LBX流鼻血
(Hacker N0e Er Xxz)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1.0
【遇到的问题:问题现象及影响】
查询表报错
/* SQL错误(1105):no available peers, region: {id:4894111 start_key:“t\200\000\000\000\000\000\001\r_r\340\200\000\000\005@\n\266” end_key:“t\200\000\000\000\000\000\001\r_r\340\200\000\000\t1|.” region_epoch:<conf_ver:673 version:2324 > peers:<id:14679021 store_id:8 > peers:<id:15904328 store_id:25 > peers:<id:28393082 store_id:7 > } */
出现的类这类报错,其实报错中的store_id:8和store_id:25之前都已经缩容掉了,但是这里还是认的旧的store_id
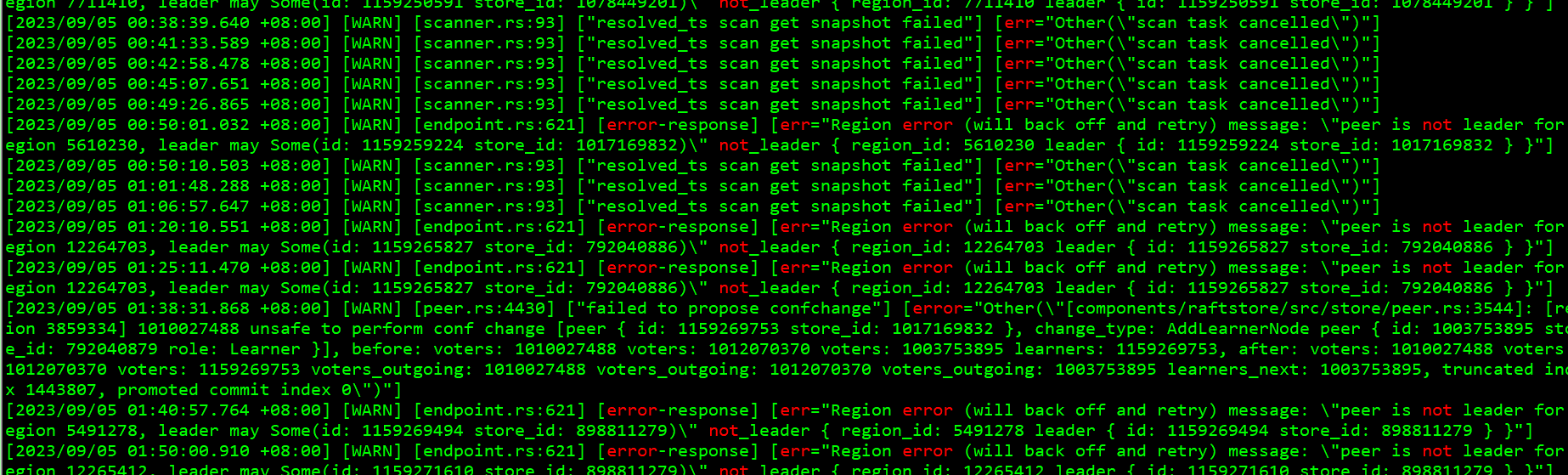
日志里是这类报错
请问大神们这类有办法修复吗?已经扩容新节点缩容了旧节点了。
redgame
(Ti D Ber Pa Amoi Ul)
2
在查询所需的数据时无法找到可用的副本或分区,尝试清除 TiDB 缓存
pdctl看下4894111这个region的peer都是什么状态,分配在哪些store上
h5n1
(H5n1)
4
curl -X DELETE http://${HostIP}:2379/pd/api/v1/admin/cache/region/{region_id}
把报错的region 从PD清理下
1 个赞
LBX流鼻血
(Hacker N0e Er Xxz)
5
清理了之后
查询原来会报错的表,出现的是
ERROR 9001 (HY000): PD server timeout
h5n1
(H5n1)
7
region信息没上报,看你之前发的帖子贴了个命令 从tikv侧看region信息
LBX流鼻血
(Hacker N0e Er Xxz)
9
从KV侧看region信息,会报错
DebugClient::region_info: RpcFailure: 14-UNAVAILABLE failed to connect to all addresses
能否使用
方法一:
SET @@GLOBAL.tidb_config = ‘{“global”:{“force_sync_diff”: true}}’;
进行刷新元数据
或者
方法二:
pd-ctl -u <pd_address> store delete <已经不存在的store_id>
h5n1
(H5n1)
10
这个参数不了解是做什么的。
这个命令是把store下线,先进入offline然后tombstone,不是理解上的删除。 这个tikv现在是什么状态(tiup cluster display、pd-ctl store结果),之前做过什么操作,缩容?
