【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.4
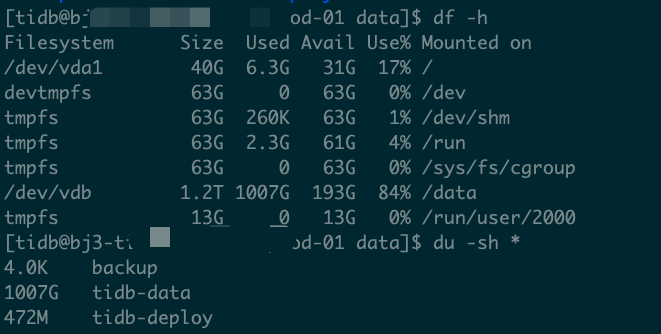
【复现路径】集群promtheus 机器从3月份到现在磁盘从200G 扩到1200G,磁盘空间增长特别快。
【遇到的问题:问题现象及影响】
磁盘增长越来越快。
【资源配置】
启动脚步
exec bin/prometheus/prometheus \
--config.file="/data/tidb-deploy/prometheus-9090/conf/prometheus.yml" \
--web.listen-address=":9090" \
--web.external-url="http://xxxxxx:9090/" \
--web.enable-admin-api \
--log.level="info" \
--storage.tsdb.path="/data/tidb-data/prometheus-9090" \
--storage.tsdb.retention="30d" \
--storage.tsdb.max-block-duration=2h \
--storage.tsdb.min-block-duration=2h
【附件:截图/日志/监控】
ps:
- 期间集群磁盘扩容过,增长情况不明显。
- 已经确定机器只有promtheus tsdb占用磁盘最多。
问题:
如何降低promtheus db存储空间
zhanggame1
(Ti D Ber G I13ecx U)
2
调整监控数据的保存时间。数据不要了也可以把监控组件缩容再扩容
–storage.tsdb.retention 设置小一点 或者直接指定存储大小 --storage.tsdb.retention.size :要保留的存储的大小
–storage.tsdb.retention再调小点?想保留的重要时间数据可以导出个快照?
–storage.tsdb.retention=“30d” 保存一个月的可以改成15d 或7d
#可以为块存储的最大字节数。 支持的单位:KB,MB,GB,TB,PB。
–storage.tsdb.retention.size=STORAGE.TSDB.RETENTION.SIZE
或者就是固定的限制大小
你这个日志大的有点异常了,我这保存30天的日志才100g不到,检查下你的prometheus 是不是有异常
你这是多大的集群规模啊,prometheus日志能这么大?
DBRE
12
prometheus配置文件在job tikv处增加如下内容,去掉一些metric的采集,这样可以减少存储,不过每次拓扑变更会覆盖这个配置,需要重新改下,再restart prometheus
metric_relabel_configs:
- source_labels: [name]
separator: ;
regex: tikv_thread_nonvoluntary_context_switches|tikv_thread_voluntary_context_switches|tikv_threads_io_bytes_total
action: drop
- source_labels: [name,name]
separator: ;
regex: tikv_thread_cpu_seconds_total;(tokio|rocksdb).+
action: drop
总数量40+;不太大吧。tidb官方同学说,支持了300TB的集群
tidb默认监控项很多的,集群规模肯定支持,但是监控日志量必须保存30天肯定也很大。
大佬,我也感觉tidb默认的监控项太多了,能清理哪些呢
