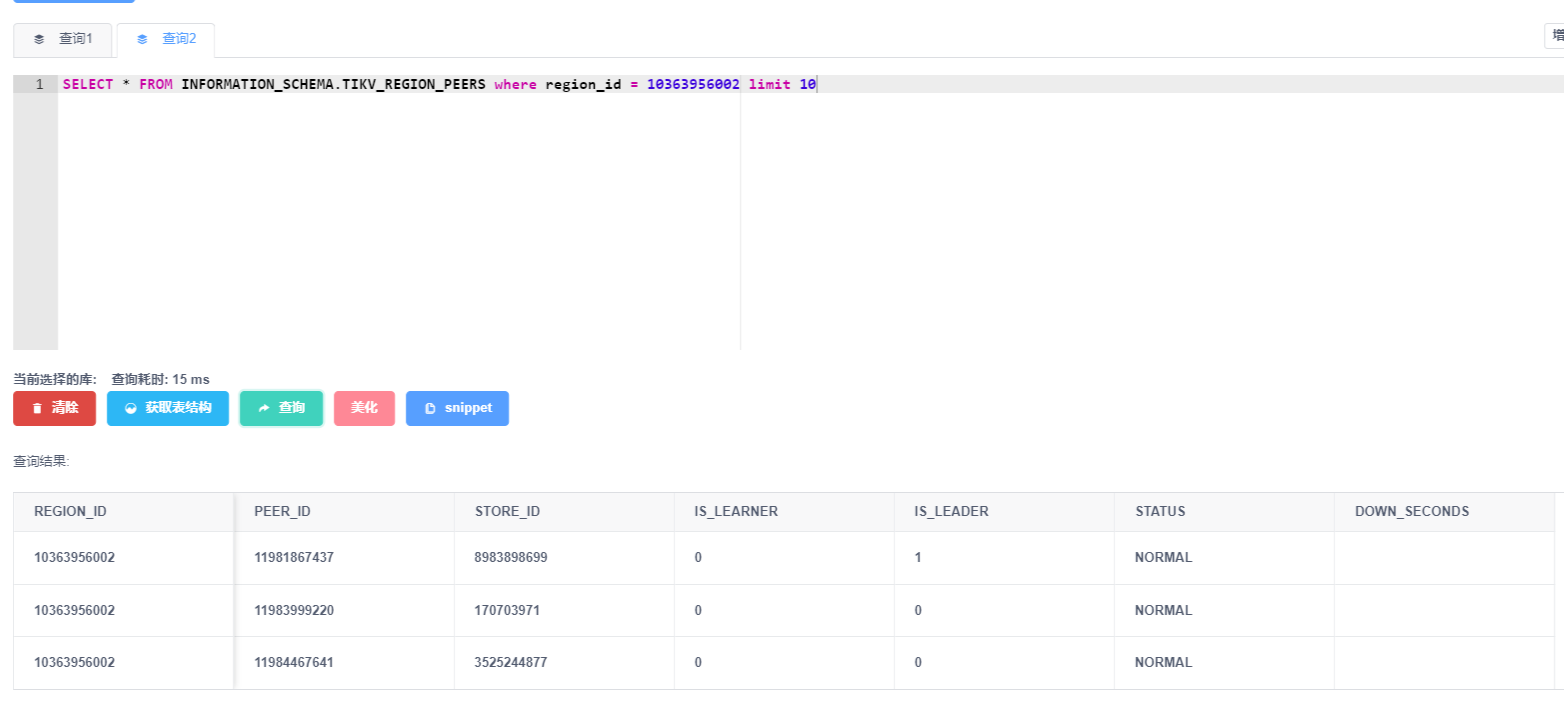
10363956002这个region的数据查询请求被分发到了一个错误的store_id上执行。
正常情况下region_id对应的store_id是会发生改变的吗?
正常应该不变的,region leader 对应 store id region follower 对应 store id
在查询,写入使用当中,交互的是 leader ,要是 leader 在变,store id 也会变
region 96MB -144 MB 分裂,合并成新的,那store ID 也会变
