【 TiDB 使用环境】生产环境
【 TiDB 版本】6.1
【遇到的问题:问题现象及影响】
现象:现在很多大表做查询,都会出现"ERROR 9005 (HY000): Region is unavailable"
导致无法备份,无法查询表。

架构:
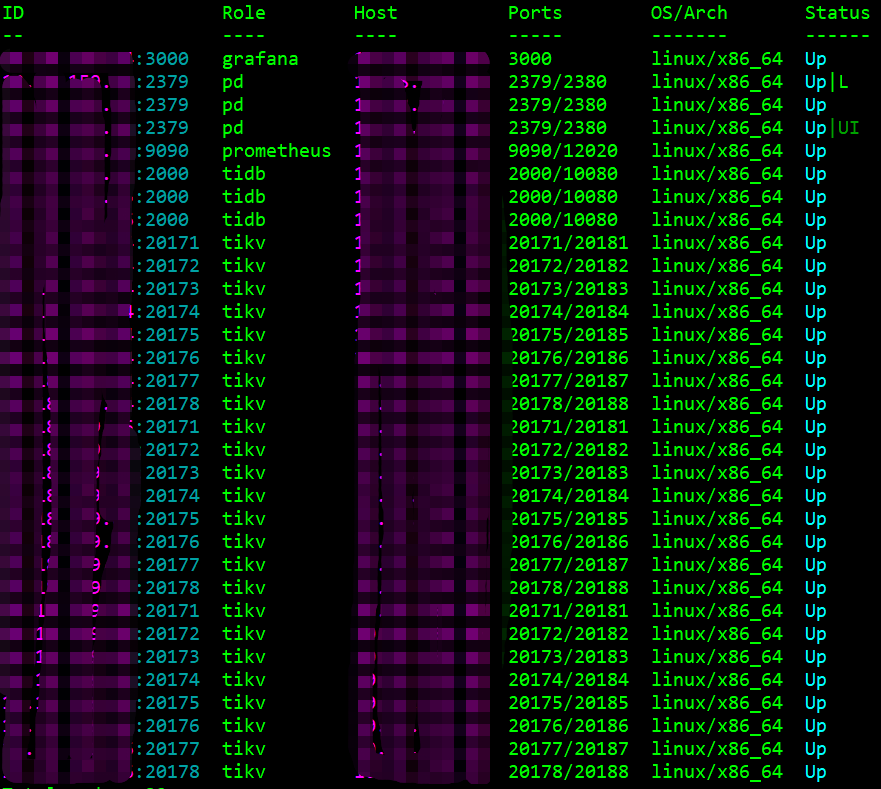
背景:
曾经做了一次br,结果内存不够用,两个KV节点挂掉了,最后用三板斧,手动分配region
+online unsafe recover才把故障节点彻底下线了。
KV日志大量报错:
[WARN] [peer.rs:5618] [“leader missing longer than abnormal_leader_missing_duration”] [expect=10m] [peer_id=33046701] [region_id=33046699]
[2023/08/29 13:22:03.814 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 7 pending peers include 6 ready, 0 entries, 0 messages and 0 snapshots”] [takes=2150]
[2023/08/29 13:22:04.657 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:04.980 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:05.044 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 2 pending peers include 2 ready, 0 entries, 0 messages and 0 snapshots”] [takes=1094]
[2023/08/29 13:22:06.561 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 32 pending peers include 30 ready, 0 entries, 0 messages and 0 snapshots”] [takes=1513]
[2023/08/29 13:22:06.678 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:06.901 +08:00] [ERROR] [util.rs:447] [“request failed, retry”] [err_code=KV:PD:Unknown] [err=“Other("[components/pd_client/src/client.rs:897]: get timestamp timeout")”]
[2023/08/29 13:22:06.916 +08:00] [WARN] [store.rs:986] [“[store 130077642] handle 11 pending peers include 10 ready, 0 entries, 0 messages and 0 snapshots”] [takes=3061]
[2023/08/29 13:25:25.437 +08:00] [WARN] [endpoint.rs:621] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 7709241, leader may Some(id: 7709242 store_id: 16)" not_leader { region_id: 7709241 leader { id: 7709242 store_id: 16 } }”]
[2023/08/29 13:25:25.439 +08:00] [WARN] [endpoint.rs:621] [error-response] [err=“Region error (will back off and retry) message: "peer is not leader for region 7709241, leader may Some(id: 7709242 store_id: 16)" not_leader { region_id: 7709241 leader { id: 7709242 store_id: 16 } }”]

个人思路,准备再弄几台物理机,将节点全部扩容上去,再把现有的节点下线掉,不知道该方案是否可行,大佬们帮忙看看有没有更好更简单的方式。