【 TiDB 使用环境】生产环境
【 TiDB 版本】V7.1.0
【遇到的问题:问题现象及影响】 在没有读请求场景下,通过DTS做全量数据迁移过程发现,TIKV的内存持续增长【登录到TIKV服务器上TOP查询】,通过修改storage.block-cache.capacity配置降低了一些内存,但是仍未解决,如何定位这些内存是哪里占用的?
在TiDB Dashboard 实例性能分析 - 手动分析页面里面选heap.
* Heap:TiDB、PD 实例上各个内部函数的内存占用开销情况,
https://docs.pingcap.com/zh/tidb/stable/dashboard-profiling
有类似下面这样的图:
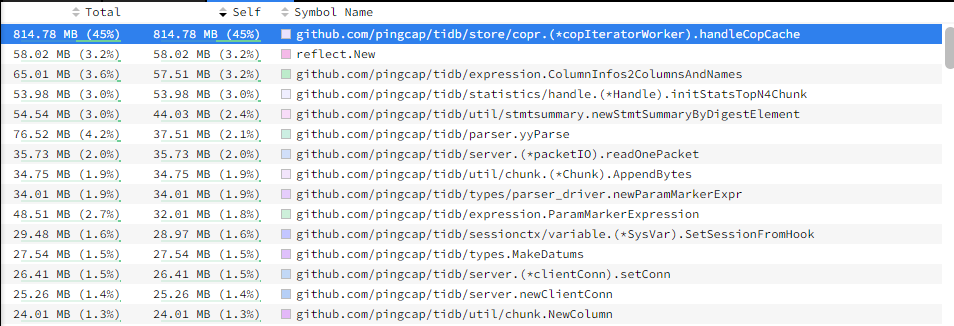
如果是每个慢sql的内存占用,
https://docs.pingcap.com/zh/tidb/stable/information-schema-slow-query#cluster_slow_query-table
和内存使用相关的字段:
* `Mem_max`:表示执行期间 TiDB 使用的最大内存空间,单位为 byte。
tikv-details → server → memory trace,可以定位是哪些组件消耗的内存
这里的信息不全,检查过了
那好像目前没什么好办法了,tikv 优先做 top sql 专注 cpu
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面 看下你的资源配置情况?
tikv 内存是常驻的,理论上不做配置,单机单实例的话 会使用服务器 80% 内存,然后就不回涨了。
在全量灌入数据期间TIKV OOM多次了,我看内存持续涨,没有读请求哦
tikv 一般不会 oom,要么你是多实例部署,没有做内存配置。要么是内存配置不合理。要么是 tikvbug,内存溢出了。
1 个赞
我的集群配置很差(4c8G),出现过这个情况。几个tikv轮流挂,最后7.1上了资源管控,就平稳运行了。
资源管控是什么呢
为了安全起见,我们关闭了dashboard的访问 ![]()
https://docs.pingcap.com/zh/tidb/stable/tidb-resource-control#使用资源管控-resource-control-实现资源隔离
7.1的新特性。
一些新的特性不是很敢用,哈哈
用起来不复杂。我不确定你是配置问题还是混合部署了。
我的问题很确定是配置不足,文档的推荐配置上根本就没有我这么低的一档的配置。不用这个特性根本没法用。这个是记录,有兴趣可以看看。
好的,辛苦,我在定位一下
storage.block-cache.strict-capacity-limit这个参数有详细的解释么? 我在官方文档上没找到,是否可以通过这个参数加上storage.block-cache.capacity参数就能严格限制tikv内存的使用了呢?
https://github.com/search?q=repo%3Atikv%2Ftikv%20strict-capacity-limit&type=code
不太乐观,但可以在测试环境尝试一下,这个参数就是一个true/false的设置。好像是直接传进rocksdb的设置里面去了
然后,就在rocksdb,找到这个issue。
https://github.com/facebook/rocksdb/issues/8670
大意是,如果设置了这个参数,缓存满了,插不进去了,可能会立刻报错,而不是装作无事发生,正常返回。
这个issue还是open的。 ![]()
既然rocksdb是明确会报错了,就不清楚tikv是否对这个情况做了什么处理。
storage.block-cache.shared这个配置我show config的时候返回的是null,这个值代表true还是false呢 ![]()
if self.shared == Some(false) {
warn!("storage.block-cache.shared is deprecated, cache is always shared.");
}
![]() 有点不讲武德。
有点不讲武德。