LBX流鼻血
(Hacker N0e Er Xxz)
11
是的
1、最早之前是mydumper出现报错
备份报错 TiKV server timeout和context deadline exceeded - #7,来自 大飞哥Boil.
2、由于是全表扫,单表都去到几百G,一共3台主机,一个主机放了8个KV,共计3x24个KV,全表mydumper扫出现了多次OOM。就出现了以下报错
查表出现"ERROR 9005 (HY000): Region is unavailable",集群状态又没有大问题 - #2,来自 像风一样的男子.
3、然后就开始扩容了3机器每个机器6kv节点=18个kv节点,扩容完成后,对之前的8kv3机器共计24kv节点进行缩容,缩容后,就出现了这个帖子标题的报错,找的store_id是之前已经缩容掉的store_id。
h5n1
(H5n1)
12
你的相同主机上的tikv 有设置相同的lable吗? 缩容的store_id 在pd-ctl 里还能看到吗 ? 缩容用的什么命令 ?
有重启过pd 试过没
LBX流鼻血
(Hacker N0e Er Xxz)
13
1/你的相同主机上的tikv 有设置相同的lable吗? 缩容的store_id 在pd-ctl 里还能看到吗 ? 缩容用的什么命令 ?
都有设置相同的lable,所有机器的dc都为dc1,其他根据IP的尾数不通,设置不同的host、rack、zone。只要在一台物理机中的kv的lable都是一样。
例如:
10.1.1.1
dc: d1
host: “01”
rack: r1
zone: z1
10.1.1.2
dc: d1
host: “02”
rack: r2
zone: z2
缩容的store_id 在pd-ctl可以看到
{
“store”: {
“id”: 7,
“address”: “xxxxxxxx”,
“labels”: [
{
“key”: “zone”,
“value”: “z2”
},
{
“key”: “rack”,
“value”: “r2”
},
{
“key”: “host”,
“value”: “05”
},
{
“key”: “dc”,
“value”: “d1”
}
],
“version”: “6.1.0”,
“status_address”: “10.xx.xx.xx:20181”,
“git_hash”: “080d086832ae5ce2495352dccaf8df5d40f30687”,
“start_timestamp”: 1692847133,
“deploy_path”: “/tidata/hdap/ti-kv-20171/bin”,
“last_heartbeat”: 1692858453101795695,
“node_state”: 3,
“state_name”: “Tombstone”
},
“status”: {
“capacity”: “0B”,
“available”: “0B”,
“used_size”: “0B”,
“leader_count”: 0,
“leader_weight”: 0,
“leader_score”: 0,
“leader_size”: 0,
“region_count”: 0,
“region_weight”: 0,
“region_score”: 0,
“region_size”: 0,
“slow_score”: 0,
“start_ts”: “2023-08-24T11:18:53+08:00”,
“last_heartbeat_ts”: “2023-08-24T14:27:33.101795695+08:00”,
“uptime”: “3h8m40.101795695s”
缩容用tiup cluster scale-in tidb-hdap --node 10.1.1.2:20171
2/有重启过pd多次
h5n1
(H5n1)
14
单看这个是缩容过程没处理完,不知道其他几个是什么状态,执行tiup cluster prune xx、 pd-ctl -u http://pd_ip:2379 store remove-tombstone 把这种状态的清理了。
LBX流鼻血
(Hacker N0e Er Xxz)
15
会出现
Failed to remove tombstone store [500] “failed stores: 21, 23, 16, 19, 24, 5, 17, 20, 14, 15, 18, 22, 4, 25, 7, 8, 26”
h5n1
(H5n1)
16
试试unsafe recover把这些能处理不
tikv-ctl --db /xxxxx/data/db unsafe-recover remove-fail-stores -s 1, 23, 16, 19, 24, 5, 17, 20, 14, 15, 18, 22, 4, 25, 7, 8, 26 --all-regions
这个命令要求关闭所有正常的tikv,然后挨个再每个tikv目录下执行。
如果不允许关tikv 6.1版本有个online unsafe recover
https://docs.pingcap.com/zh/tidb/stable/online-unsafe-recovery#第-1-步指定无法恢复的节点
LBX流鼻血
(Hacker N0e Er Xxz)
18
缩容是正常的,只是执行的时间比较长,期间部分KV会出现重启,但整体还是比较顺利的。
LBX流鼻血
(Hacker N0e Er Xxz)
20
大佬,这种扩缩下PD节点能不能刷新到数据源对应的?修复这些空洞