【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
我们有个表要存60亿数据,在测试中发现数据增加到三十亿之后 插入速度慢了一半,请问是什么原因呢?如何调查和解决
测下硬盘iops前后是不是有变化
变慢的时间点开始,集群监控有没有什么变化,热点问题如何?
1.看看数据是否分布不均衡导致写热点
2.是否有锁冲突
是采用什么方式插入?一次插入多少条记录?
一两个
可以参考下这个读写性能慢排查流程
1 个赞
dashboard看下有没有写热点吧
是不是写热点,主键是自增的还是随机分配的,看下底层region分布均匀不
region 均匀,随机主键。但是有一个日期索引,不确定是否是它的影响呢
索引可能也有一些影响,表分区了吗
没有分区,分区能带来什么好处吗?
表分区的好处
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到不同磁盘以平衡I/O,改善整个系统性能。
1 个赞
可以参考排查, 【SOP】最佳实践之 TiDB 业务写变慢分析
3 个赞
越大越慢是常常态,可以分个区
分区你可以理解为一场表物理上实际上是多张表,每个分区都一张表。
一般来说,你这个数量级的大表都应该分区的。最显而易见的好处是删除数据方便,delete很慢,drop partition很快,还能释放磁盘空间
一些可能的原因:
- 索引更新: 当表中有索引(包括主键索引和其他索引)时,每次插入操作都需要更新索引。随着数据量的增加,索引的维护成本也会增加,从而导致插入操作变慢。这可能会在大量插入操作后影响性能。
- 锁竞争: 在并发环境中,多个插入操作可能会竞争相同的资源,如行级锁、表级锁等。随着并发插入的增加,锁竞争可能会导致插入性能下降。
- 写放大: TiDB 使用 Raft 协议来保证数据的一致性,这可能会导致写放大问题。当多个插入操作被组合成一批提交时,数据可能需要在不同的副本之间进行复制,从而导致写放大,降低性能。
- 统计信息更新: TiDB 使用统计信息来优化查询计划。随着数据量的增加,统计信息可能会变得过时,导致查询计划选择不够优化,进而影响插入性能。
- 磁盘IO瓶颈: 随着数据量的增加,磁盘IO成为性能的一个瓶颈。插入操作需要写入磁盘,如果磁盘性能不足,插入速度就会变慢。
- 写缓冲: TiDB 使用了写缓冲区来缓存待写入的数据,从而提高写入性能。但是,当写缓冲区不足时,插入操作可能会受到限制,导致插入变慢。
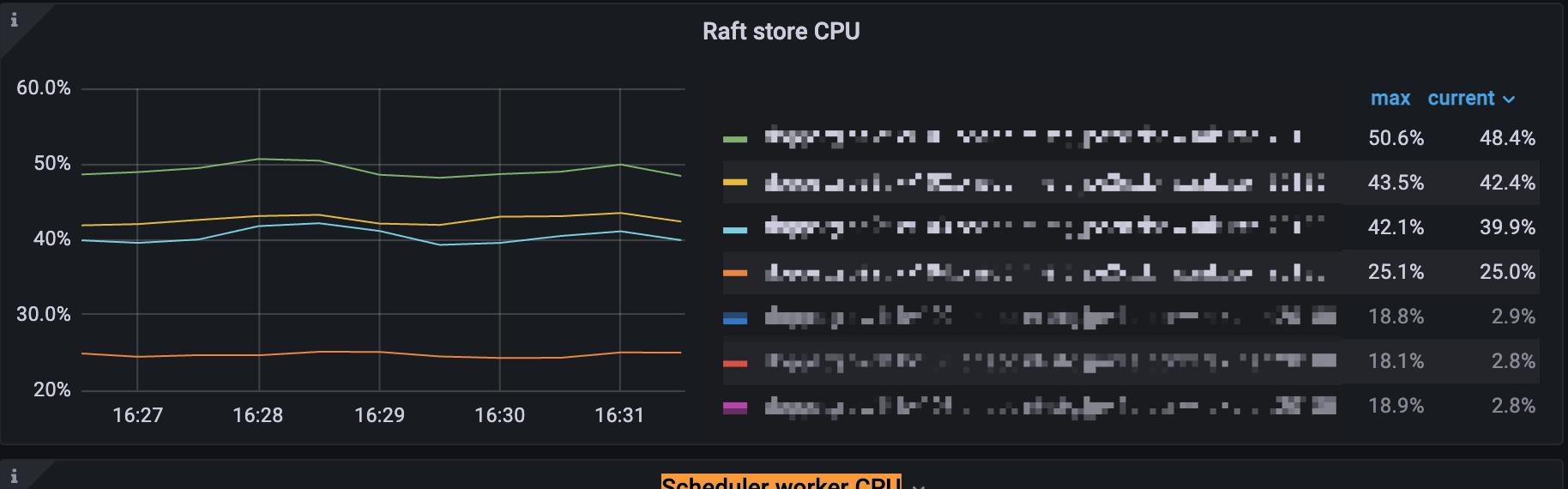
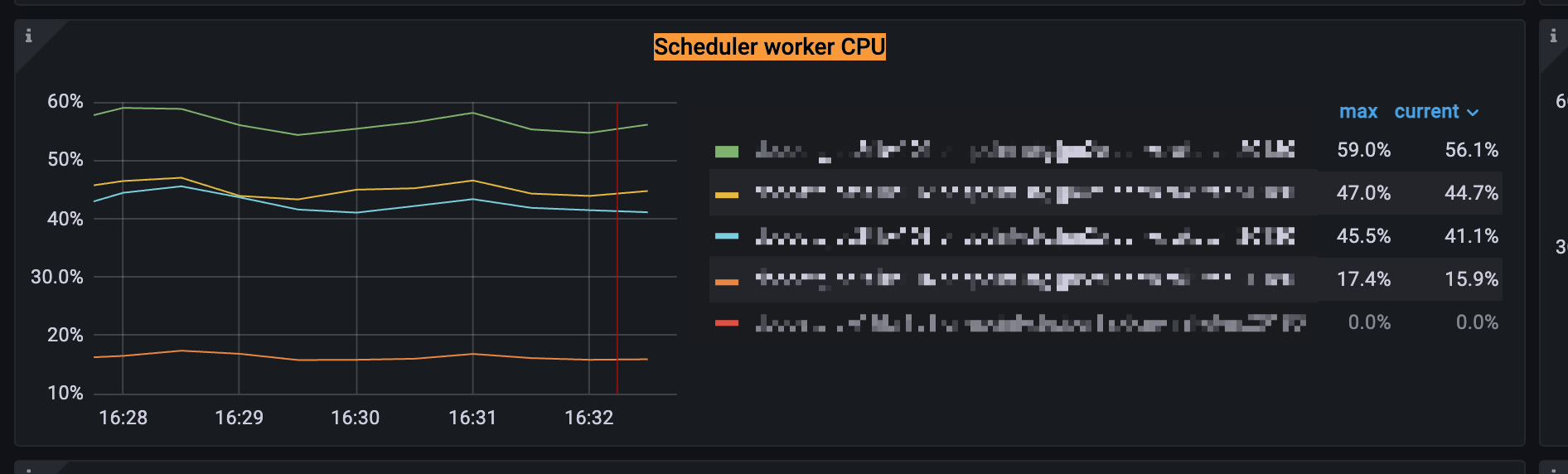
在dashboard里面查看一下热力图,看看是不是写热点了,如果是就用split region来分割region
之前有个时间戳的索引,改成一个复合索引了,现在在观察